Meta's basic AI research team publishes multiple research findings, sharing AI models, datasets, and other results

Meta's Fundamental AI Research Team (Meta FAIR) has released several new research results to the public, based on the principles of open science. Meta FAIR's publications include a new multimodal AI model, a dataset they helped develop, speech generation AI, and audio watermarking technology.
Sharing new research, models, and datasets from Meta FAIR

Meta FAIR's mission is to advance the state of the art in AI through open research to benefit everyone, and aims to deepen fundamental understanding of all AI-related fields. Meta FAIR has been focused on advancing the state of the art in AI through open research for over a decade. With innovation in this field rapidly advancing, Meta noted, 'we believe collaboration with the global AI community will be more important than ever.' By maintaining an open science approach and sharing its research with the community, Meta FAIR stated, 'we can stay true to our goal of building AI systems that work for everyone and bring the world closer together.'
Based on these principles, Meta FAIR brings together the latest six research findings.
◆1: Meta Chameleon
Meta Chameleon is a multimodal large-scale language model (LLM) that can combine text and images as input and output any combination of text and images using a single integrated architecture for both encoding and decoding. While most existing AI models use diffusion models , Meta Chameleon employs tokenization for text and images, enabling a more integrated approach and making AI models easier to design, maintain, and scale. It can also generate creative captions for images or generate entirely new images by combining text prompts and images.
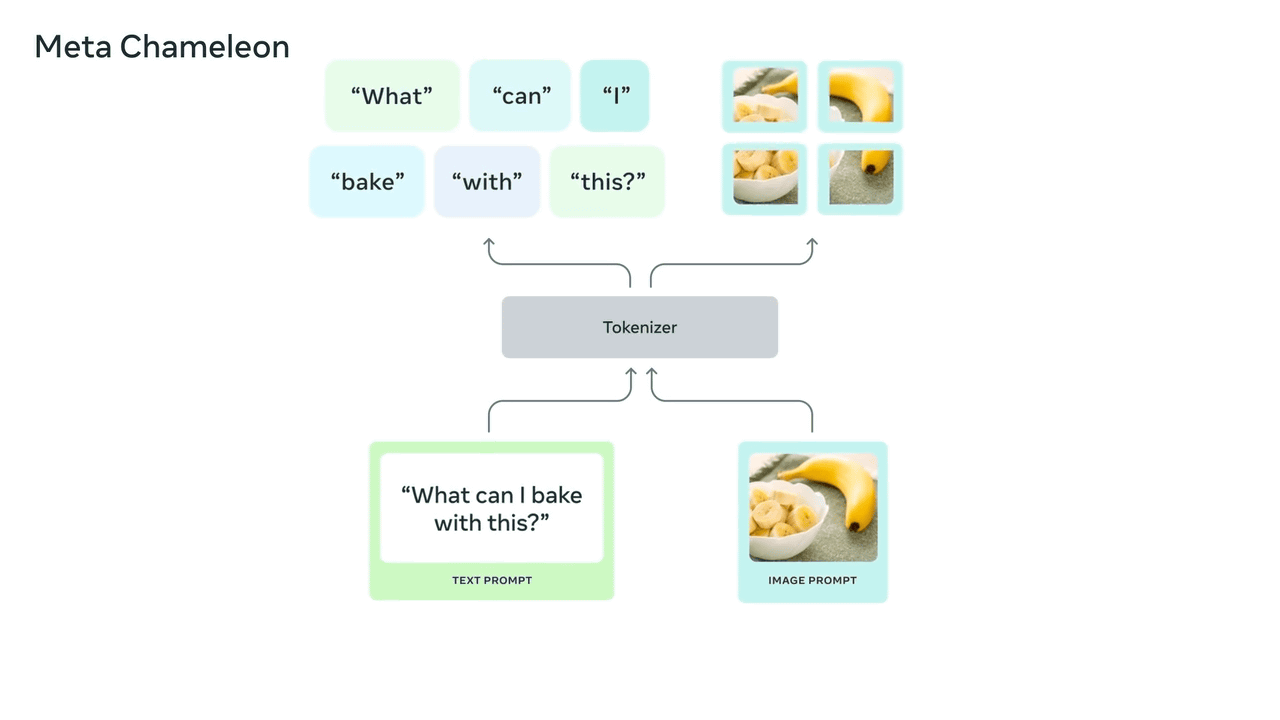
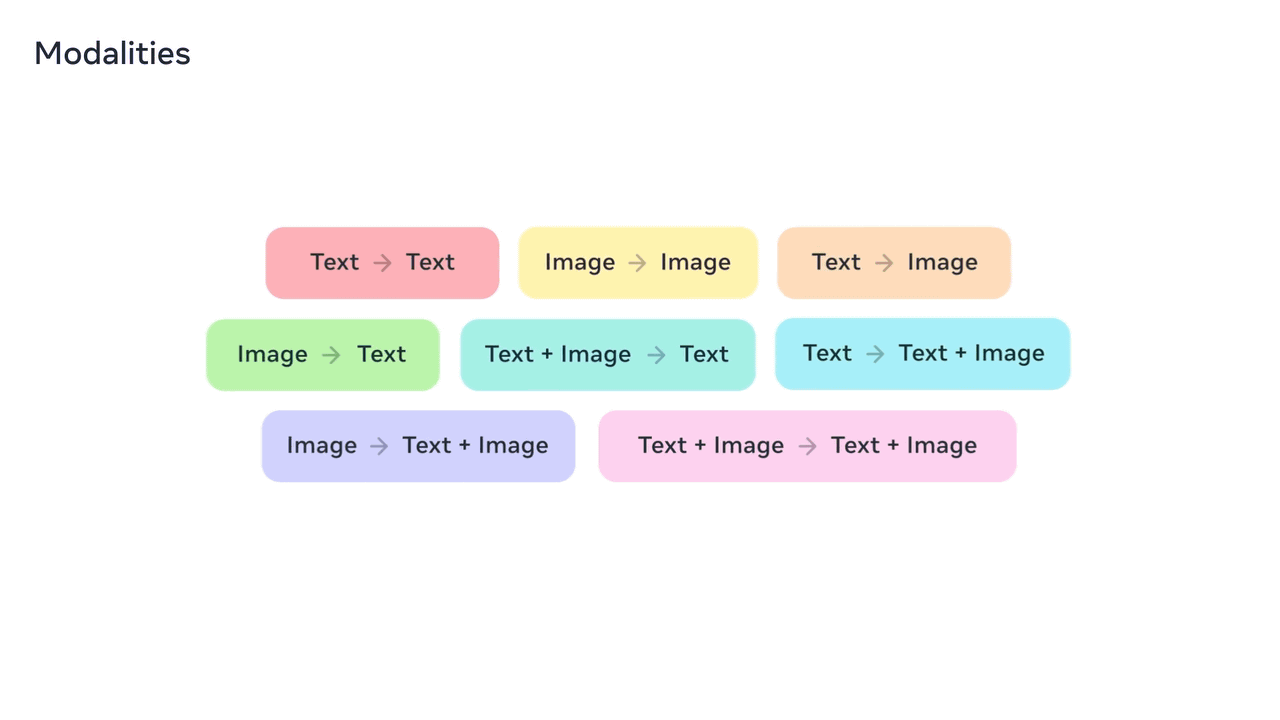
Meta Chameleon also allows you to generate new text from text, generate new images from images, generate images from text, generate text from images, generate text from text-image combinations, generate text-image combinations from text, generate text-image combinations from images, and generate image-text combinations from image-text combinations.
Meta Chameleon itself was published in
While Meta has taken steps to develop these models responsibly, we recognize that risks remain, and therefore, at the time of writing, we are not releasing the Meta Chameleon image generation model.
◆2: Multi-token forecasting
The training goal of most LLMs is to improve the simple task of predicting the next word. While this approach is simple and scalable, it is also inefficient. For example, getting an LLM to achieve child-level fluency in a language requires a much larger amount of text than is needed to educate a child.
Therefore, Meta proposed an approach to building better LLMs using a technique called multi-token prediction . Training a language model using multi-token prediction enables it to predict multiple words at once. This improves the capabilities and training efficiency of the AI model, leading to faster response times. In the spirit of open science, Meta has released a pre-trained model for code completion under a non-commercial/research license.
◆3: Meta JASCO
The emergence of generative AI has led to the emergence of tools capable of generating music files from text. While existing AI models, such as MusicGen, primarily rely on text input for music generation, Meta JASCO (Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation) can accept various conditional inputs, such as specific chords or beats, to improve control over the generated musical output. Specifically, it applies an information bottleneck layer in combination with temporal blurring to extract relevant information about specific controls. This allows it to incorporate both symbolic and audio-based conditions, compared to AI models that generate music from the same text.
Meta has published JASCO research papers and plans to release the inference code under the MIT license as part of Meta's sound generation tool , AudioCraft , in late 2024.
◆4: AudioSeal
Generative AI tools encourage people to share their creations with friends, family, and social media followers. Meta stated, 'As with all AI innovation, it is our role to ensure the responsible use of these tools.' To that end, Meta has announced AudioSeal , a watermarking technology designed for speech-generating AI tools that enables accurate identification of AI-generated segments within longer audio snippets.
AudioSeal revolutionizes traditional audio watermarking technology by focusing on detecting AI-generated content rather than steganography . Unlike traditional methods that rely on complex decoding algorithms, AudioSeal's localized detection approach enables faster and more efficient detection. This improves detection speed by up to 485x compared to traditional methods, making AudioSeal suitable for use in large-scale real-time applications. Additionally, AudioSeal achieves cutting-edge performance for audio watermarking technology in terms of robustness and imperceptibility.

AudioSeal is released under a commercial license, and it is also used in the voice samples generated by SeamlessM4T v2 and Audiobox , which are basic text-to-voice translation models.
◆5: Partnership to support the release of the PRISM dataset
Obtaining feedback from diverse audiences is important for improving LLMs, but the research community has unresolved questions about the methods, scope, and purpose of the feedback process. Meta is working with external partners to address these issues and supported the release of the PRISM dataset, which maps the socio-demographics and preferences of 1,500 diverse participants from 75 countries. Meta is advising external partners on compiling the PRISM dataset by focusing conversations on interpersonal and cross-culturally contentious topics, centering on subjective and multicultural perspectives.
Meta demonstrates the usefulness of the PRISM dataset through three case studies on interaction diversity, preference diversity, and welfare outcomes, and points out that it is important which humans set the alignment criteria. Meta explains that it hopes the PRISM dataset will serve as a resource for the AI community, encouraging broader participation in AI development and promoting a more inclusive approach to technology design.
◆6: Measuring and improving geographic differences in text-to-image generation systems
Reflecting the geographic and cultural diversity of the world is crucial for AI models that can generate images from text. Improving these models requires new tools to help researchers better understand where existing models fall short.
Meta has developed an automatic metric called ' DIG In ' to assess potential geographic differences in text-to-image AI models, and is also conducting a large-scale annotation study to understand how people in different regions perceive geographic representations differently. Over 65,000 annotations and over 20 survey responses covering attractiveness, similarity, consistency, and common recommendations were collected to improve automated and human evaluation of text-to-image AI models.
This research shows that people use specific components within an image to recognize geographic representations in generated images, rather than looking at the image as a whole. As part of the collaborative approach at Meta FAIR, Meta is also leading a team of graduate students from the University of Massachusetts, Amherst, in a follow-up evaluation that decomposes the automated indicators deployed so far into foreground concepts and background representations.
Based on information from DIG In, we also explored ways to improve the diversity of output from text-to-image AI models. This resulted in a guidance called Contextualized Vendi Score , which expands on Meta's previously published feedback guidance work and uses inference-time intervention to guide state-of-the-art image generation AI models to increase the representational diversity of generated examples while maintaining or improving image quality and consistency of prompt generation.
Related Posts: