Introducing the cost-effective AI model 'Qwen3-Next,' which is 10 times faster than previous models and achieves the same or better performance.

An AI research team at Alibaba, a major Chinese technology company, has developed a low-cost, high-performance AI model called ' Qwen3-Next ' and released it for free. Qwen3-Next was trained at less than one-tenth the cost of previous models, and is capable of inference processing more than ten times faster when there are a large number of input tokens. Despite this, its performance is said to be equal to or better than previous models, and in some tests it even outperforms Google's Gemini-2.5-Flash-Thinking.
Qwen3-Next: Towards Ultimate Training & Inference Efficiency
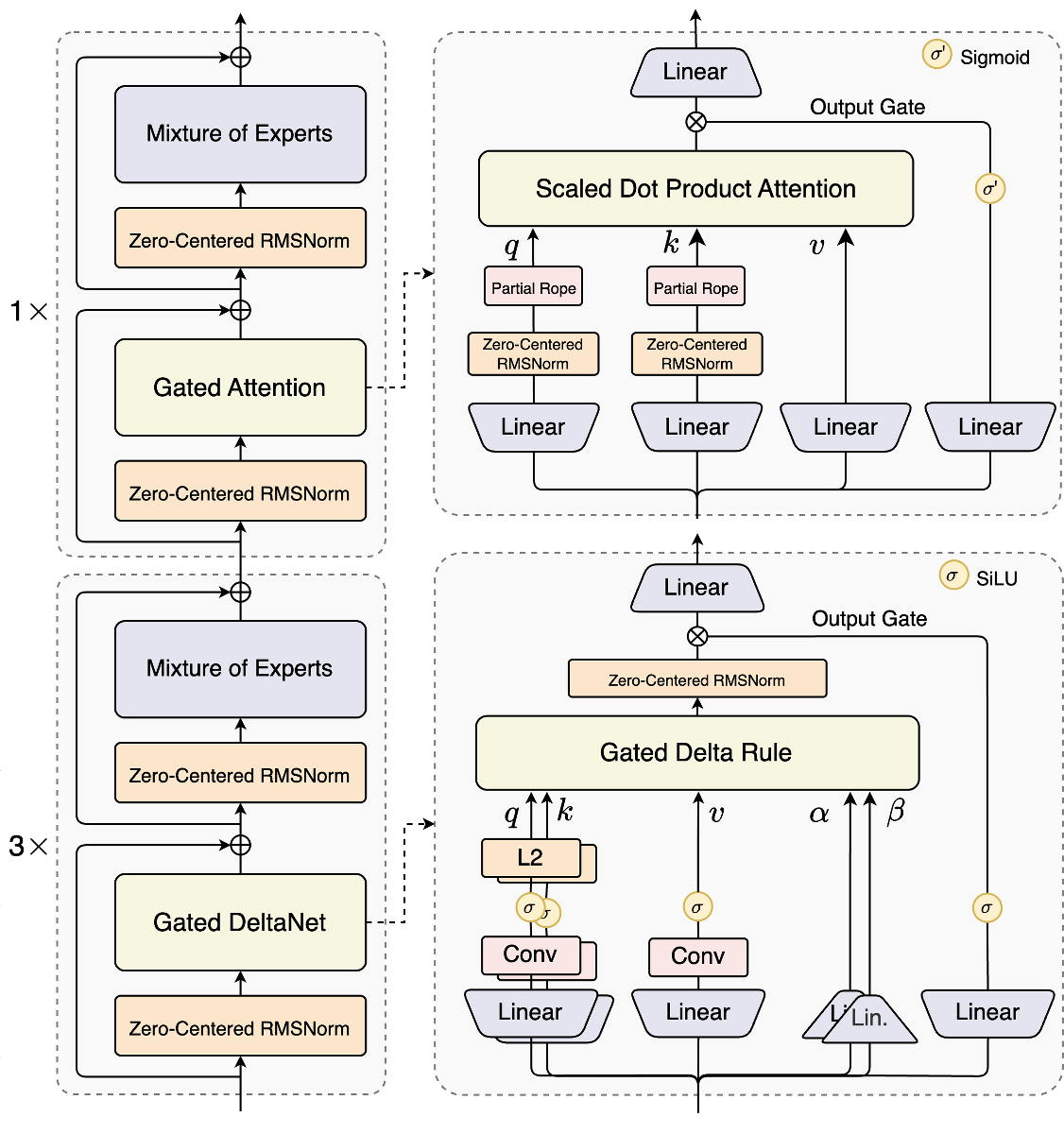
The base model of Qwen3-Next, 'Qwen3-Next-80B-A3B-Base,' is a model that uses a Mixture of Experts (MoE) architecture that incorporates multiple expert models. Unlike conventional training methods, it uses Gated DeltaNet and Gated Attention in a 3:1 ratio, achieving both high performance and low training costs.
Qwen3-Next-80B-A3B-Base can be trained 10.7 times faster than
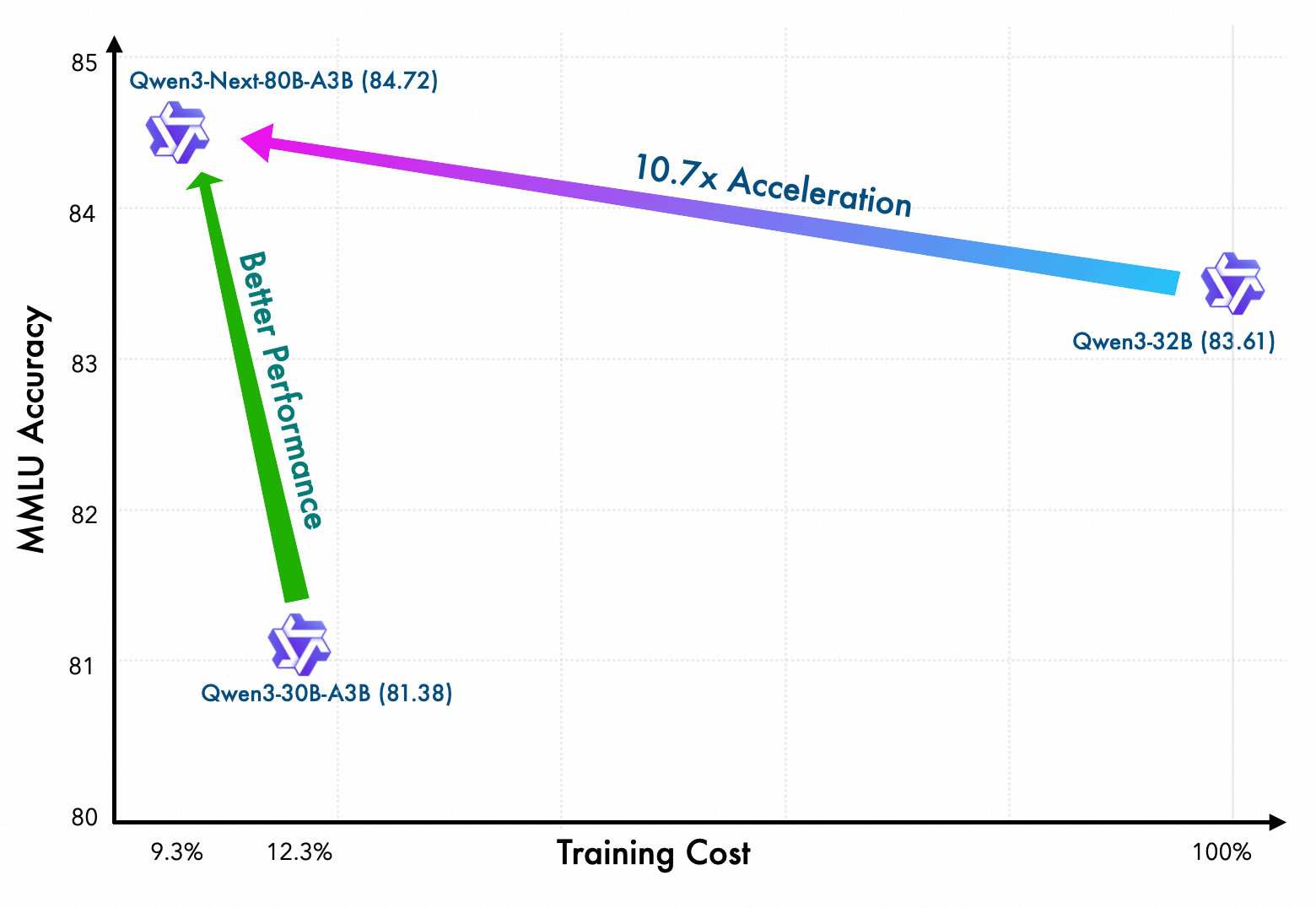
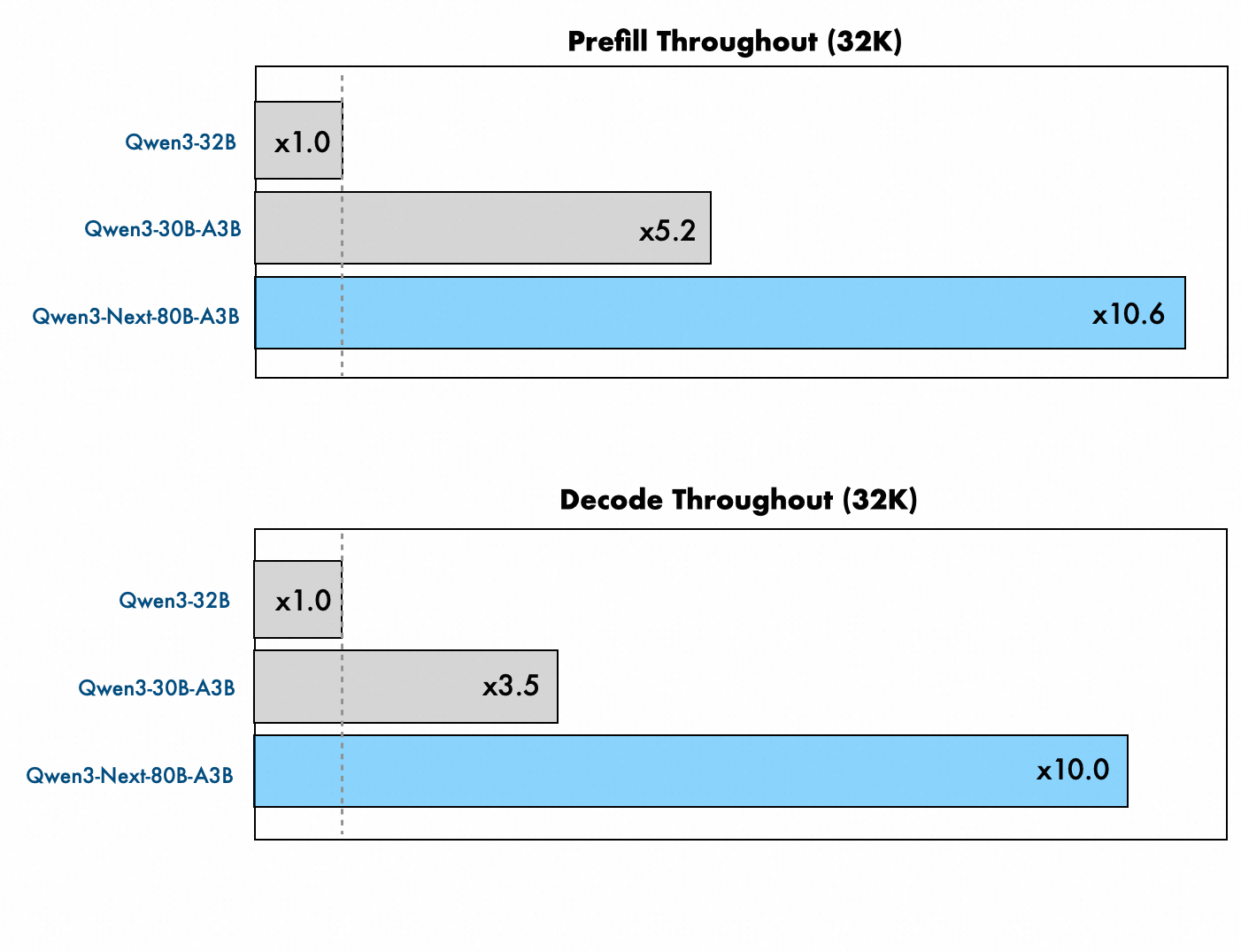
Qwen3-Next-80B-A3B-Base is an 80 billion parameter model containing 512 expert models, but only up to 3 billion parameters are active during actual inference processing. Its processing speed is significantly improved compared to previous models: for an input of 32,000 tokens, the speed up to outputting the first token (prefill phase) is 10.6 times faster than Qwen3-32B, and the output speed thereafter (decode phase) is 10 times faster.
Below is a graph comparing the time it takes to output the first token for each number of input tokens in the three models 'Qwen3-32B (white)', 'Qwen3-30B-A3B (green)', and 'Qwen3-Next-80B-A3B-Base (purple)'. The superiority of Qwen3-Next-80B-A3B-Base does not decline even when the number of input tokens increases.
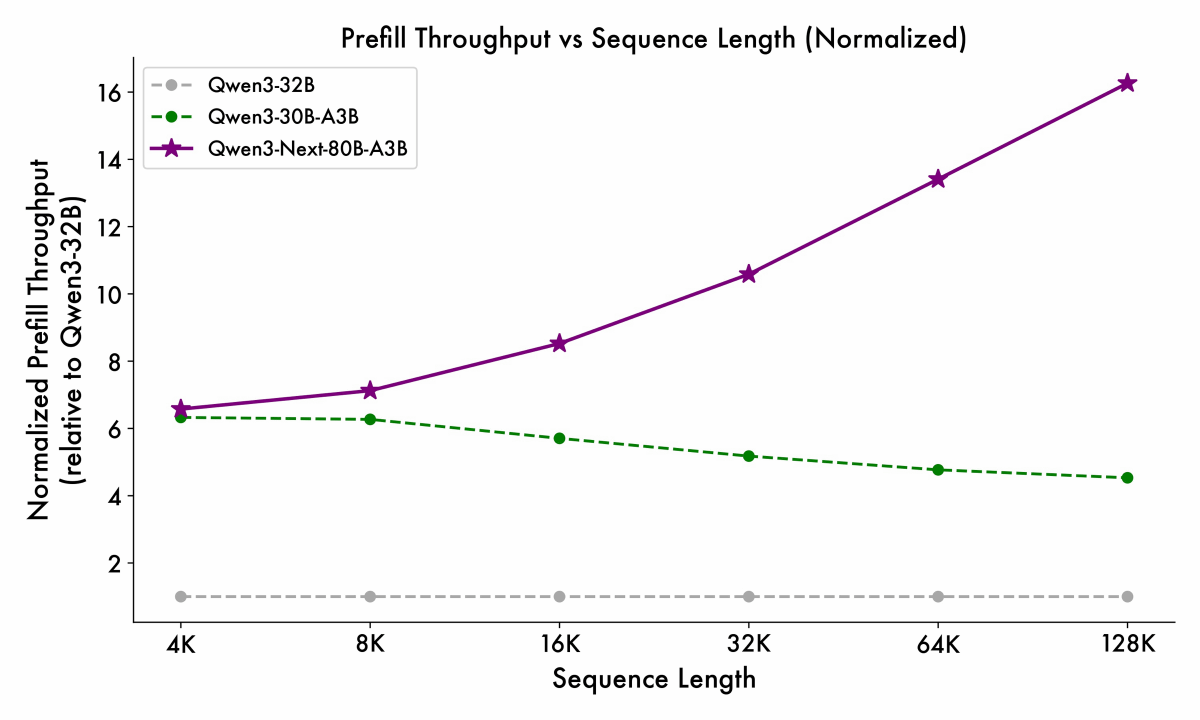
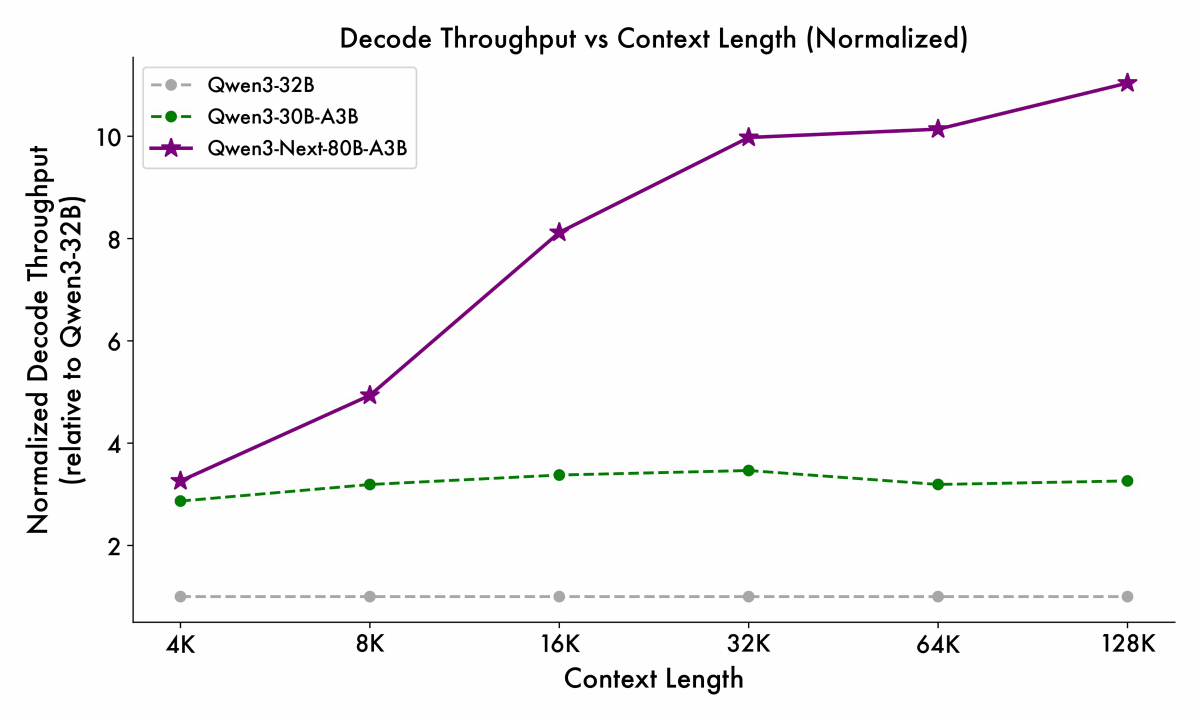
Similarly, in the decode phase, high-speed processing is possible even when there are many input tokens.
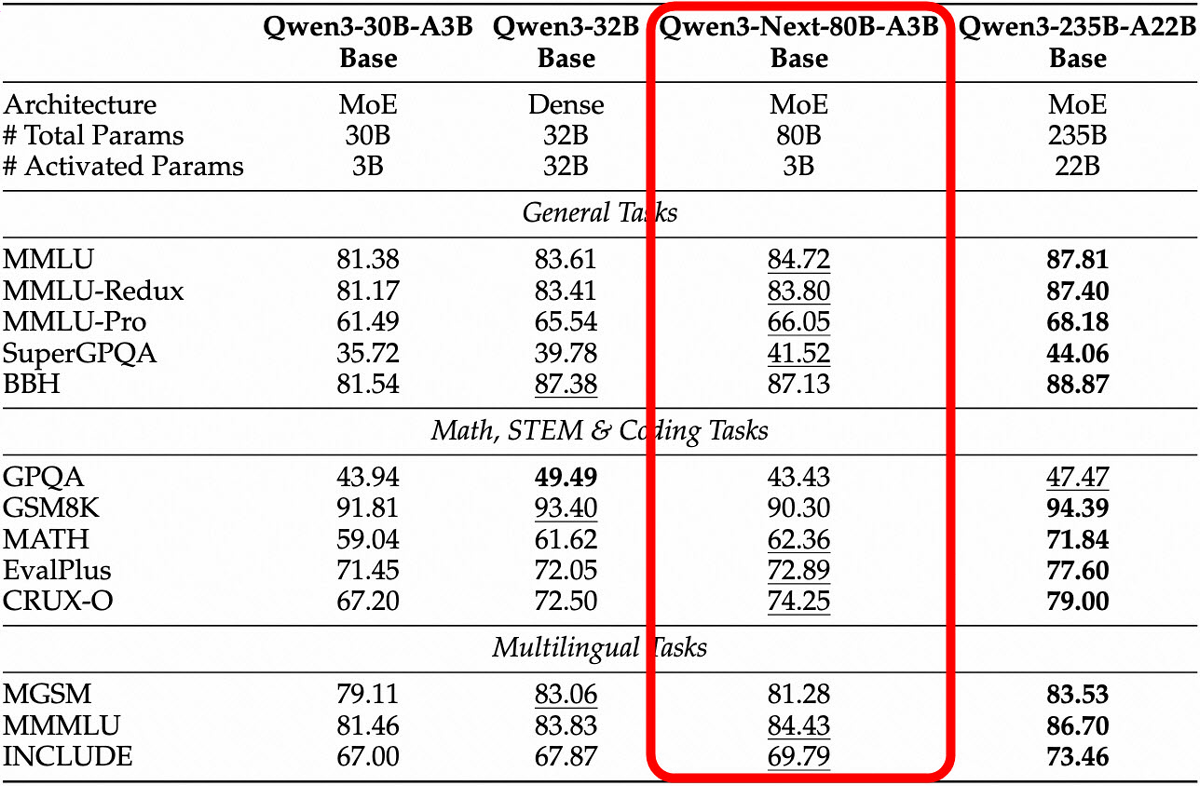
The table below summarizes the results of various benchmarks for the Qwen3-Next-80B-A3B-Base. Despite being low-cost and fast, the Qwen3-Next-80B-A3B-Base achieved scores equal to or higher than those of older models.
The development team has made some fine-tuning changes to Qwen3-Next-80B-A3B-Base and has released ' Qwen3-Next-80B-A3B-Instruct ' and ' Qwen3-Next-80B-A3B-Thinking ' for free at the links below.
Qwen3-Next - a Qwen Collection
Below is a graph showing the performance of Qwen3-Next-80B-A3B-Instruct (red).
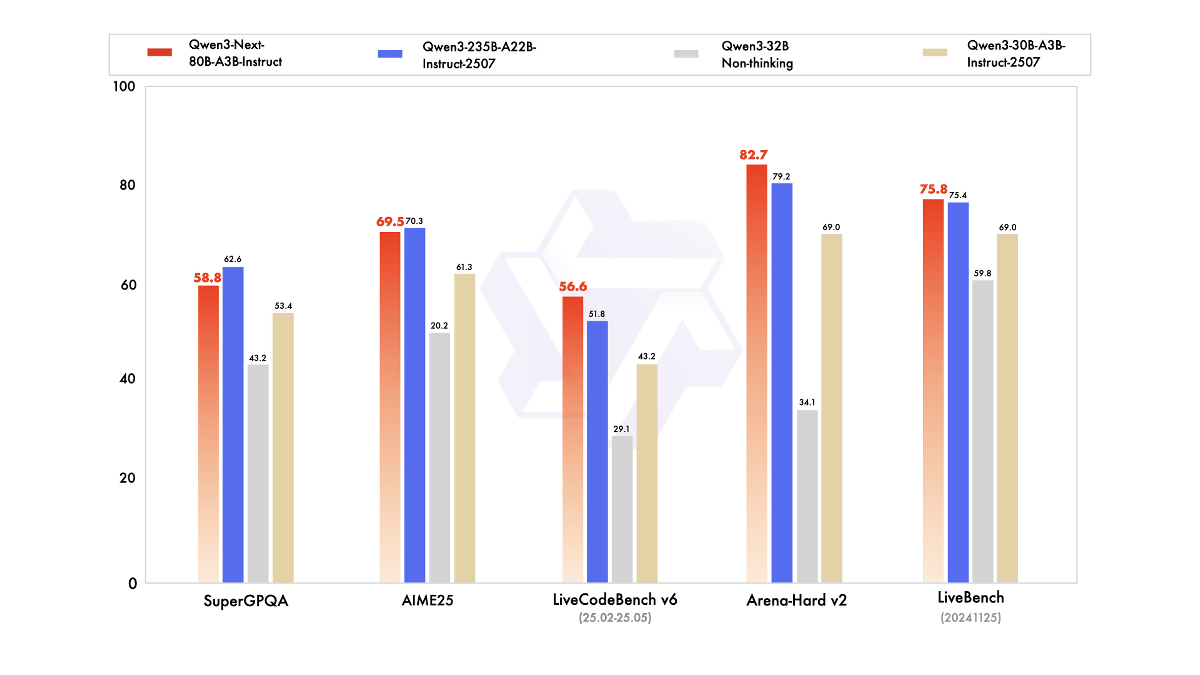
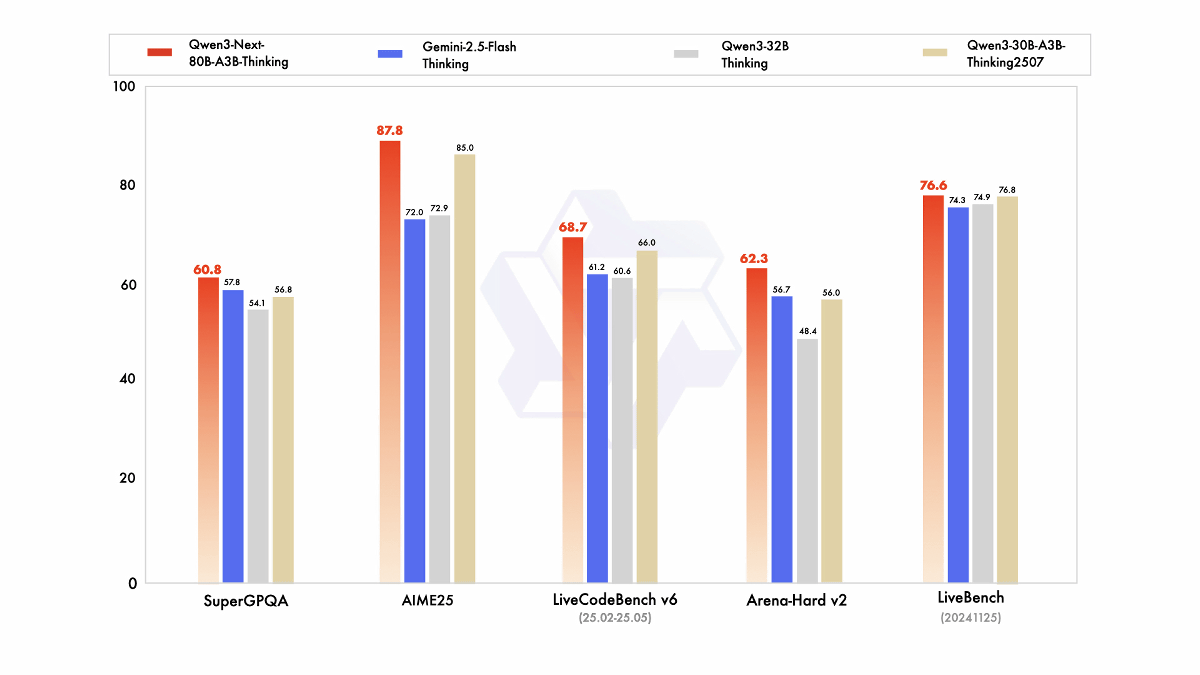
The inference model, Qwen3-Next-80B-A3B-Thinking (red), outperforms older models in all tests, and according to the development team, it even outperforms Google's Gemini-2.5-Flash-Thinking in several benchmark tests.
The development team is committed to improving the architecture for the upcoming Qwen 3.5 release.
Related Posts:







