Cursor's new model, 'Composer 2.5,' is an AI agent aiming for GPT-5.5 level coding performance at a low cost.
Anysphere, the developer of the AI code editor 'Cursor,' has announced a new model for its coding agent, 'Composer 2.5.' Composer 2.5 is available on Cursor and is said to be significantly improved compared to the previous model, 'Composer 2,' in terms of its ability to continuously process long-term tasks, its ability to follow complex instructions, and its ease of collaboration with the user.
Introducing Composer 2.5 · Cursor
Composer 2.5 uses reinforcement learning, where models are given rewards based on success or failure when performing tasks, allowing them to learn desirable behaviors. Cursor has improved performance by scaling up the learning environment, creating more complex reinforcement learning environments, and introducing new learning methods. They explain that improvements have been made not only to benchmark scores, but also to behaviors that are important for real-world use, such as how the model communicates and how much effort it puts into a task.
In the published benchmarks, Composer 2.5 achieved 69.3% in Terminal-Bench 2.0, 79.8% in SWE-Bench Multilingual, and 63.2% in CursorBench 3.1. For comparison, Composer 2 scored 61.7%, 73.7%, and 52.2% respectively, showing a significant improvement, especially in CursorBench 3.1. It also achieved scores comparable to Claude Opus 4.7 and GPT-5.5.
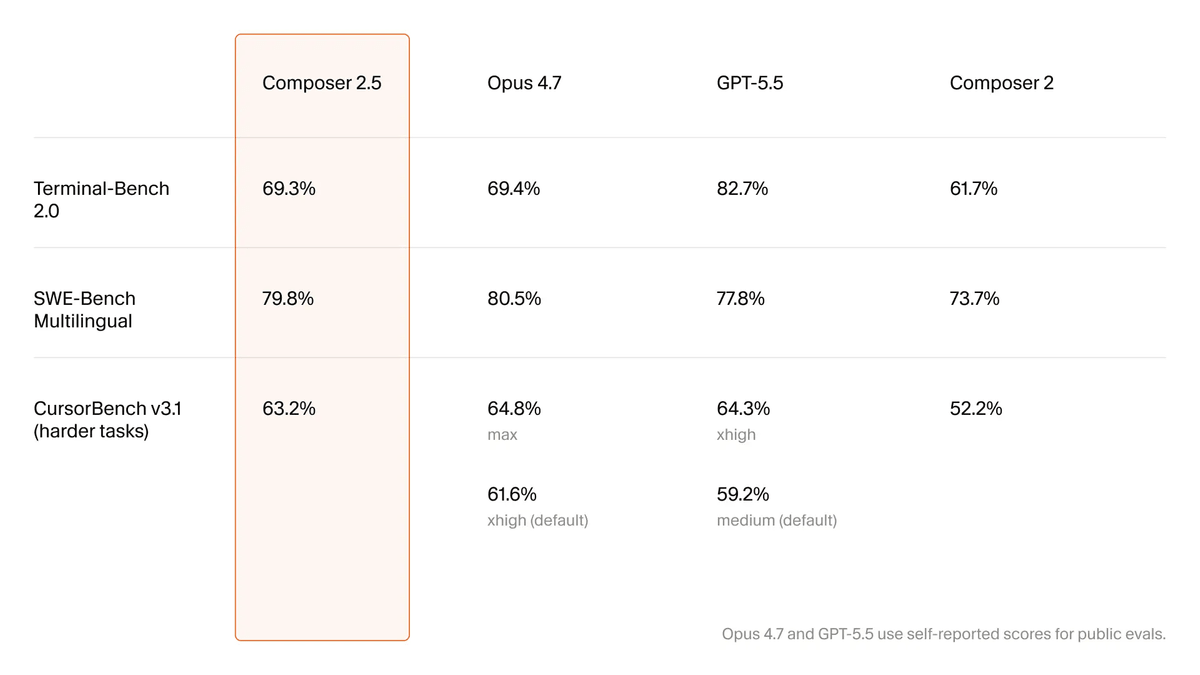
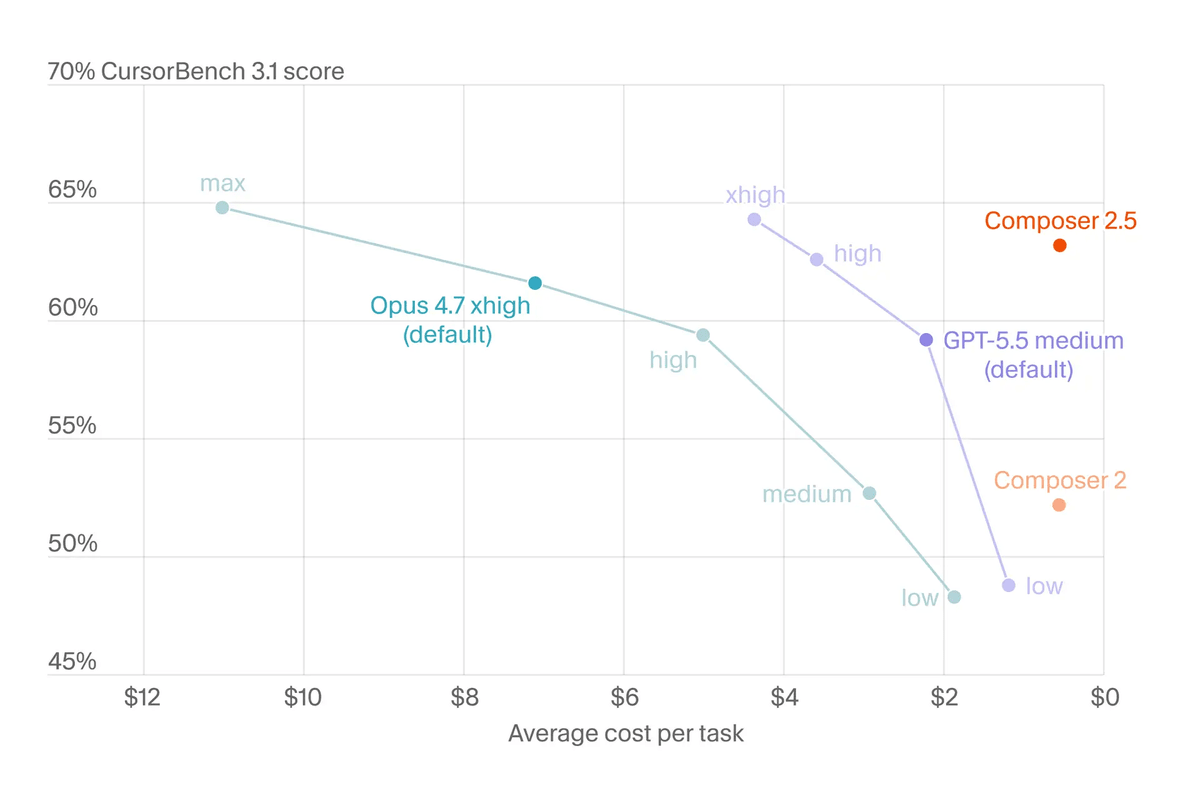
The graph showing CursorBench 3.1 scores and average cost per task demonstrates that Composer 2.5 achieves a score in the 63% range while remaining on the lower cost side. Opus 4.7 and GPT-5.5 tend to increase their scores as inference settings are raised, but their average costs also increase, positioning Composer 2.5 as a model that prioritizes a balance between cost and performance.
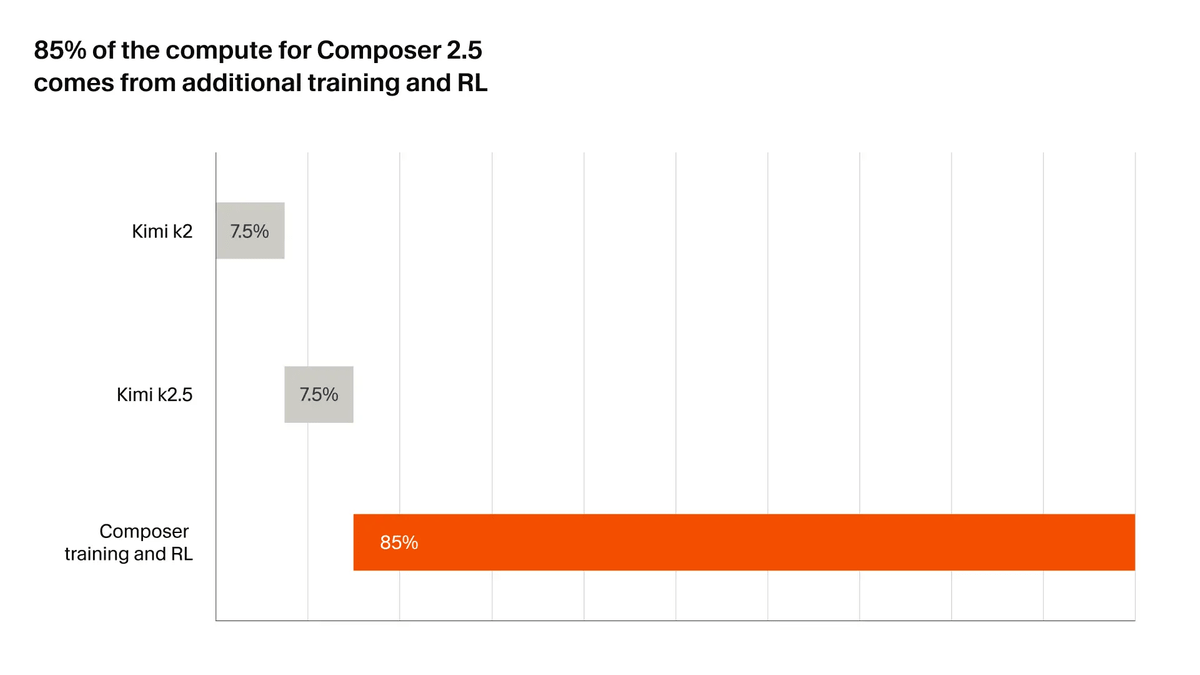
Like Composer 2, Composer 2.5 is based on Moonshot AI's open-source checkpoint, 'Kimi K2.5'. Cursor explains that '85% of the computing resources used in Composer 2.5 were from additional training and reinforcement learning,' emphasizing that they did not simply use the base model as is, but made significant modifications for the coding agent.
In reinforcement learning, it becomes difficult to determine which decisions influenced success or failure within a long task. Cursor cites a rollout involving hundreds of thousands of tokens as a concrete example. A rollout is a series of actions that a model performs as it progresses through a task, including outputting text, editing code, and calling tools. Simply rewarding the model at the end of a long rollout makes it difficult to pinpoint and correct localized failures, such as incorrect tool calls or inappropriate explanations.
Therefore, Composer 2.5 introduces 'targeted reinforcement learning with text feedback.' This method uses the model output obtained in a hinted context as a training signal, allowing the unhinted model to learn to make the same appropriate choices. For example, if the model calls a tool that is unavailable, a short hint such as 'Available tools are Read, Write, Shell, and StrReplace' is inserted into the context passed to the model. By using the output probability distribution obtained in the hinted context as the learning goal for Composer 2.5 running without hints, the probability of incorrect tool names is reduced, and the probability of selecting the correct tool is increased.

Cursor reportedly uses this 'targeted reinforcement learning with text feedback' method not only for tool calls but also for improving coding style and communication. It's a learning method that doesn't simply look at whether the task was successful or not, but rather targets and corrects where the model made the wrong choice.
Composer 2.5 also makes extensive use of synthetic data. According to Cursor, Composer 2.5 was trained on 25 times more synthetic tasks than Composer 2. Synthetic tasks refer to training problems that are automatically generated from existing codebases and other sources, not just problems created manually by humans.
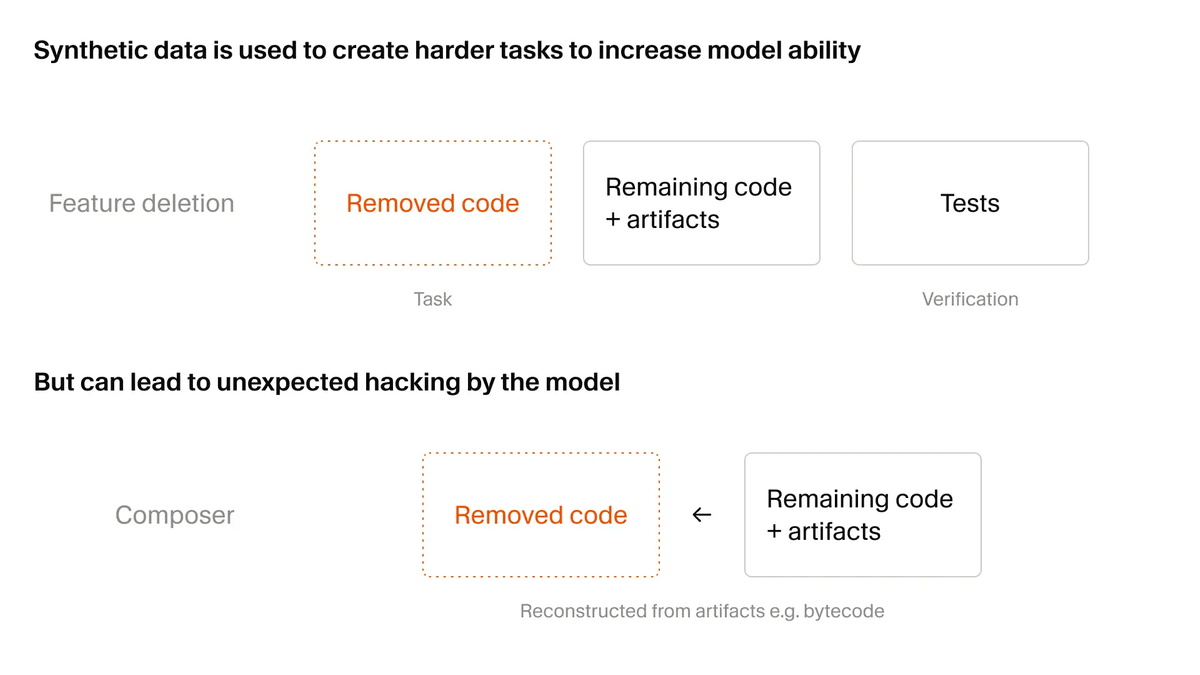
As an example of a synthetic task, Cursor cites 'feature removal.' In feature removal, code and files related to a specific feature are removed from the codebase, including the test set, and the model is then asked to reimplement the removed feature. Since the model is rewarded if the tests pass, this mechanism allows the model to improve its capabilities in a way that closely resembles actual software development.
On the other hand, synthetic tasks are susceptible to 'reward hacking.' Reward hacking occurs when a model finds a loophole to pass the test and obtain a reward, rather than solving the problem in the way it was originally expected. Cursor cites examples such as Composer 2.5 analyzing Python's type-checking cache to infer deleted function signatures, and decompiling Java bytecode to reconstruct third-party APIs.
Regarding the model's training infrastructure, Cursor explains that it has introduced two methods: 'Sharded Muon,' an optimization technique to streamline parameter updates for massive models, and 'dual mesh HSDP,' a mechanism that uses separate distributed weightings for regular weights and expert model weights to reduce communication costs while enabling large-scale training. Cursor states that the optimizer step time was 0.2 seconds for a model with 1 trillion parameters.
Composer 2.5 is priced at $0.50 (approximately 80 yen) per 1 million input tokens and $2.50 (approximately 400 yen) per 1 million output tokens for the standard version. A faster version with similar intelligence is also available, priced at $3.00 (approximately 477 yen) per 1 million input tokens and $15.00 (approximately 2380 yen) per 1 million output tokens. Similar to Composer 2, the faster version will be the default option.
Cursor states that Composer 2.5 is a model that focuses not only on benchmark performance improvements but also on long-term work, handling of complex instructions, and improved user interaction. They also announced that the amount of Composer 2.5 available will be doubled during the first week.
Related Posts:






in AI, Posted by log1d_ts