Google announces open AI model 'Gemma 4' and changes its license to Apache 2.0.

Google released Gemma 4 , a suite of open models, on April 2, 2026. Based on similar technologies to Gemini 3, this model is specifically designed for advanced inference and autonomous agent capabilities. For developer convenience, this release changes the license from its previous proprietary format to the commercially permissive Apache 2.0.
Gemma 4: Our most capable open models to date
What's new in Gemma 4 - YouTube
Google announces Gemma 4 open AI models, switches to Apache 2.0 license - Ars Technica
https://arstechnica.com/ai/2026/04/google-announces-gemma-4-open-ai-models-switches-to-apache-2-0-license/
According to Google, Gemma has been downloaded more than 400 million times since its initial release, and more than 100,000 derivative models have been created. The newly announced Gemma 4 comes in four sizes to cover everything from edge devices to desktop environments.
For mobile and IoT devices, Effective 2B (E2B) with a parameter size of 2 billion and Effective 4B (E4B) with a parameter size of 4 billion are available, achieving high computational and memory efficiency. These two models, E2B and E4B, employ layer-level embedding (PLE) to maximize parameter efficiency in device deployment, making them more effective. For larger-scale tasks, there are two types of MoE models: the 26B model with a parameter size of 26 billion and the Dense model with a parameter size of 31 billion.
The 26B model achieved a token generation speed that surpassed other models of similar size by activating only 3.8 billion of its total parameters during inference. The 31B model is ranked as the third-best open model in the world on the industry-standard Arena AI leaderboard . The 26B model also ranked sixth, demonstrating performance comparable to models more than 20 times its size. Google says this allows developers to leverage cutting-edge AI capabilities with fewer hardware resources.
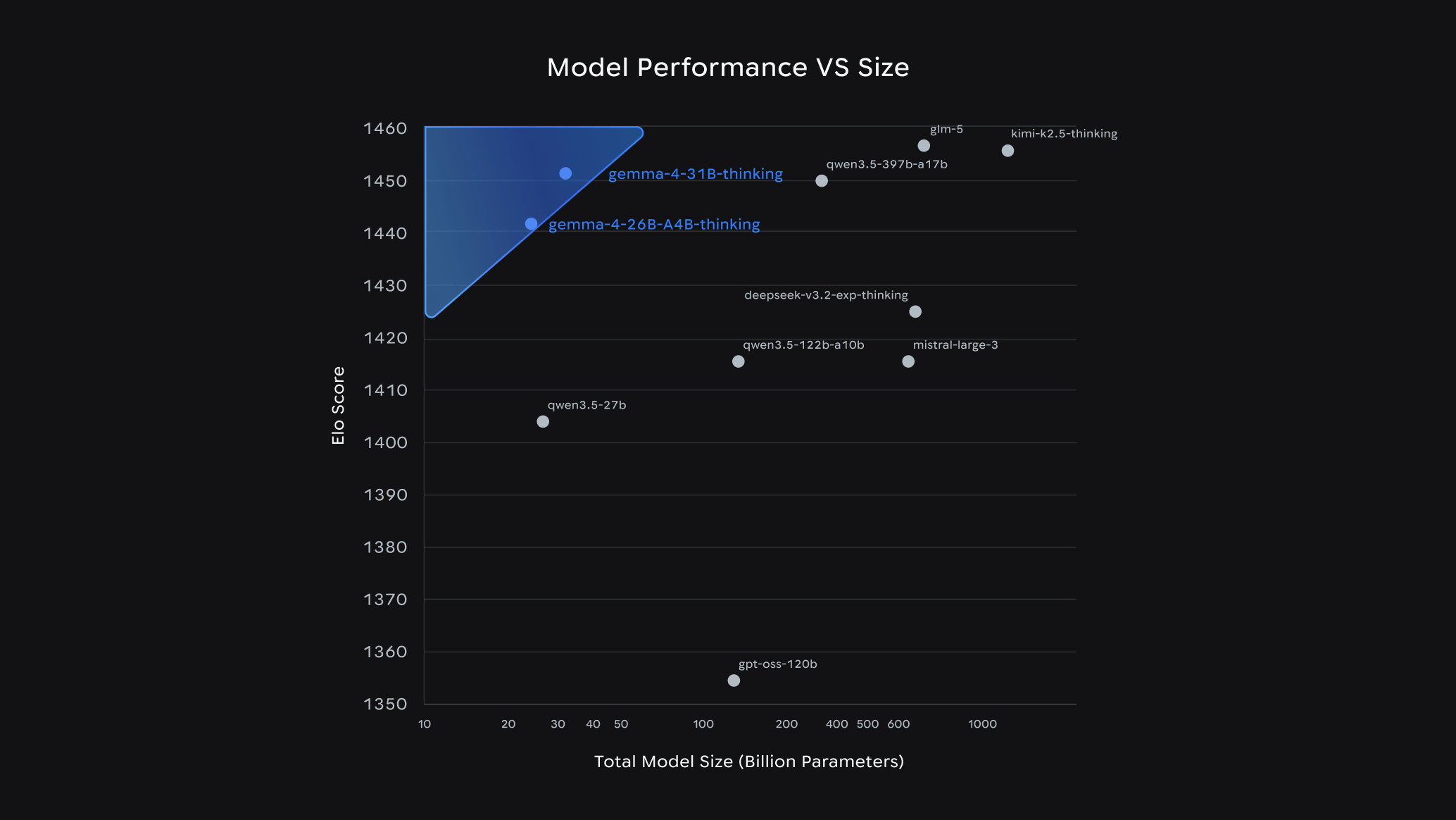
In terms of functionality, multi-stage planning and logical thinking have been significantly enhanced, resulting in high scores on mathematical and instruction-following benchmarks. To support the construction of autonomous agents, it now supports function calls, structured JSON output, and native system instructions as standard. It also boasts high code generation capabilities, enabling high-quality code generation even in a local offline environment, provided that hardware capable of running large-scale models is available.
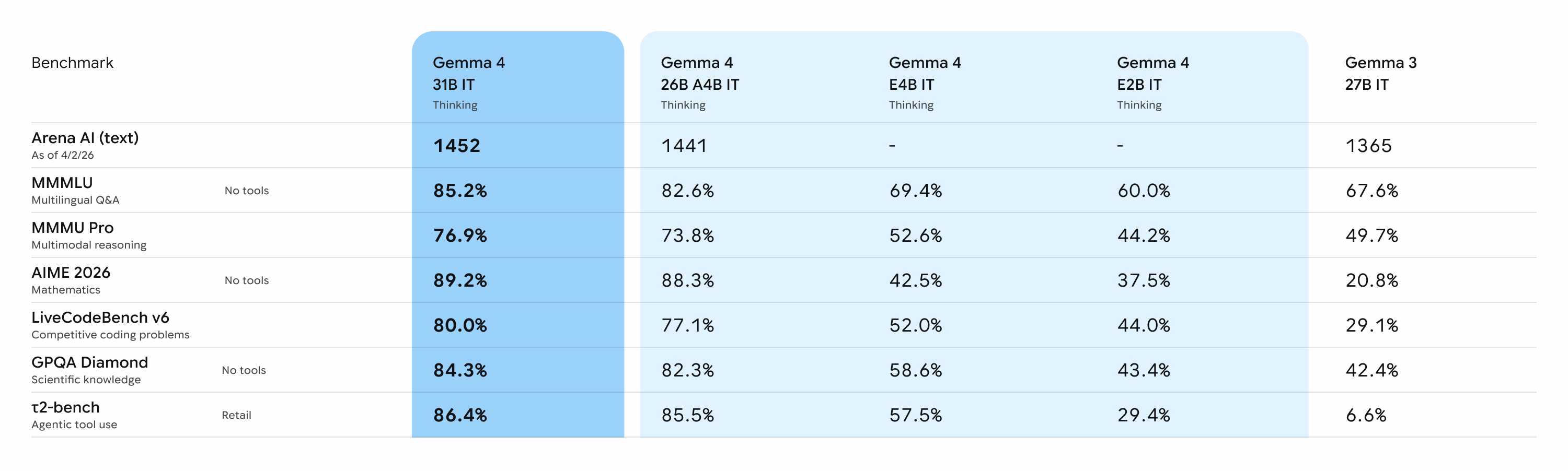
All Gemma 4 models feature multimodal capabilities for processing images and videos, delivering superior accuracy in optical character recognition (OCR) and graph comprehension. The edge-oriented E2B and E4B models also support voice input, enabling on-device speech recognition and comprehension. Gemma 4 supports over 140 languages, supporting global application development.
The context window, which understands the context, can process up to 128,000 tokens in the edge model and up to 256,000 tokens in the large model. This is an unusual length for a local model and is suitable for operations that load large amounts of source code or long documents at once.
The 26B and 31B models, in particular, are large-scale models positioned to enable researchers and developers to handle cutting-edge inference performance offline even on their personal PCs. The non-quantized bfloat16 version is designed to run on a single 80GB NVIDIA H100 GPU, and the quantized version can run locally on typical consumer GPUs. The 26B model prioritizes low latency and fast token generation by enabling only 3.8 billion of the total 26 billion parameters during inference, while the 31B Dense model prioritizes output quality over speed and is intended to be used as a foundation for further training and application-specific tuning.
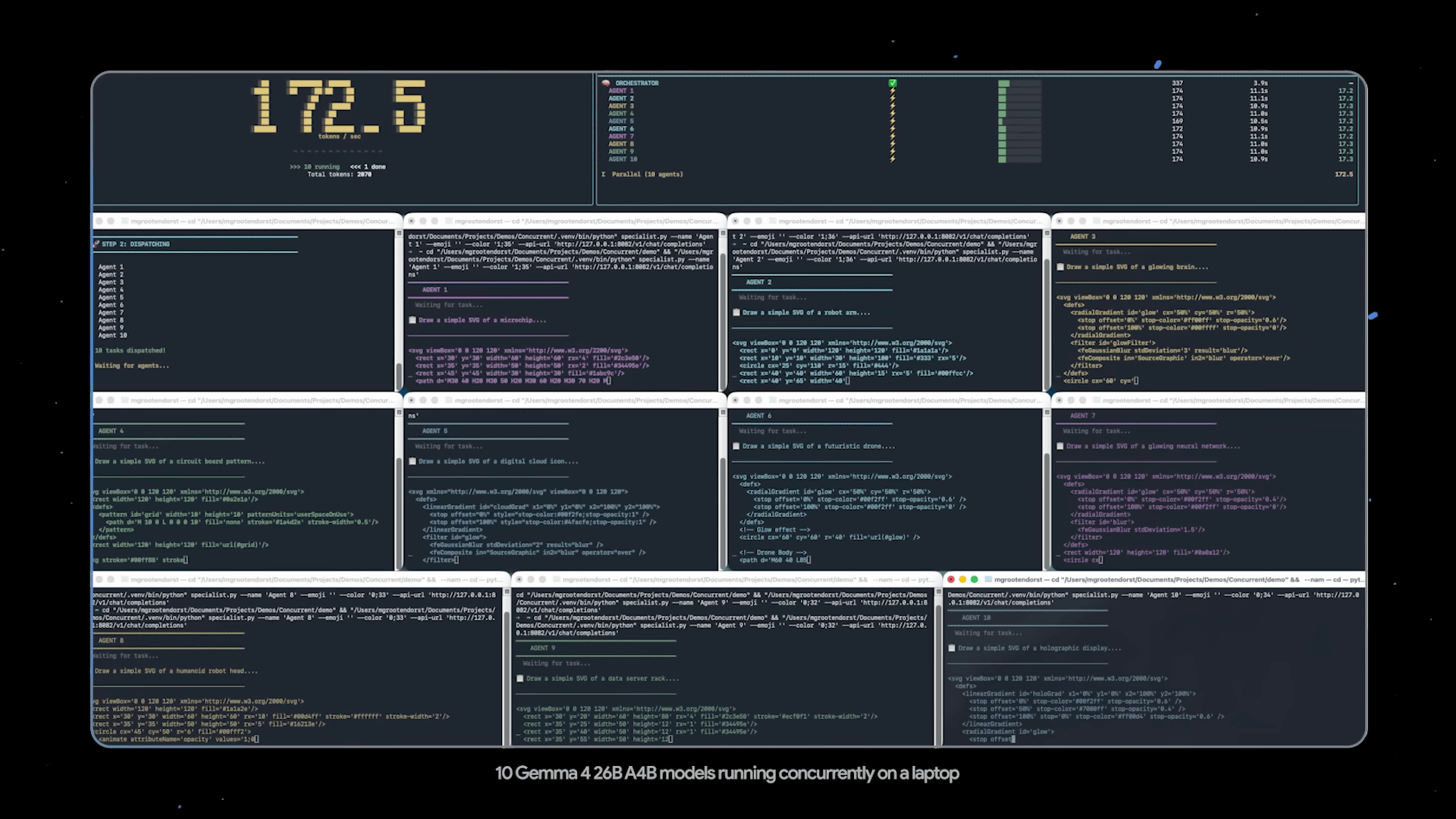
In contrast, the E2B and E4B are designed for mobile and IoT devices, and have been optimized for low-memory, low-latency operation on smartphones, Raspberry Pi, Jetson Orin Nano, and other devices through collaboration with Qualcomm, MediaTek, and the Google Pixel team. Google explains that these models will also form the basis for the next-generation Gemini Nano 4 and are expected to lead to enhanced local AI capabilities for Android.
Furthermore, with the release of Gemma 4, Google has fundamentally revised its licensing structure, eliminating the custom licenses used in previous models and switching entirely to the widely adopted Apache 2.0 license. Google states that this change reflects feedback from the developer community and aims to remove restrictive barriers by emphasizing a collaborative approach to building the future of AI.
The custom licenses used in previous versions of Gemma, such as Gemma 3, were actually too restrictive for many developers. They included strict prohibitions that Google could unilaterally update, and required the enforcement of Google's rules across all Gemma-based projects. Furthermore, there were clauses that could be interpreted as extending the license to other AI models created using synthetic data generated by Gemma, creating a significant psychological barrier for developers adopting Google's open model.
The newly adopted Apache 2.0 is an open-source license that is extremely permissive even for commercial use. Because there are no excessive terms of use or commercial restrictions, developers can ensure digital sovereignty, having complete control over their data, infrastructure, and models. Furthermore, since Google cannot unilaterally change the license terms in the future, developers can integrate the technology into their projects with long-term peace of mind. This license refresh allows for the free and secure building and deployment of models in any environment, whether on-premises or in the cloud.
Clément Delang, co-founder and CEO of Hugging Face, highly praises this change as a significant milestone and has pledged full support for the Gemma 4 family from day one. Google hopes that by empowering developers with control over data and deployment plans, they will see further expansion of innovative research and products powered by Gemma.
Gemma 4's 31B and 26B models are accessible through Google AI Studio, while the E4B and E2B models are accessible through the Google AI Edge Gallery. Additionally, the models are distributed via HuggingFace, and model weights can be obtained from Kaggle and Ollama .
Welcome Gemma 4: Frontier multimodal intelligence on device
https://huggingface.co/blog/gemma4
Google also announced the addition of two service tiers, 'Flex' and 'Priority,' to its Gemini API. They emphasize that this makes it easier to balance cost and reliability by allowing users to differentiate between APIs for background processing tasks and interactive tasks requiring high reliability, such as chatbots.
Flex and Priority tiers in the Gemini API
https://blog.google/innovation-and-ai/technology/developers-tools/introducing-flex-and-priority-inference/
Related Posts:







