Google's new algorithm 'TurboQuant' makes AI 8 times faster and reduces memory usage to one-sixth.

On March 24, 2026, Google Research announced a new suite of compression techniques for large-scale language models and vector search engines: TurboQuant , PolarQuant , and Quantized Johnson-Lindenstrauss (QJL). The goal is to reduce memory usage, which is a major burden on AI, while also improving processing speed and search performance. Google explains that these techniques are particularly effective for LLM
TurboQuant: Redefining AI efficiency with extreme compression
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc pic.twitter.com/9SJeMqCMlN
— Google Research (@GoogleResearch) March 24, 2026
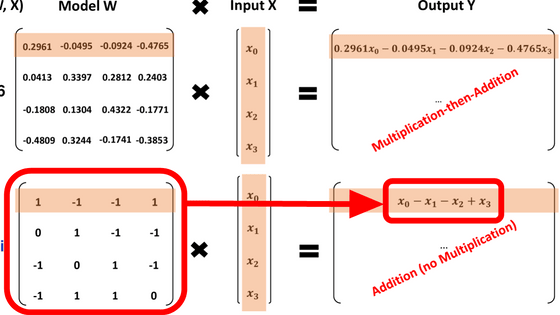
TurboQuant is a compression technique that stores high-dimensional vectors with as few bits as possible while minimizing the loss of the proximity and relationships between the original vectors. Conventional vector quantization can compress data, but it requires the separate storage of quantization constants, which incurs extra memory requirements. Google states that 'TurboQuant aims to significantly reduce model size and virtually eliminate accuracy loss while minimizing these additional costs.'
TurboQuant operates in two main steps: 'PolarQuant-based compression' and 'QJL-based correction.'
The first step involves random rotation and high-quality quantization. Google explains that random rotation simplifies the data's geometry, making it easier to apply high-quality quantization. This is not so much about changing the meaning of the data itself, but rather about changing how you view the coordinates to make them easier to compress. Hacker News , a social news site, explains it as 'bringing values that are far apart closer to other values, making the whole thing easier to pack in.'
PolarQuant, a technology for high-quality quantization, is a compression method that re-represents vectors in polar coordinates rather than the conventional orthogonal coordinates like x, y, and z. By separating vectors into polar coordinates, i.e., radius and angle, the radius represents the strength of the data, and the angle represents the direction and meaning of the data. According to Google, there are known and strongly concentrated patterns in the distribution of angles, so it becomes possible to eliminate the data normalization required in conventional methods. Google explains that the key point of PolarQuant is that it reduces the memory overhead that conventional methods had.
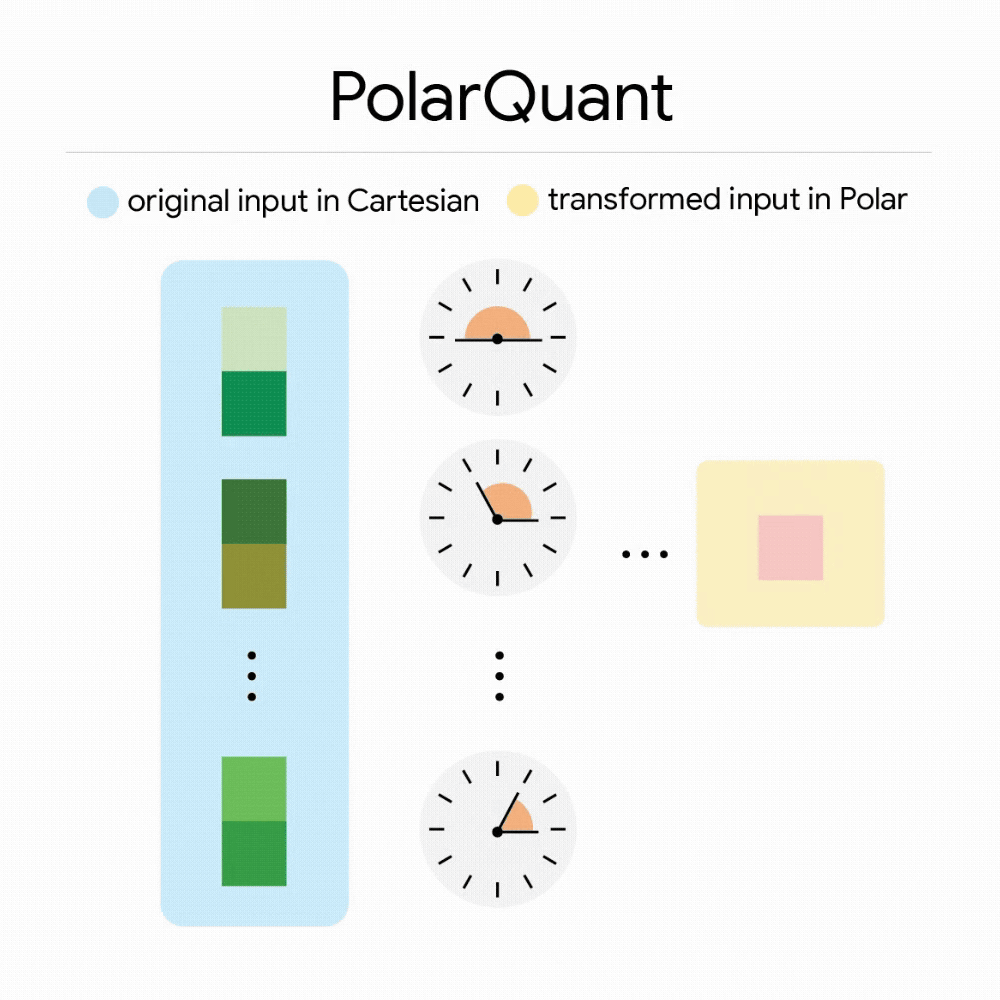
The second step is error correction using another core technology called 'QJL'. QJL stands for Quantized Johnson-Lindenstrauss, and it is a mechanism for reducing high-dimensional data to a smaller size while preserving the distances and relationships between points as much as possible.
According to Google, they first use
In experiments, quantizing the LLM's KV cache to 3 bits required no training or further fine-tuning, maintaining accuracy and performing faster than Gemma and Mistral. Google also reported that in benchmark tests designed to verify whether the model could find specific small pieces of information buried within a massive amount of text, it achieved at least a 6x reduction in memory usage while maintaining full downstream performance.
AI engineer Prince Canuma reported on X (formerly Twitter) that he implemented Google's TurboQuant using the Apple MLX machine learning framework for Apple Silicon and benchmarked it using Qwen3.5-35B-A3B. He found that each quantization level achieved 6 perfect matches out of 6, the KV cache was 4.9 times smaller with TurboQuant 2.5-bit and 3.8 times smaller with 3.5-bit, and there was no decrease in accuracy compared to non-quantized versions.
Just implemented Google's TurboQuant in MLX and the results are wild!
— Prince Canuma (@Prince_Canuma) March 25, 2026
Needle-in-a-haystack using Qwen3.5-35B-A3B across 8.5K, 32.7K, and 64.2K context lengths:
→ 6/6 exact match at every quant level
→ TurboQuant 2.5-bit: 4.9x smaller KV cache
→ TurboQuant 3.5-bit: 3.8x… https://t.co/aLxRJIhB1D pic.twitter.com/drVrkL7Pw4
The graph below shows the results of calculating attention logits using TurboQuant on an H100 GPU. Google reports that 4-bit TurboQuant (yellow) is up to 8 times faster in calculating attention logits compared to 32-bit unquantized keys (blue).
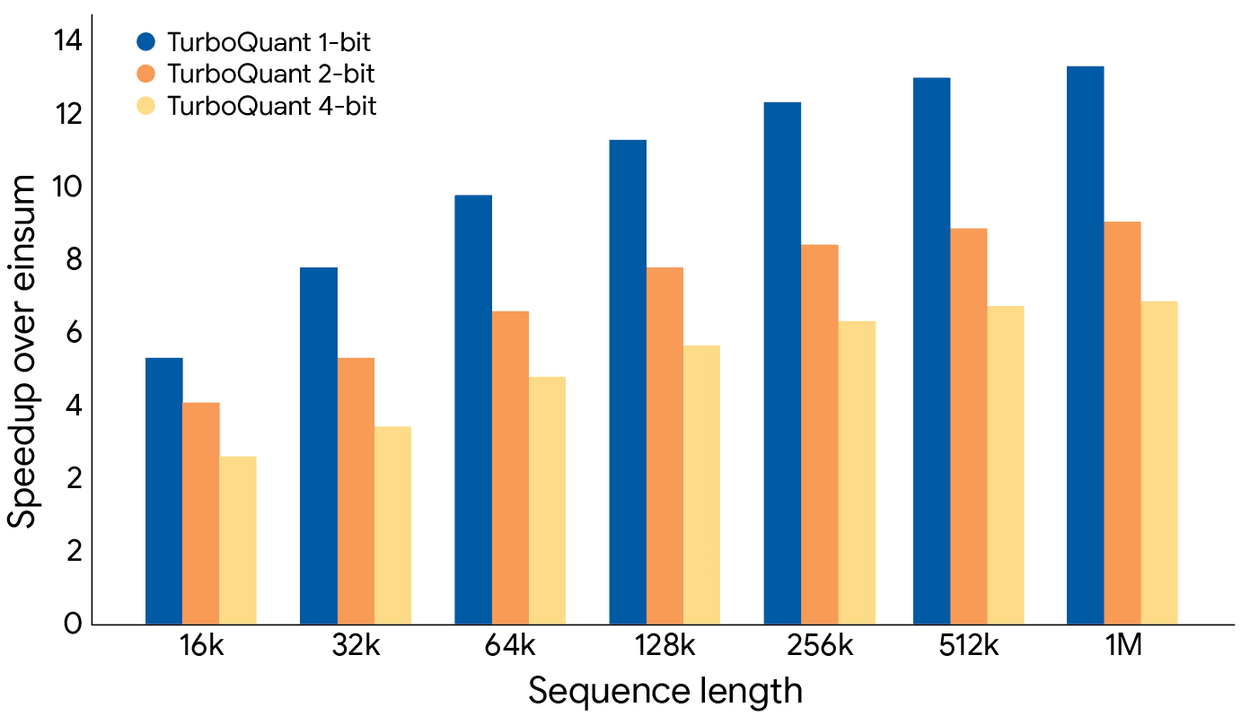
In vector searches, TurboQuant has been shown to exhibit higher regression rates than existing quantization methods.
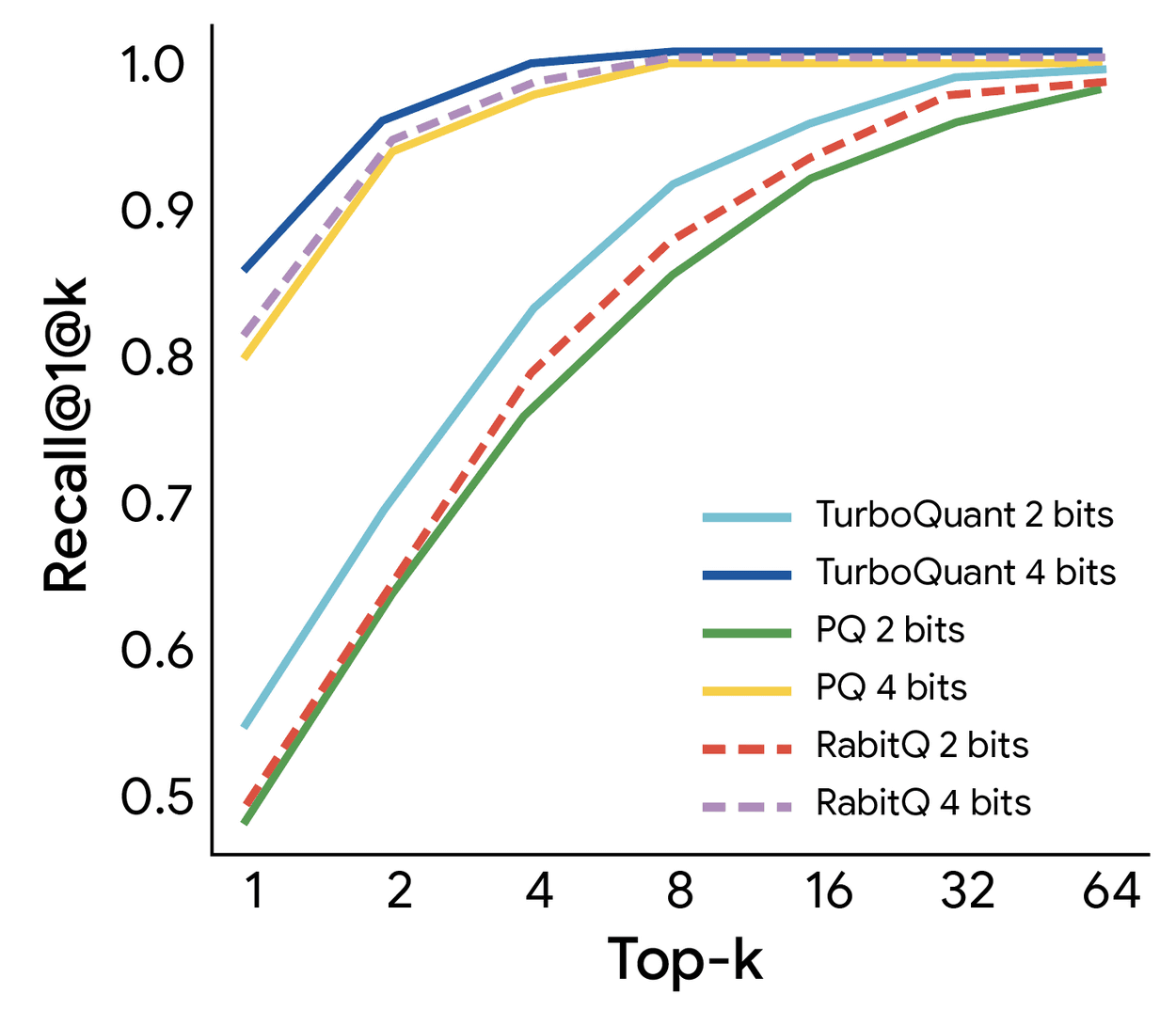
Google positions TurboQuant, PolarQuant, and QJL not merely as implementation gimmicks, but as fundamental algorithmic contributions with strong theoretical backing. They state that these not only work well in real-world applications but also operate with efficiency close to the theoretical lower bound, making them reliable even in large-scale and critical systems. One application is resolving the KV cache bottleneck that plagues models like Gemini, but more importantly, Google emphasizes that as search shifts from simple keyword matching to semantic understanding-based search, these technologies will serve as foundational techniques for handling massive vector sets with low memory and high accuracy.
Related Posts: