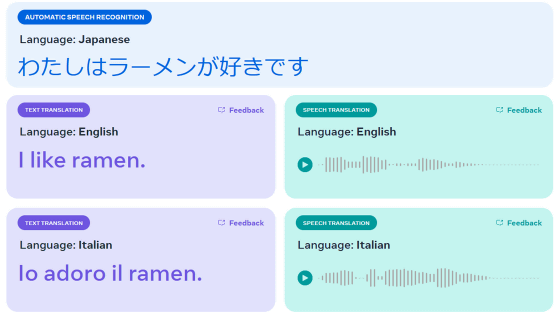
Meta launches Omnilingual ASR, a transcription AI that supports over 1,600 languages
Meta has released the transcription AI ' Omnilingual ASR .' Omnilingual ASR supports transcription in over 1,600 languages, including Japanese, and also features the ability to easily add supported languages.
Omnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages | Research - AI at Meta
Omnilingual ASR: Advancing Automatic Speech Recognition for 1,600+ Languages
https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/
Developing transcription AI typically requires preparing a huge amount of training data. Omnilingual ASR successfully reduces the amount of training data required by using the 7 billion parameter voice encoder 'wav2vec 2.0.'
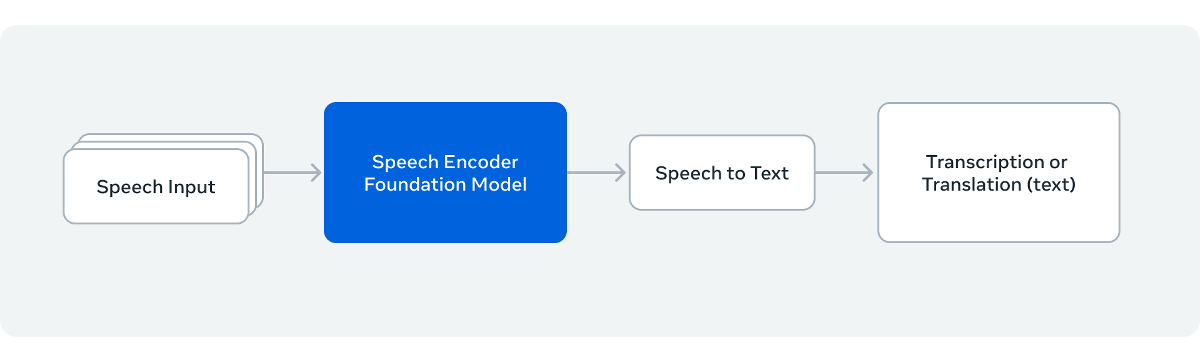
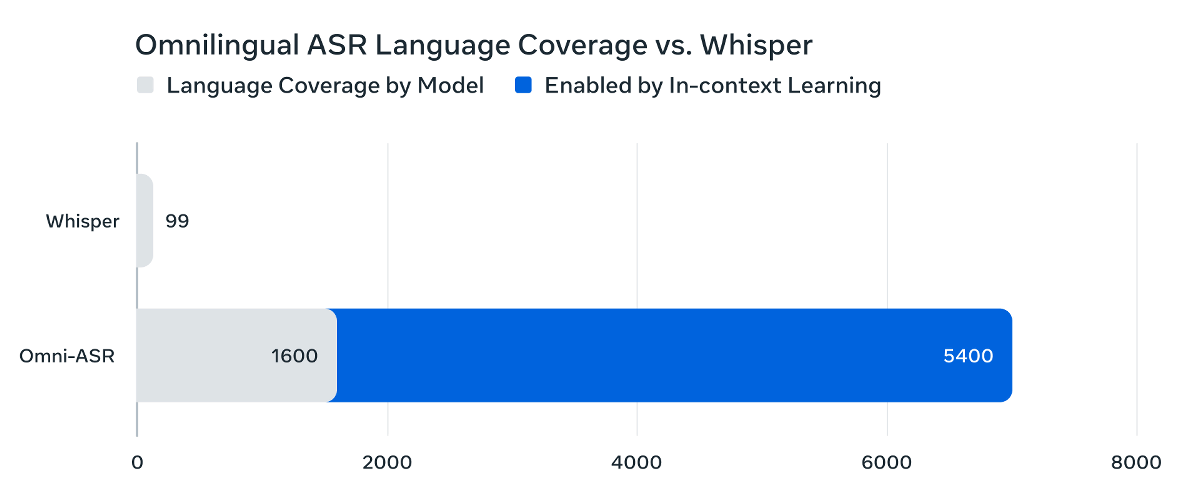
Of the more than 1,600 languages supported, 78% have a character error rate (CER) below 10%. Of the languages with a CER below 10%, 236 required more than 50 hours of training data, while 195 were trained with less than 10 hours of training data. Omnilingual ASR also supports in-context learning, a method used in large-scale language models, allowing for the expansion of supported languages with minimal effort. This allows it to support an overwhelming number of languages compared to existing models such as Whisper.
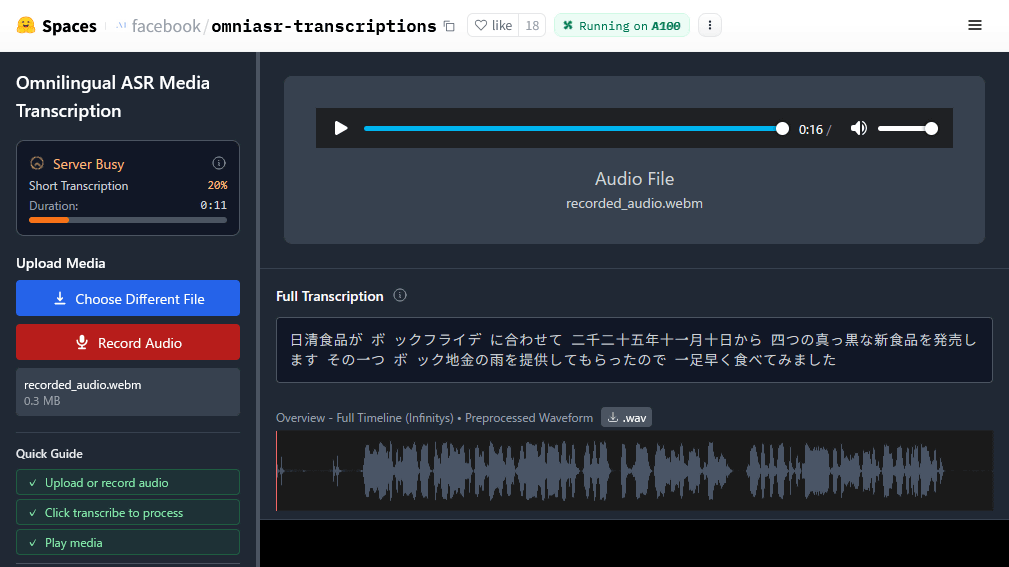
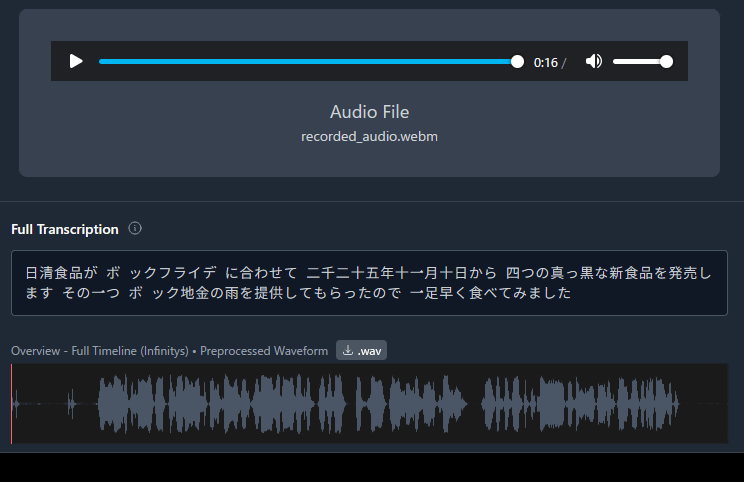
A demo page where you can run Omnilingual ASR is available at the following link.
Omnilingual ASR Media Transcription - a Hugging Face Space by facebook

When I actually read out the article by GIGAZINE and transcribed it, the phrase 'Black Chicken Ramen' became the mysterious phrase 'Bock Bullion Rain.'
The source code and documentation for Omnilingual ASR are available at the following links:
GitHub - facebookresearch/omnilingual-asr: Omnilingual ASR Open-Source Multilingual SpeechRecognition for 1600+ Languages
https://github.com/facebookresearch/omnilingual-asr
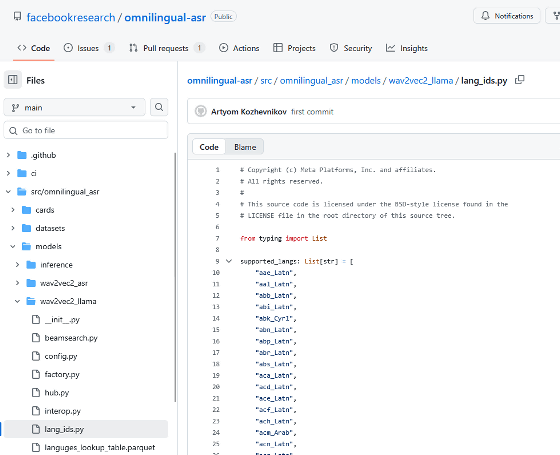
The list of supported languages is listed in the code below. Japanese is listed as 'jpn_Jpan'. There is also an interactive page where you can explore the supported languages.
omnilingual-asr/src/omnilingual_asr/models/wav2vec2_llama/lang_ids.py at main · facebookresearch/omnilingual-asr · GitHub
https://github.com/facebookresearch/omnilingual-asr/blob/main/src/omnilingual_asr/models/wav2vec2_llama/lang_ids.py
In addition, the Omnilingual ASR Corpus, a speech dataset collected during the development of Omnilingual ASR, is also publicly available.
facebook/omnilingual-asr-corpus · Datasets at Hugging Face
https://huggingface.co/datasets/facebook/omnilingual-asr-corpus
Related Posts: