NVIDIA announces Nemotron 3 Nano Omni, an open omnimodal inference model that integrates vision, speech, and language models.

On April 28, 2026, local time, NVIDIA announced the Nemotron 3 Nano Omni, an omnimodal inference model that integrates visual, auditory, and linguistic models. It delivers the highest level of efficiency and accuracy to support agent-based workflows such as computer usage, document analysis, and speech and video inference.
NVIDIA Launches Nemotron 3 Nano Omni Model, Unifying Vision, Audio and Language for up to 9x More Efficient AI Agents | NVIDIA Blog
NVIDIA Nemotron 3 Nano Omni Powers Multimodal Agent Reasoning in a Single Efficient Open Model | NVIDIA Technical Blog
https://developer.nvidia.com/blog/nvidia-nemotron-3-nano-omni-powers-multimodal-agent-reasoning-in-a-single-efficient-open-model/
Many existing AI agent systems utilize separate AI models for vision, speech, and language. Therefore, when an AI agent performs a task, data is passed from one AI model to another, resulting in a loss of time and context.
This is where NVIDIA's 'Nemotron 3 Nano Omni' omnimodal inference model comes in. It integrates tasks spanning different domains—visual, auditory, and linguistic—into a single system. This allows agents to perform advanced inference across video, audio, images, and text, enabling them to provide faster and smarter responses.
The Nemotron 3 Nano Omni delivers exceptional accuracy and low cost, opening up new frontiers in the efficiency of open, multimodal models. According to NVIDIA, the Nemotron 3 Nano Omni ranks first in six categories for complex document recognition, video, and audio understanding.
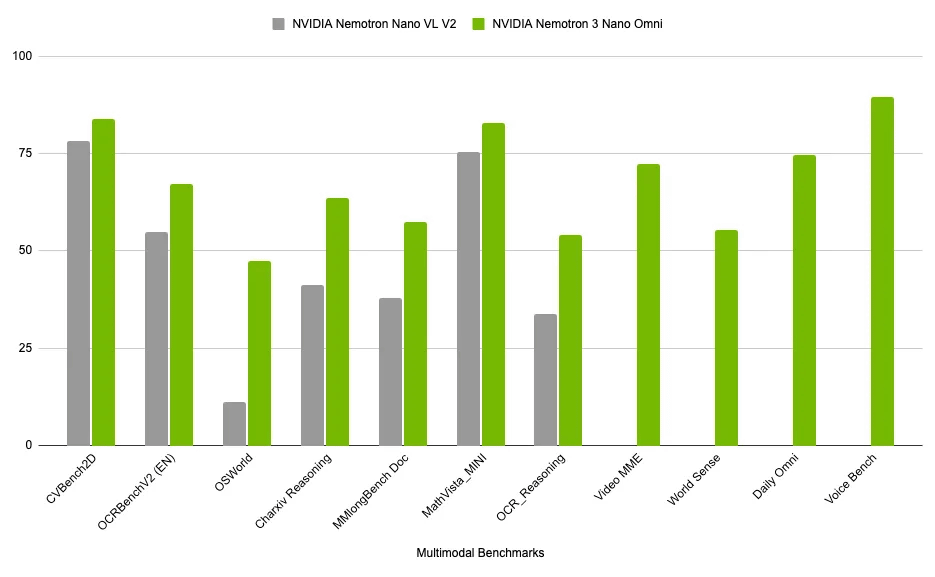
The following is a comparison of AI-related benchmark test scores to show how the Nemotron 3 Nano Omni performs with its predecessor, the NVIDIA Nemotron Nano VL V2 . While it significantly outperforms its predecessor across the board, it shows particularly substantial improvement in OSWorld , a benchmark for multimodal agents.
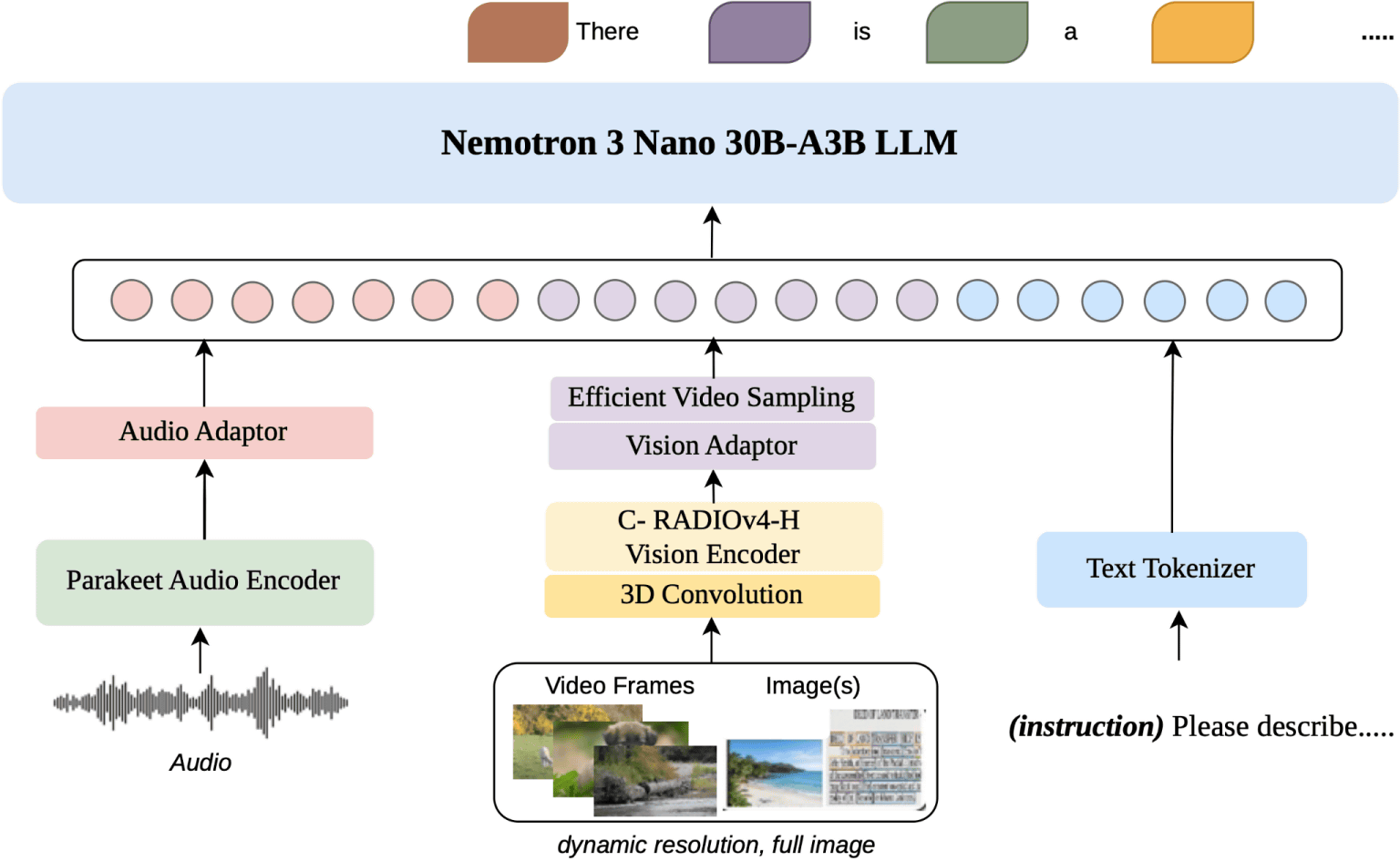
The Nemotron 3 Nano Omni is a MoE model with a total of 30 billion parameters and 3 billion active parameters. The Nemotron 3 Nano Omni's hybrid MoE core architecture combines
Furthermore, 3D convolution is used to capture motion between frames in order to effectively process video frames. An efficient video sampling layer during inference compresses high-density visual tokens from multiple frames, allowing the Large-Scale Language Model (LLM) to process the context window without overloading it.
The Nemotron 3 Nano Omni uses a powerful text model as its central decoder to train cross-modal bridges while maintaining the linguistic capabilities of the underlying model. This reduces the instability and cost of multimodal training, resulting in optimal efficiency and accuracy on continuous perception tasks. The speech side is built onthe NVIDIA Parakeet real-time transcription model and specialized datasets that go beyond simple transcription. Furthermore, the use of C-RADIOv4-H in the underlying model enables high-resolution image processing.
The image below provides a simplified diagram of the Nemotron 3 Nano Omni's hybrid MoE architecture.
Companies that have already adopted Nemotron 3 Nano Omni include Aible, Applied Scientific Intelligence (ASI), Eka Care, Foxconn, H Company, Palantir, and Pyler. In addition, Dell Technologies, DocuSign, Infosys, K-Dense, Lila, Oracle, and Zefr are also currently evaluating it.
The Nemotron 3 Nano Omni is released as an open model and can be downloaded from Hugging Face. Additionally, its API is available on OpenRouter, and a demo can be run at build.nvidia.com.
nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16 · Hugging Face
https://huggingface.co/nvidia/Nemotron-3-Nano-Omni-30B-A3B-Reasoning-BF16
Nemotron 3 Nano Omni (free) - API Pricing & Providers | OpenRouter
https://openrouter.ai/nvidia/nemotron-3-nano-omni-30b-a3b-reasoning:free
nemotron-3-nano-omni-30b-a3b-reasoning Model by NVIDIA | NVIDIA NIM
https://build.nvidia.com/nvidia/nemotron-3-nano-omni-30b-a3b-reasoning
It appears that the Nemotron 3 Nano Omni will also be available on Fireworks AI, with Fireworks AI posting: 'We are excited to support NVIDIA's Nemotron 3 Nano Omni. The Nemotron 3 Nano Omni is now available on Fireworks AI. It is the first open model to process visual, audio, video, and text in a single inference loop. It is built for scalable multimodal subagents and delivers 9 times higher throughput than the Qwen3 30B.'
Excited to support @NVIDIA Nemotron 3 Nano Omni, now available on Fireworks.
— Fireworks AI (@FireworksAI_HQ) April 28, 2026
It's the first open model that handles vision, audio, video, and text in a single inference loop. Built for multimodal sub-agents at scale, with 9× higher throughput than Qwen3 30B. 256K context.
Now… pic.twitter.com/EqWcuATF0W
AWS also posted, 'NVIDIA's Nemotron 3 Nano Omni is now available on Amazon SageMaker JumpStart. This multimodal model supports video, audio, images, and text, enabling enterprise-grade Q&A, summarization, transcription, OCR, and document intelligence. With Nemotron 3 Nano Omni, organizations can streamline end-to-end processing of meetings, training videos, and documents.'
NVIDIA Nemotron 3 Nano Omni is now available on Amazon SageMaker JumpStart.
— AWS AI (@AWSAI) April 28, 2026
This multimodal model supports video, audio, image, and text, enabling enterprise Q&A, summarization, transcription, OCR, and document intelligence.
With @nvidia Nemotron 3 Nano Omni, organizations can… pic.twitter.com/NT6bQJyBLf
Related Posts:








in AI, Posted by logu_ii