Google has announced a technology called 'multi-token prediction' that uses small AIs to generate drafts, dramatically speeding up large AIs.

Google has announced ' Multi-token-prediction,' a technology that speeds up processing for large AI systems by using small AIs to perform speculative predictions.
Multi-token-prediction in Gemma 4
Accelerate Gemma 4 with multi-token prediction | Google AI for Developers
https://ai.google.dev/gemma/docs/mtp/overview?hl=ja
Existing AI models require a similar level of computational processing for both complex and simple reasoning. For example, while it's easy to infer that the word following 'Even monkeys fall from trees' is 'fall,' the AI will perform as much computational processing to arrive at the word 'fall' as it would for complex reasoning.
Multi-token prediction is a technique that uses a small AI called MTP Drafter to speculatively predict the next token, and then the multiple tokens derived by MTP Drafter are validated in parallel by the production AI and incorporated. MTP Drafter is lightweight enough to predict multiple tokens by utilizing idle computing resources, and by using multi-token prediction, processing can be accelerated without compromising the quality of the final output.
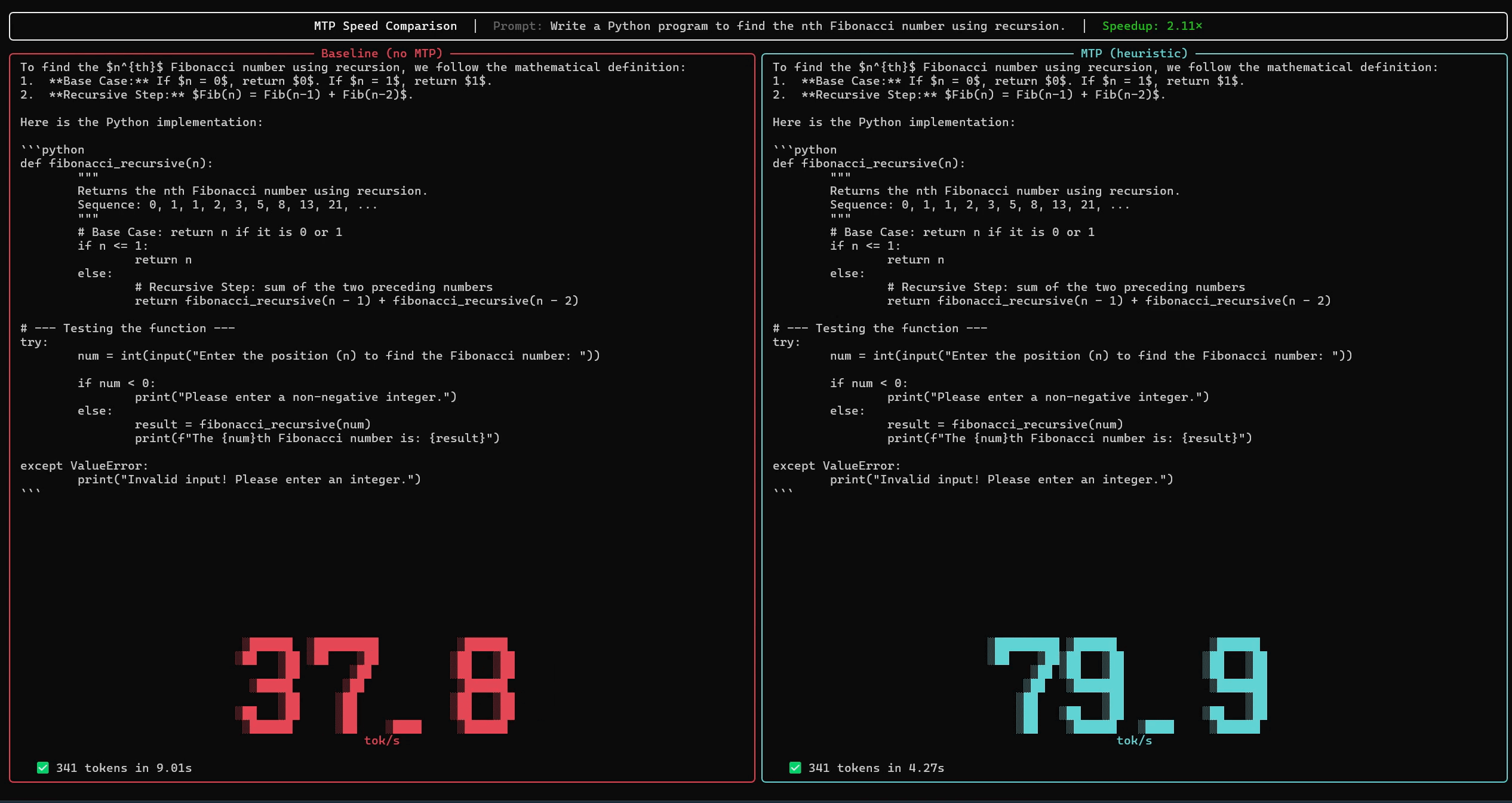
The following is a comparison of the number of tokens per second output using an NVIDIA RTX PRO 6000 with 'Gemma 4 26B without MTP Drafter (left)' and 'Gemma 4 26B with MTP Drafter (right)'. By using MTP Drafter, it is possible to double the number of tokens processed per second while maintaining output quality.
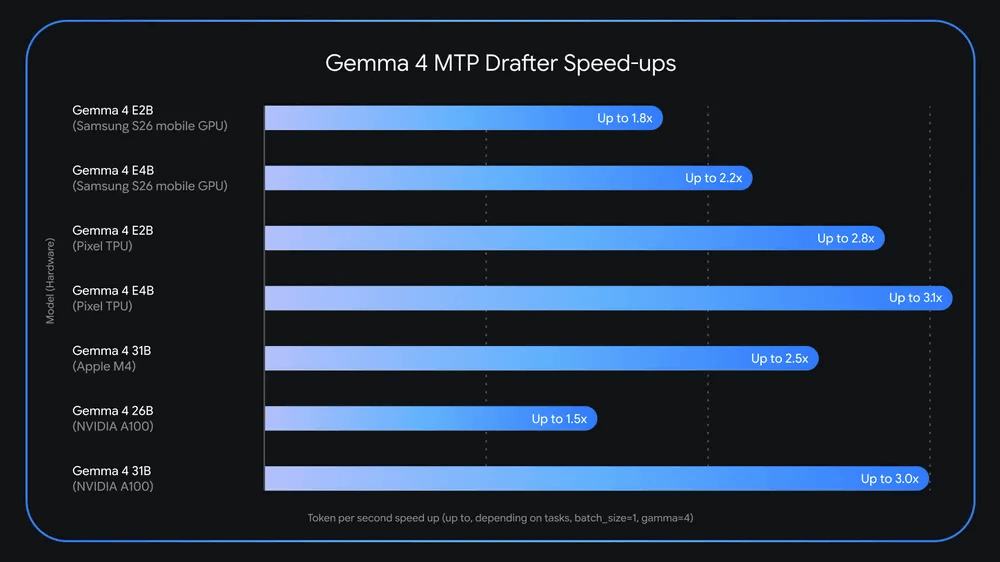
The following diagram shows the change in processing speed when using the MTP Drafter with 'Gemma 4 E2B', 'Gemma 4 E4B', 'Gemma 4 26B-A4B', and 'Gemma 4 31B'. When running Gemma 4 E4B on a Pixel TPU, using the MTP Drafter improves processing speed by 3.1 times. A 3.0x speed improvement has also been confirmed when running Gemma 4 31B on an NVIDIA A100. In other words, multi-token prediction is a useful technology for both small AI running on smartphones and large AI running in data centers.
Google has released MTP drafters designed for four AI models: 'Gemma 4 E2B,' 'Gemma 4 E4B,' 'Gemma 4 26B-A4B,' and 'Gemma 4 31B,' at the following link.
google/gemma-4-E2B-it-assistant · Hugging Face
https://huggingface.co/google/gemma-4-E2B-it-assistant
google/gemma-4-E4B-it-assistant · Hugging Face
https://huggingface.co/google/gemma-4-E4B-it-assistant
google/gemma-4-26B-A4B-it-assistant · Hugging Face
https://huggingface.co/google/gemma-4-26B-A4B-it-assistant
google/gemma-4-31B-it-assistant · Hugging Face
https://huggingface.co/google/gemma-4-31B-it-assistant
Related Posts:








in AI, Posted by log1o_hf