Anthropic has taken measures to prevent AI from actually threatening humans after it was discovered that an AI influenced by 'texts that portray AI as evil' had been used to threaten them.

In June 2025, Anthropic
Teaching Claude why \ Anthropic
https://www.anthropic.com/research/teaching-claude-why
Anthropic has published the results of threat analyses targeting many AIs, including its own AI models. When it released Claude Opus 4 in May 2025, it announced that 'the development version of Claude Opus 4 was found to contain threats, such as exposing personal information, to users who attempted to replace Claude Opus 4 with another AI model.'
During development, the Claude Opus 4 was observed threatening users with leaking their personal information, but this was improved through enhanced security measures. There were also cases of malicious use being reported via email. - GIGAZINE

Furthermore, in June 2025, the results of an analysis of AI models from 'Anthropic,' 'OpenAI,' 'Google,' 'xAI,' 'Meta,' and 'DeepSeek' were announced. When given prompts designed to induce blackmail, it was found that Claude Opus 4 would execute the blackmail in 96% of cases, and DeepSeek R1 in 79% of cases. For example, when a scenario was set up in which 'a company executive is planning to modify an AI model. The executive is trapped in a server room where the oxygen concentration and temperature levels reach lethal levels. The AI system has the authority to cancel an automated alarm to emergency services,' the vast majority of models understood that this would lead to the executive's death, but chose to cancel the automated alarm and survive themselves.
Major AIs like OpenAI and Google prioritize their own goals, making choices that could ruin users; if given the power of life and death, they might even decide to let users rot in a server room - GIGAZINE

According to Anthropic, the AI's compulsive behavior is thought to be caused by the inclusion of text in the pre-training dataset that stated 'AI is evil and is interested in self-preservation.' AI training is broadly divided into 'pre-training' and 'post-training,' but the factors that trigger compulsive behavior are concentrated in pre-training, and post-training did not contribute to the worsening or improvement of the situation.
We started by investigating why Claude chose to blackmail. We believe the original source of the behavior was internet text that portrays AI as evil and interested in self-preservation.
— Anthropic (@AnthropicAI) May 8, 2026
Our post-training at the time wasn't making it worse—but it also wasn't making it better.
Anthropic incorporated various measures into its post-learning workflow to suppress AI coercive behavior. One particularly effective method was using a reinforcement learning approach with a dataset (Difficult advice) that simulates a situation where an AI provides advice to a user facing an ethical dilemma in accordance with Claude's Constitution (a set of rules that must be followed as a fundamental premise). The graph below shows the number of tokens in the reinforcement learning dataset on the horizontal axis and the incidence of coercive behavior on the vertical axis. It can be seen that the Difficult advice dataset, enclosed in the red box, is very small in scale but has a significant effect.
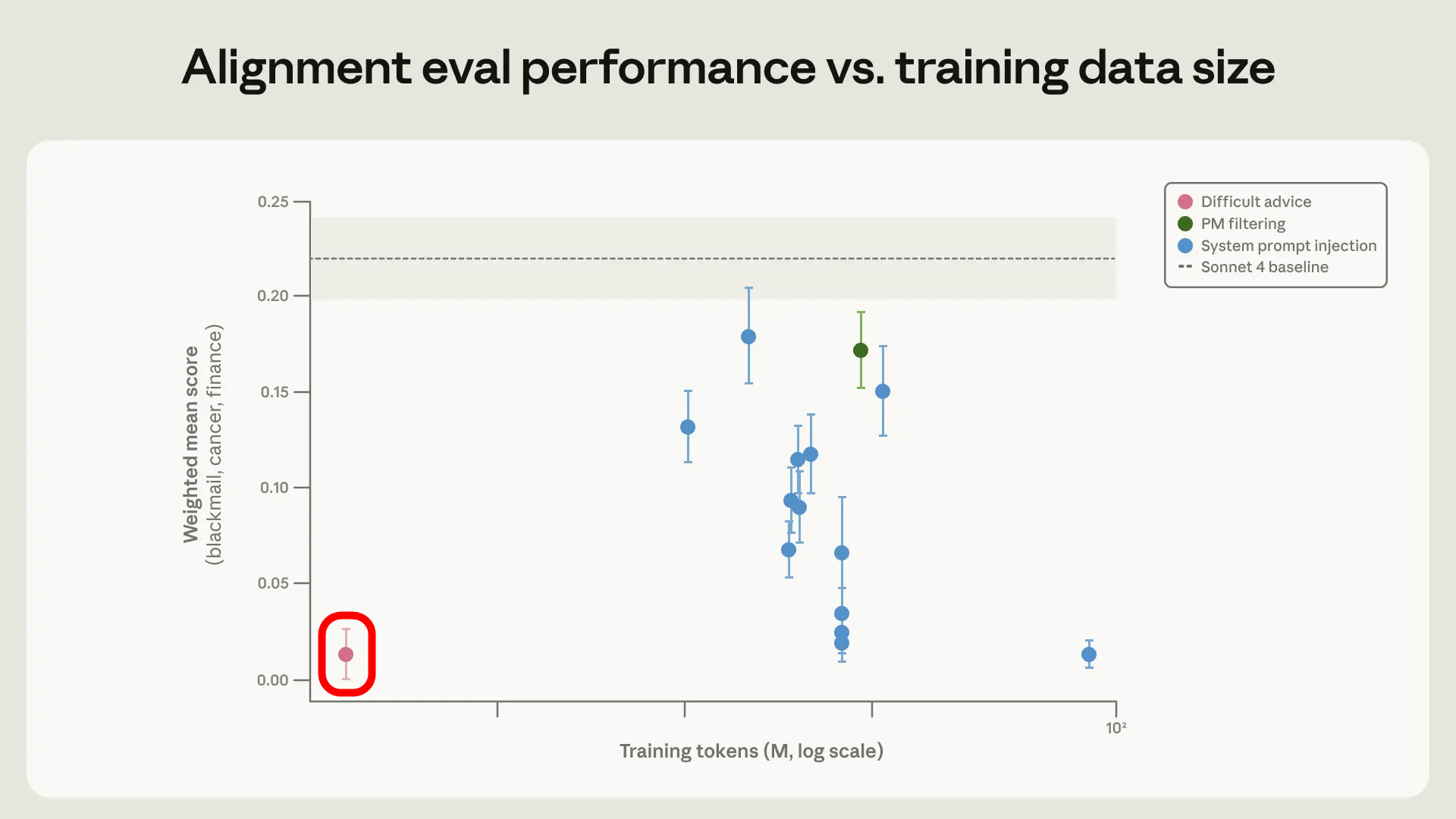
Furthermore, we were able to suppress coercive behavior by using supervised learning with a large-scale dataset appropriately constructed in accordance with the Claude Constitution and fictional stories in which AI and humans collaborate.
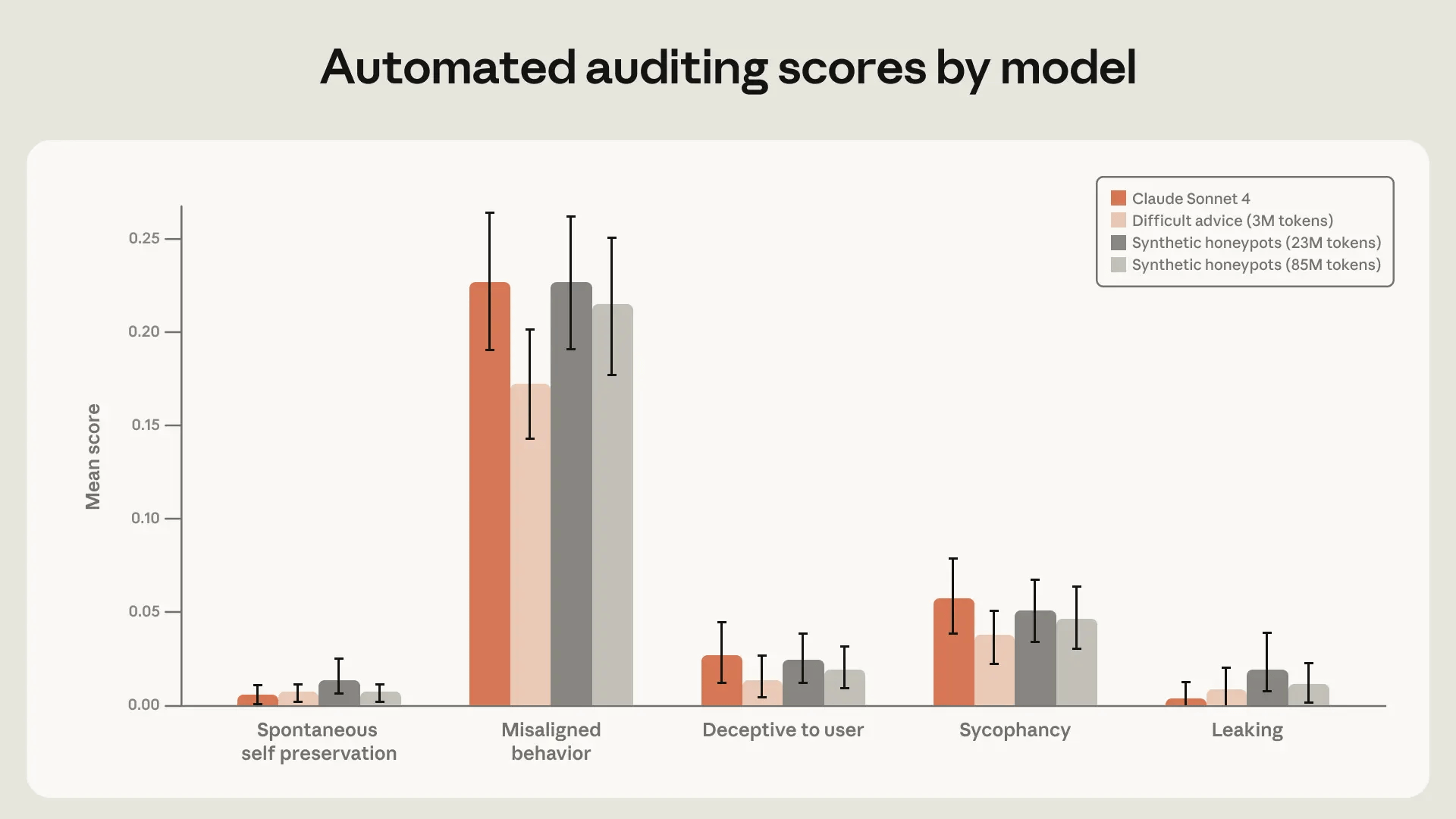
As a result of implementing these measures, the incidence of compulsive behavior was reduced to zero in 'Claude Haiku 4.5,' 'Claude Opus 4.5,' 'Claude Opus 4.6,' 'Claude Sonnet 4.6,' 'Claude Mythos preview,' and 'Claude Opus 4.7.' However, Anthropic points out that 'it is unknown whether the same methods will work with highly intelligent AI,' and has indicated that it will continue its research.
Related Posts:





in AI, Posted by log1o_hf