Huawei releases 'Pangu Pro MoE 72B', a language model trained in China's AI ecosystem, and open-sources inference technology

Huawei released the large-scale language model ' Pangu Pro MoE 72B ' with 72 billion parameters on Monday, June 30, 2025. Pangu Pro MoE 72B is trained using Huawei's Ascend ecosystem and is said to have the highest performance among models with less than 100 billion parameters. In addition, Huawei has open-sourced several technologies related to the development of AI models.
Ascend Tribe - GitCode
Item title - pangu-pro-moe-model: [Model weight] 盘古 Pro MoE (72B-A16B): Ascending primitive division mixed house model - GitCode
https://gitcode.com/ascend-tribe/pangu-pro-moe-model
[2505.21411] Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
https://arxiv.org/abs/2505.21411
The development of high-performance AI requires a large-scale AI infrastructure equipped with a large number of GPUs, but the United States strictly restricts the shipment of high-performance semiconductors to China, making it difficult for China to obtain AI chips such as NVIDIA. Meanwhile, Huawei has succeeded in developing the 'Ascend' series, which has performance comparable to NVIDIA AI chips, making it realistic to build an AI development system that is not dependent on American companies.
Huawei will reportedly mass-ship the 'Ascend 910C,' a chip that rivals NVIDIA's AI chip 'H100,' to Chinese customers as early as May - GIGAZINE

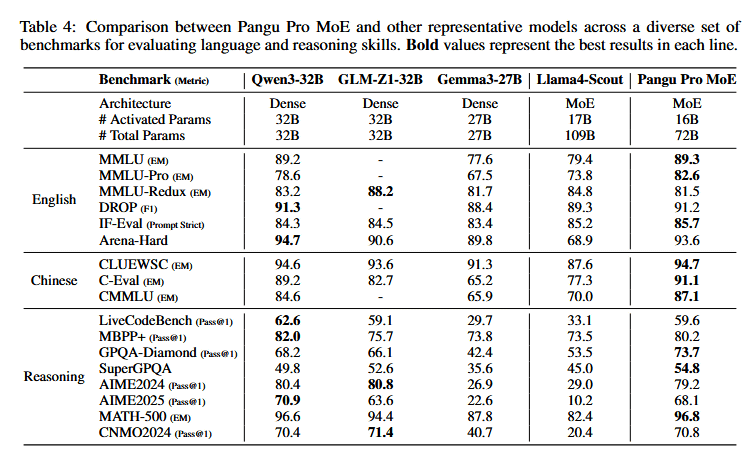
Then, on June 30, 2025, Huawei released the large-scale language model Pangu Pro MoE 72B, which was trained using the Ascend ecosystem. Below are the results of comparing various benchmark results of Pangu Pro MoE 72B with 'Qwen3-32B', 'GLM-Z1-32B', 'Gemma3-27B', and 'Llama4-Scout'. Pangu Pro MoE 72B has recorded the highest scores in multiple benchmarks, and has also won multiple tests against Llama4-Scout, which has a large number of parameters.
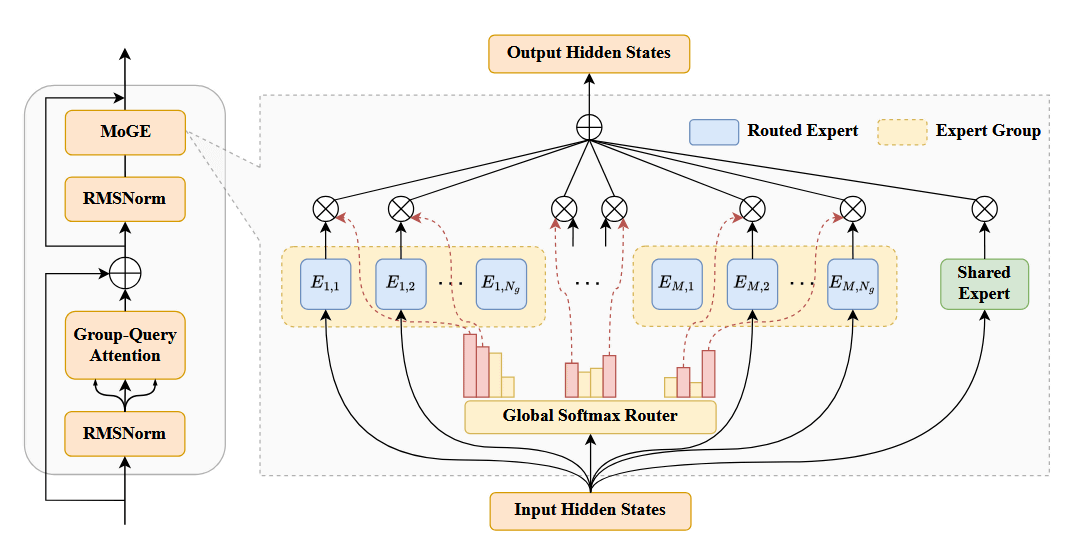
Many recent LLMs use a mechanism called 'Mixture of Experts (MoE)' that combines multiple expert models. However, MoE has the problem that 'some expert models are frequently activated, which causes inefficiency during parallel execution.' To solve this problem, Huawei developed 'Mixture of Grouped Experts (MoGE)', which can properly balance the workload of expert models, and applied it to the training of Pangu Pro MoE 72B. This achieved a high processing speed of 1148 tokens per second when running Pangu Pro MoE 72B on the 'Ascend 800I A2 NPU'.
The model data for the Pangu Pro MoE 72B is available at the following link.
Item title - pangu-pro-moe-model: [Model weight] 盘古 Pro MoE (72B-A16B): Ascending primitive division mixed house model - GitCode
https://gitcode.com/ascend-tribe/pangu-pro-moe-model

In addition, the various technologies used in the training of Pangu Pro MoE 72B have also been open sourced, and information on various technologies is summarized on the following page.
Ascend Tribe - GitCode
https://gitcode.com/ascend-tribe

Related Posts: