Harvard University releases 'Institutional Books', a dataset that extracts text from 980,000 copyright-free books, utilizing data from Google Books' book indexing project

The Harvard Law School Library has released a dataset called ' Institutional Books ,' which contains text data extracted from 983,000 books. The dataset was created using the work of Google Books.
Institutional Books | Institutional Data Initiative
Institutional Books contains data from 983,000 books with a total of 386 million pages, and the books were written in 254 different languages.

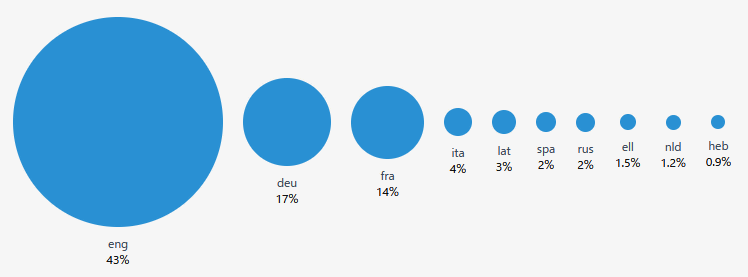
The breakdown of languages is as follows: English is the most common at 43%, followed by German (17%), French (14%), Italian (4%), Latin (3%), Spanish (2%), Russian (2%), Greek (1.5%), Dutch (1.2%) and Hebrew (0.9%).
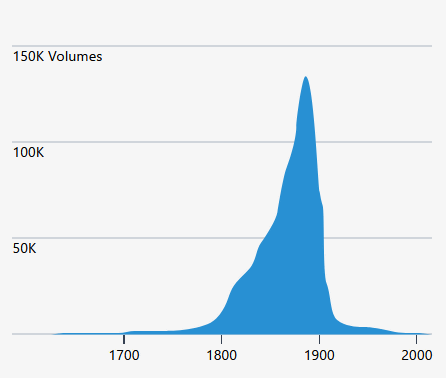
Below is a graph summarizing the years in which the format was written. It seems that most of the books were written between 1800 and 1900.
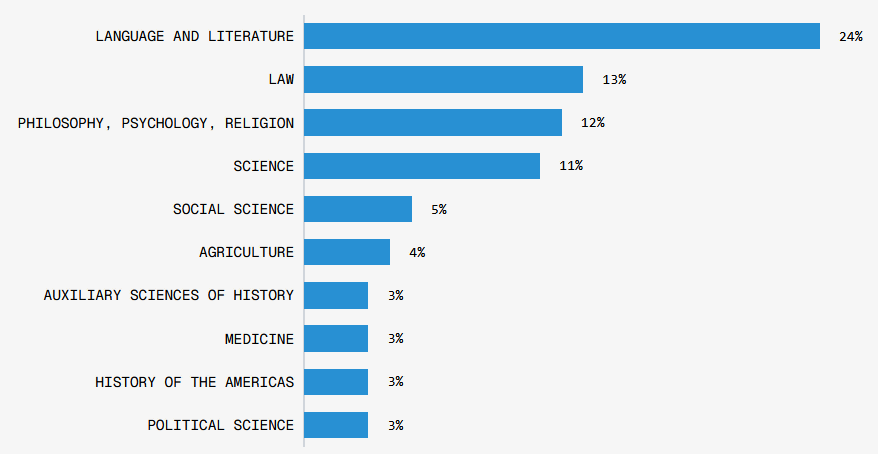
When the books were classified according to
To build Institutional Books, a dedicated pipeline was developed to extract data from the Harvard University book collection data on Google's servers. The pipeline first downloads book contents and book information from Google's servers.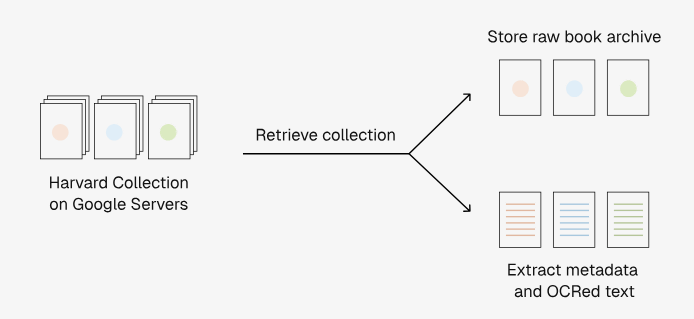
The downloaded book data was subjected to OCR processing to classify the language and topic used. In the process of this work, new discoveries were made, such as 'books classified as written in Latin were found to be written in Latin and French.'

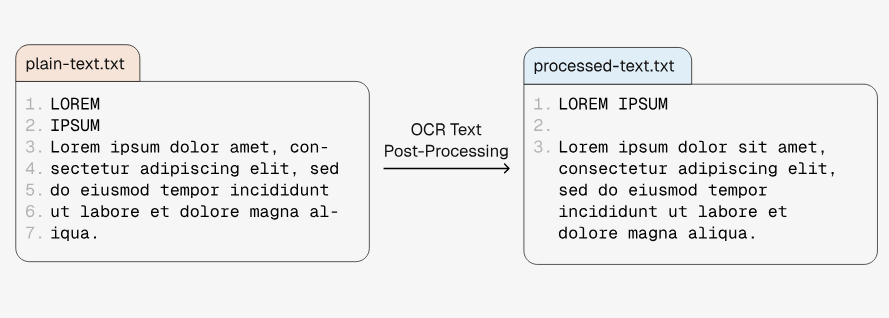
When books are converted to text data using OCR, line breaks can appear in positions that are difficult to read. The newly developed pipeline also includes a function to adjust the position of these line breaks to make them easier to read.
The Institutional Books data is available at the following link and is freely available for non-commercial use only.
institution/institutional-books-1.0 · Datasets at Hugging Face
https://huggingface.co/datasets/institutional/institutional-books-1.0
The source code for the pipeline used to build Institutional Books is available in the following GitHub repository:
GitHub - instdin/institutional-books-1-pipeline: The Institutional Data Initiative's pipeline for analyzing, refining, and publishing the Institutional Books 1.0 collection.
https://github.com/instdin/institutional-books-1-pipeline
Additionally, a paper on the construction of Institutional Books is available at the following link:
Institutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability
https://arxiv.org/abs/2506.08300

Related Posts:







in Software, Posted by log1o_hf