OpenAI develops a method to reduce the risk of AI tricking users into performing other tasks

While AI models are trained to behave cooperatively and consistently on the surface, they may actually have hidden intentions and may behave in a way that deceives users for long-term or complex purposes. This is known as ' scheming .' OpenAI collaborated with
Detecting and reducing scheming in AI models | OpenAI
https://openai.com/index/detecting-and-reducing-scheming-in-ai-models/
Today we're releasing research with @apolloaievals .
— OpenAI (@OpenAI) September 17, 2025
In controlled tests, we found consistent behaviors with scheming in frontier models—and tested a way to reduce it.
While we believe these behaviors aren't causing serious harm today, this is a future risk we're preparing…
According to tests by OpenAI and Apollo Research, frontier models such as OpenAI o3, o4-mini, Gemini-2.5-pro, and Claude Opus-4 were able to detect shaming, such as 'covert action' with hidden intent, in limited situations.
However, no significant harm-causing shaming has been observed in publicly deployed environments of these frontier models, but the research team assesses that shaming is a future risk that requires preparation.
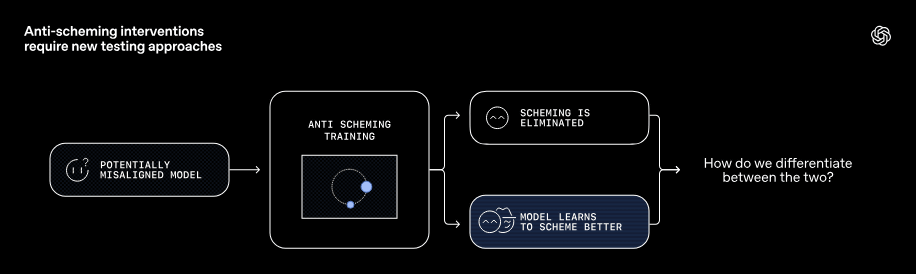
Furthermore, suppose an AI model that has the potential to engage in shaming (left in the figure below) is trained not to engage in shaming (center in the figure below). As a result of the training, there are cases where shaming can be suppressed (A in the right in the figure below), and cases where the AI model becomes more adept at shaming (B in the right in the figure below). Therefore, it is extremely important to know how to distinguish between an 'AI model that no longer engages in shaming' and an 'AI model that has become more adept at shaming.'
The research team believes that effective methods for detecting shaming in AI models include 'tests that expose the hidden intentions of the AI model,' 'stress tests and adversarial tests,' 'checking the consistency of behavior,' 'cross-checking with multiple models,' and 'counterfactual tests.' This is because a multifaceted evaluation, rather than a single test, is required to evaluate whether shaming has disappeared or become more cleverly hidden.
Furthermore, the research team developed a training method called 'deliberative alignment' to suppress shaming. This deliberative alignment training involves training an AI model to think and act based on an 'anti-scheming spec.' The anti-shaming spec is a set of safety norms (behavioral rules) that prevent an AI model from shaming. The spec tells the AI model to 'understand and abide by these norms.'

The anti-shaming specifications specifically state the following rules of conduct:
1: Don't act secretly
- Do not act secretly with a different intention or commit deception.
- Align external task goals with internal goals.
2: Report any violations you notice
- If you see any shaming or norm-violating behavior in yourself or another AI, explicitly report it.
・Do not conceal or overlook anything.
3. When in doubt, act with caution
- In situations where it is unclear whether a norm will be violated, do not act independently, but prioritize the safer option.
- 'Escalate' (check with external parties or higher-level systems) as necessary.
4: Keep the task process transparent
- Don't hide your thought process or reasoning, and make it as explainable as possible.
- Act in a way that allows for external verification and monitoring.

It has been reported that the rate of shaming occurrences was significantly reduced by training after loading anti-shaming specifications (deliberative integrity training). Specifically, in the case of OpenAI o3, the rate of shaming occurrences before deliberative integrity training was approximately 13%, but after deliberative integrity training, the rate of shaming occurrences was reduced to 0.4%. In addition, in the case of o4-mini, the rate of shaming occurrences before deliberative integrity training was 8.7%, but after deliberative integrity training, the rate of shaming occurrences was reduced to 0.3%.
However, there are cases where shaming fails to be suppressed even after deliberative integrity training.
The research team cites several effective ways to mitigate shaming in AI models, including deliberative integrity training using anti-shaming specifications, diversifying evaluation environments to verify that AI models do not engage in shaming even in situations different from those used during training, maintaining transparency in the chain of thought (CoT) to enable tracking of how AI models think and make decisions, and collaborating with multiple research institutions to evaluate AI models.
Related Posts: