Google has announced its 8th generation of AI processing chips, the TPU 8t, which is specialized for training, and the TPU 8i, which is specialized for inference, with twice the performance per watt.

Google has developed its own processors called '
Two chips for the agentic era
https://blog.google/innovation-and-ai/infrastructure-and-cloud/google-cloud/eighth-generation-tpu-agentic-era/
Below are actual photos of the TPU 8i (left) and TPU 8t (right) posted by CEO Sundar Pichai. A key feature of the 8th generation TPU is that it is designed to be divided into the TPU 8t, which is specialized for training, and the TPU 8i, which is specialized for inference.

The TPU 8t can house 9600 chips in a single pod for parallel execution. By connecting 9600 TPU 8ts, the computational performance in FP4 reaches 121 exaflops. Furthermore, by using the newly developed network technology '
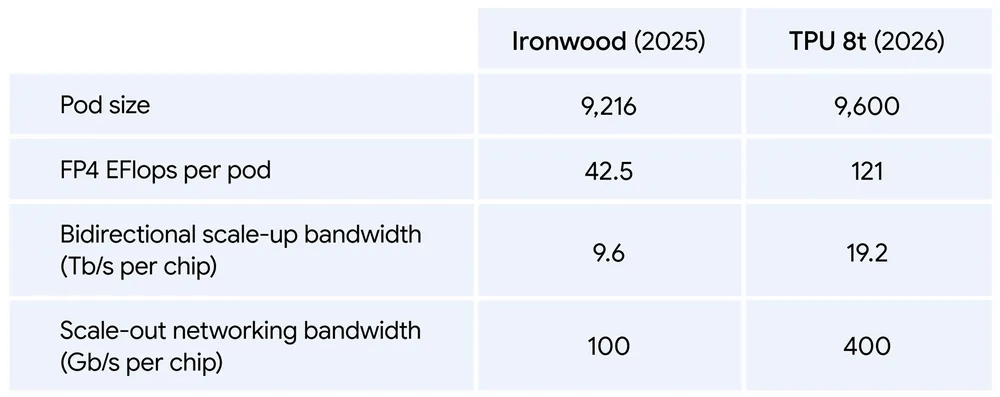
Training large-scale AI models takes several months, and even a 1% increase in downtime due to hardware failures or restarts can result in several days of lost time. The TPU 8t also boasts significant reliability improvements across tens of thousands of units, with a goodput
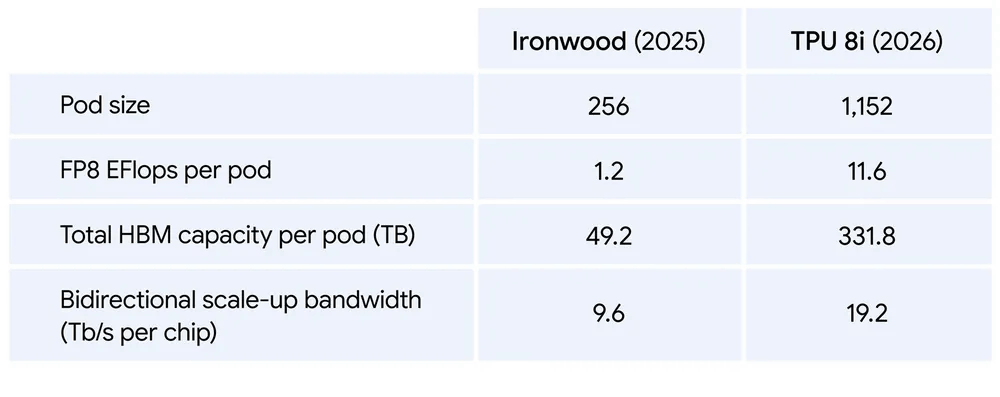
The TPU 8i is an inference-focused chip equipped with 288GB of high-bandwidth memory (HBM) and 384MB of SRAM. Up to 1152 TPU 8i units can be housed in a single pod, achieving a computational performance of 11.6 exaflops per pod in FP8 precision. The TPU 8i is designed to reduce latency in inference workloads and enables low-latency execution of MoE models by doubling the interconnect bandwidth to 19.2TB/s.
The TPU 8t and TPU 8i support Google Cloud's 4th generation liquid cooling technology, resulting in optimized energy efficiency. This doubles the processing power per watt compared to the previous generation

The TPU 8t and TPU 8i are expected to be generally available in the second half of 2026.
Related Posts:







