'TurboQuant: A First-Principles Walkthrough' is a website that provides an interactive diagram explaining how 'TurboQuant' works to run AI with a fraction of the data volume.
In March 2026, Google Research announced ' TurboQuant ' as one of a new suite of compression technologies for large-scale language models and vector search engines. To visually understand what TurboQuant is, which aims to reduce memory usage—a major burden on AI—while also improving processing speed and search performance, a website called ' TurboQuant: A First-Principles Walkthrough ' has been released.
TurboQuant: A First-Principles Walkthrough
The following article summarizes what TurboQuant, announced by Google Research, is.
Google's new algorithm 'TurboQuant' makes AI 8 times faster and reduces memory usage to one-sixth - GIGAZINE

What's great about 'TurboQuant: A First-Principles Walkthrough' is that instead of immediately explaining TurboQuant with mathematical formulas, it guides you through the basics like vectors, dot products, quantization, and rotation, using interactive diagrams on the screen to help you understand it step by step. The graphs on the site are live and the values are calculated in the browser, so readers can visually follow 'why that process is necessary' by using sliders and drag operations.
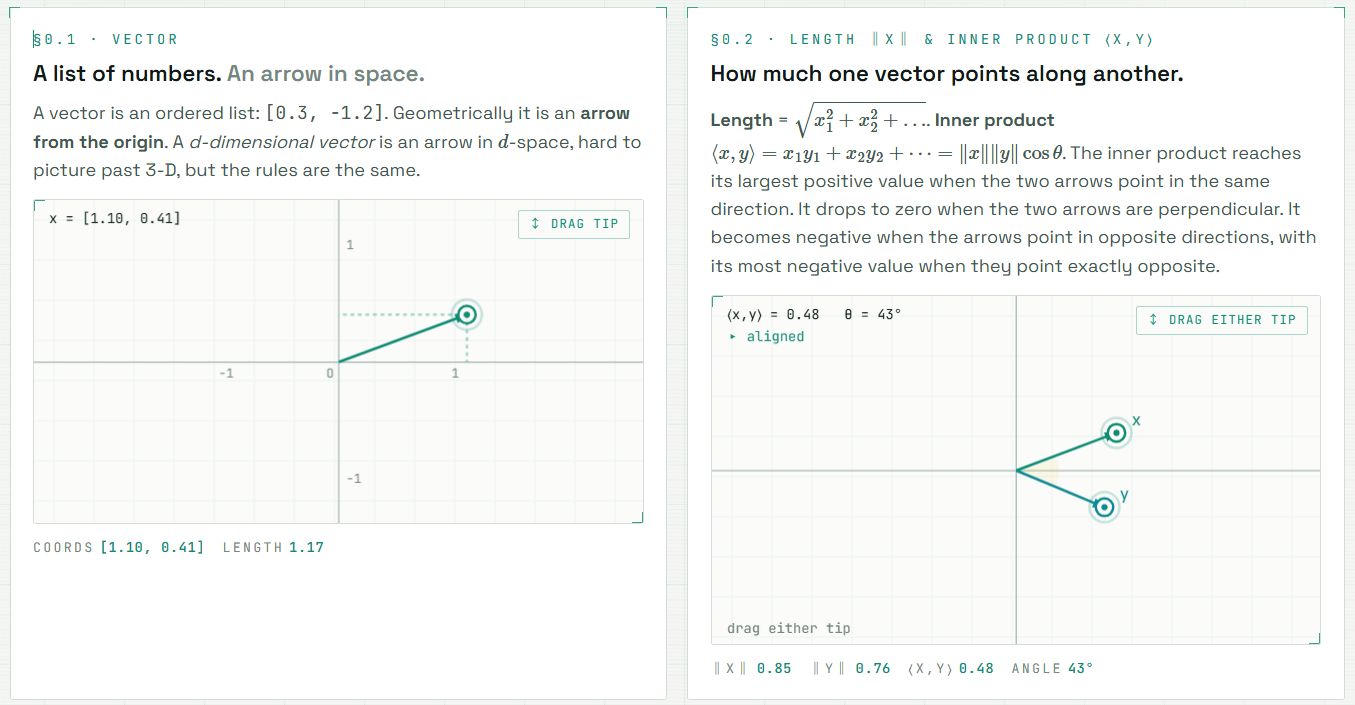
For example, the following visualizes the basic knowledge that 'a vector is a list of numbers and an arrow in space,' and what the dot product of vectors is.
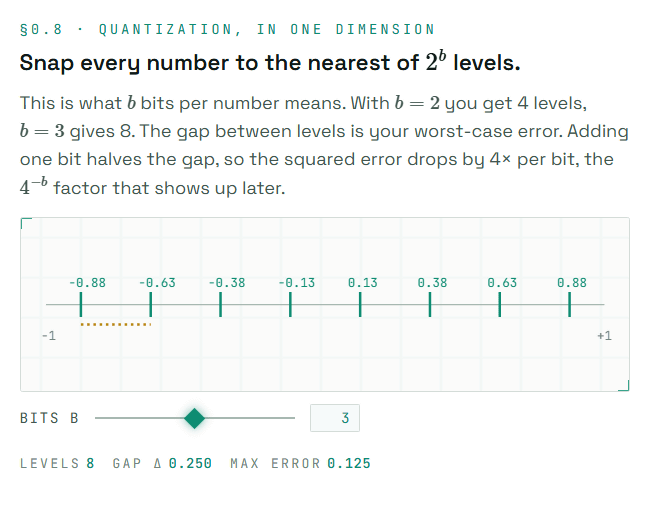
In simple terms, quantization is the process of rounding small numerical values to a few representative values. For example, if you represent a single number with 2 bits, there are only four possible values. While this significantly reduces the number of bits, it introduces an error between the original value and the rounded value. The website uses diagrams to show which level a number is drawn to, visually explaining what 'reducing the number of bits' actually entails.
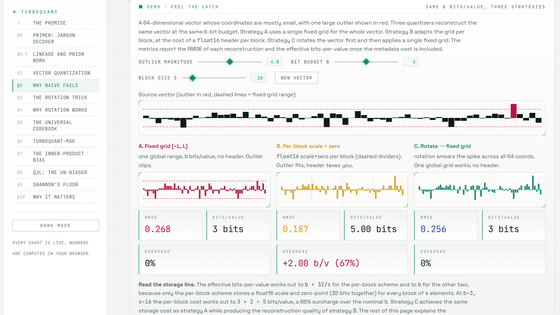
However, simply rounding the values may not always work. AI model vectors can contain 'outliers,' where some coordinates are extremely large. Rounding the values within a fixed range can either eliminate these outliers or, conversely, make the representation of small values coarse by accommodating the outliers.
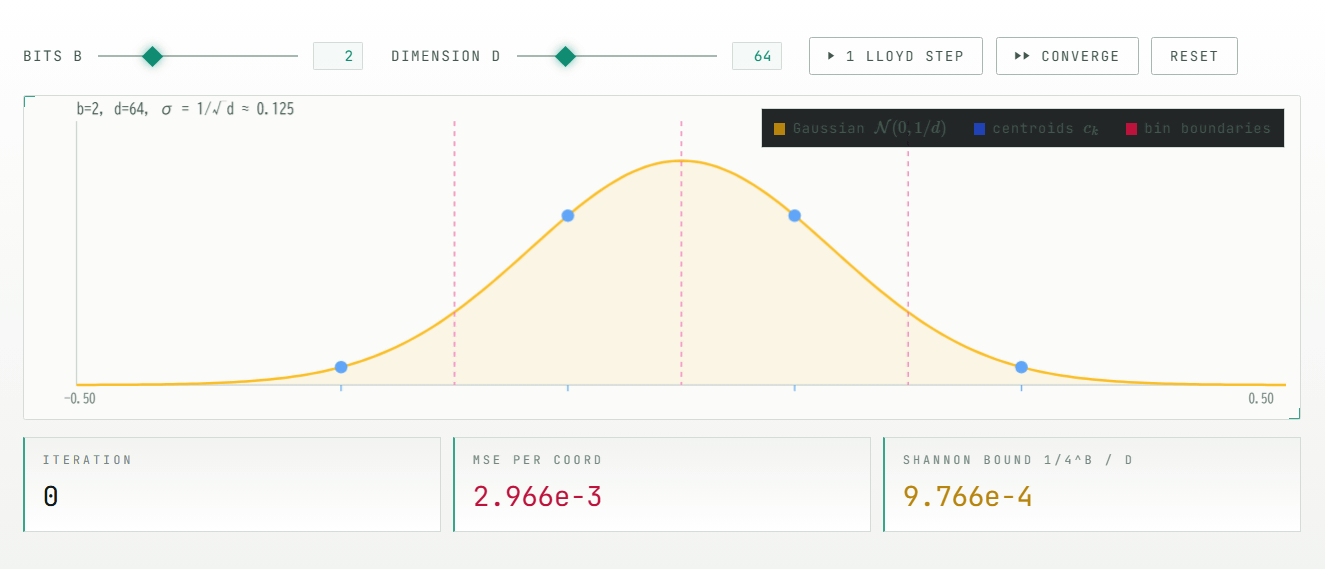
Conventional practical quantization methods avoid this problem by additionally storing scale and zero points for each short block. However, storing this additional information increases the actual memory usage beyond the nominal number of bits. The site shows an example where, even though you intend to store data in 3 bits, the effective amount of memory used becomes 4-5 bits when including the additional information for each block.
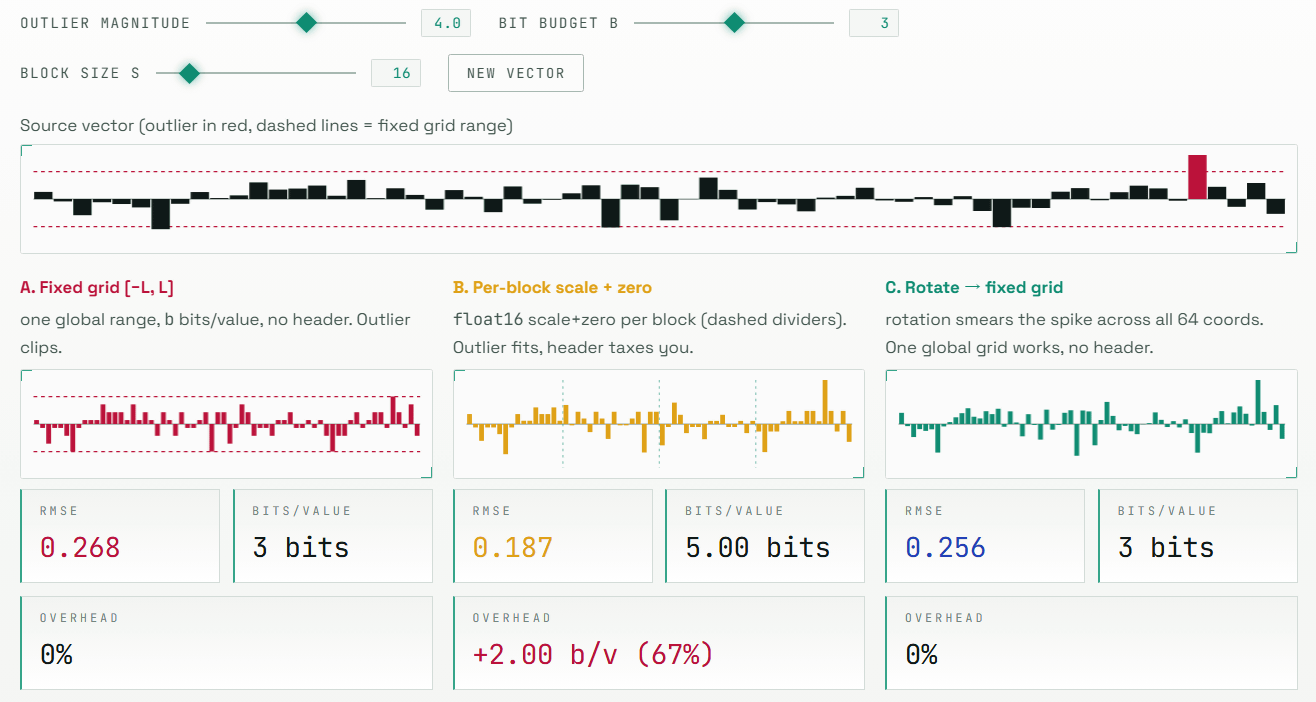
The core idea of TurboQuant is to randomly rotate vectors before rounding the numbers. This rotation doesn't destroy the lengths of the vectors or the relationships between them; it simply changes how we view space, so the geometric meaning of the vectors is preserved. On the other hand, large values that were concentrated in one coordinate are distributed across many coordinates after the rotation. In other words, difficult-to-handle outliers are smoothed out into a form that is easier to quantize before being compressed.
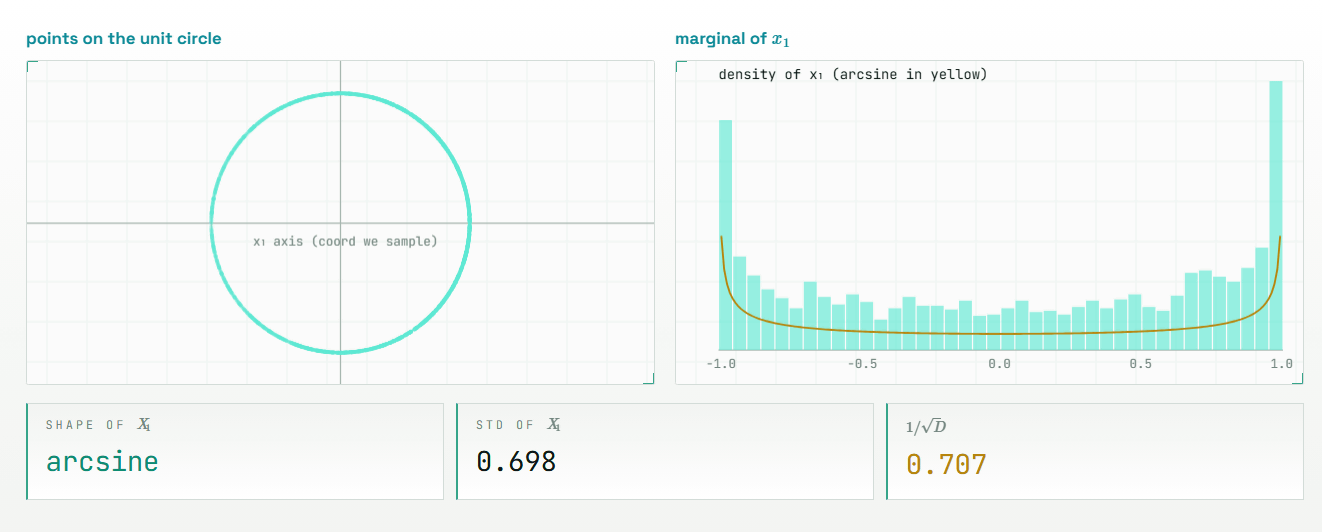
Because the coordinates after rotation will have a similar distribution, TurboQuant does not require saving scales or zero points for each input. This is because each coordinate can be rounded using a pre-created common codebook, i.e., a table of representative values. This 'usability without additional metadata' is a major difference from conventional block-by-block quantization methods.
Furthermore, there's the problem that the 'inner product,' which is crucial for attention and vector searching, is underestimated, not just simply getting closer to the original vector. In quantization that reduces the MSE (
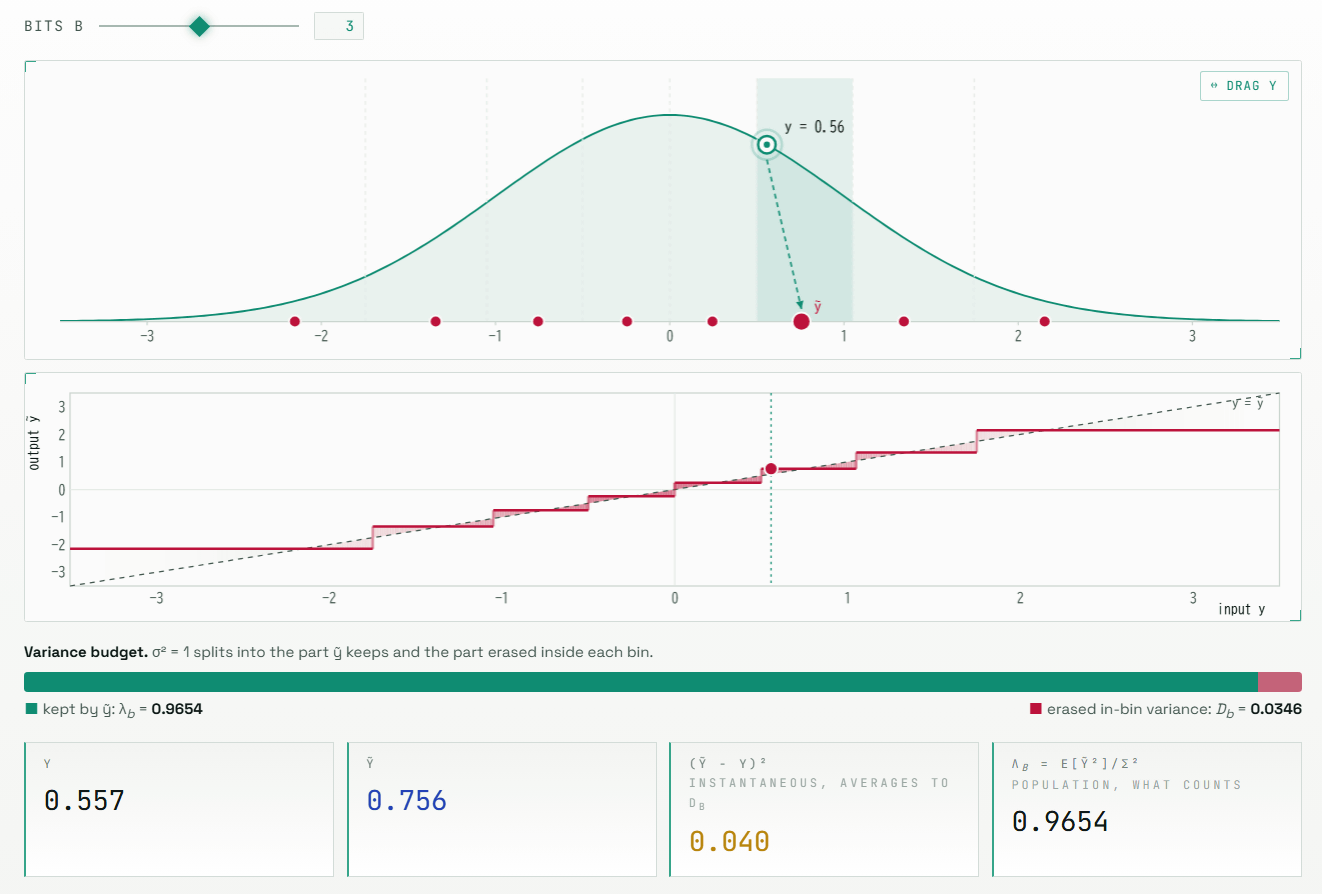
'TurboQuant: A First-Principles Walkthrough' guides you through questions such as 'Where does ordinary quantization fail?', 'Why is rotation effective?', and 'Why is inner product correction necessary?'. You can slowly understand the compression of high-dimensional vectors, which is difficult to grasp from papers and formulas alone, by experiencing it with moving diagrams.
Related Posts:




in AI, Web Application, Posted by log1i_yk