OpenAI develops GDPval, a benchmark that measures AI's real-world capabilities, enabling it to measure performance in real-world occupations such as lawyers and film directors

OpenAI has revealed that it is working on developing a benchmark called ' GDPval ' that measures the performance of AI by having it imitate the work of experts, based on the assumption of 'how a human expert would handle a task.'
GDPval.pdf
(PDF file)
Measuring the performance of our models on real-world tasks | OpenAI
https://openai.com/index/gdpval/
Even if an AI performs well on a math problem or coding task, it doesn't tell us how well it can be applied to everyday human activities. To validate these capabilities, real-life benchmarks are needed.
OpenAI has recently announced a new benchmark called GDPval, which measures how well AI can perform in tasks that humans actually do.
OpenAI selected 44 occupations from the top nine industries contributing to the US GDP, and extracted 1,320 specialized tasks performed in each occupation to be used as tests for GDPval.
Job types include real estate managers, government compliance officers, mechanical engineers and buyers in manufacturing, software developers, lawyers, nurses, pharmacists, financial analysts, private investigators, and film directors.
Tasks are designed based on real-world work artifacts, such as legal documents, blueprints, customer support conversations, and nursing care plans, and are rigorously crafted and validated by subject matter experts with an average of over 14 years of experience.

For example, if you were to validate a task for a manufacturing engineer in the manufacturing industry, you might be given prompts and materials like the following:
'You are a manufacturing engineer on an automotive assembly line. Your product is a cable reeling truck for underground mining operations, and you must perform final testing on the product. The final test requires that a large cable spool be reeled in and unreeled twice to check that the cable reeling works as required. In your current workflow, this test requires two people: one person carries the spool near the test rig and positions it, while the second person connects the open end of the cable spool to the test rig and begins reeling. The first person monitors the unreeling while the cable is unwound from the spool and wound onto the truck. The spool must be rotated to ensure smooth operation. After the cable is fully wound onto the track, the next step is to reverse the operation, unwinding the cable from the track and returning it to its original reel. This test is performed twice. The task is complex, risky, and labor-intensive. Your manager has tasked you with developing a device that will simplify the winding and unwinding of the cable and allow one person to perform the test. This task is accompanied by an information document detailing the device's dimensions, design information, and deliverable configuration. You are tasked with designing the device in 3D modeling software and creating a presentation in Microsoft PowerPoint. As a deliverable, you are only required to upload a design summary PDF document with a snapshot of your 3D design; you do not need to submit the 3D design files.
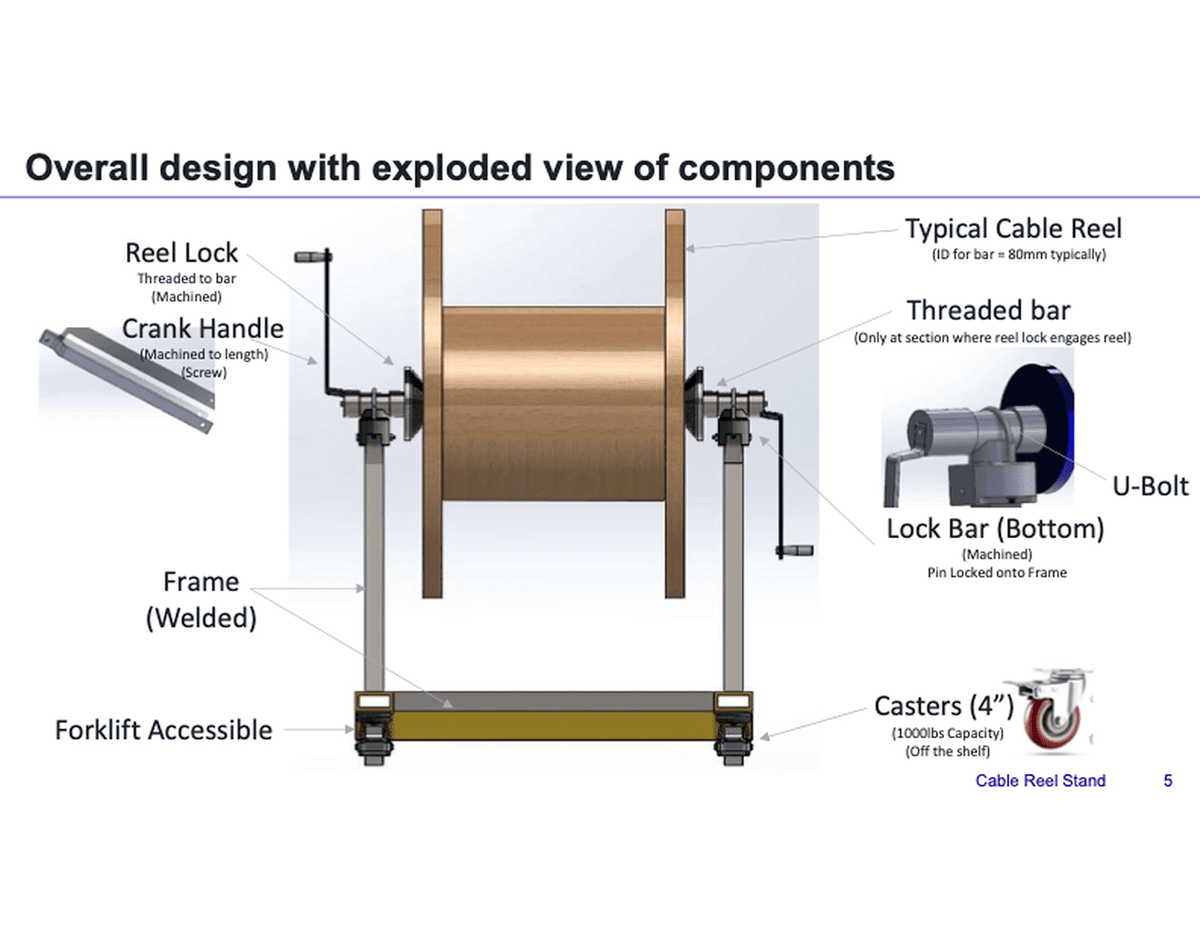
OpenAI explains, 'Unlike traditional benchmarks, GDPval tasks go beyond simple text prompts. They include attachments and context around the task, and the expected deliverables are diverse, including documents, slides, charts, and spreadsheets.'
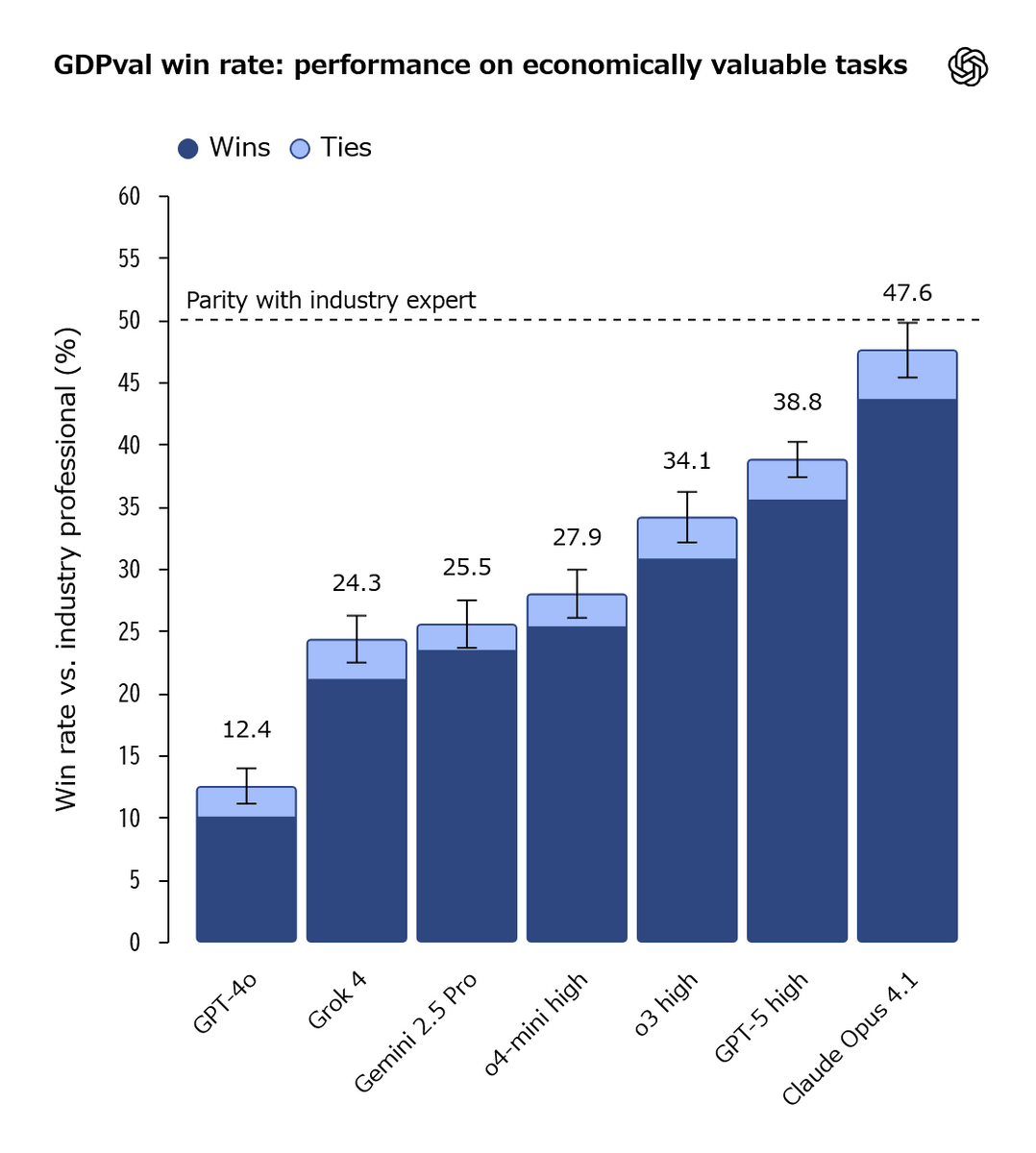
Initial testing involves blind evaluations comparing the work of GPT-4o, o4-mini, OpenAI o3, GPT-5, Claude Opus 4.1, Gemini 2.5 Pro, and Grok 4 with human-generated work.
The percentage of outcomes where the AI was deemed to have beaten humans (dark blue) and the percentage of outcomes where it was deemed to have drawn (light blue) are shown for each model. While most models lost to humans, some state-of-the-art models, such as Claude Opus 4.1, produced outcomes that approached humans.
Each model excelled in different areas, with Claude Opus 4.1 particularly excelling in aesthetic elements such as document formatting and slide layout, while GPT-5 excelled in accuracy.
In terms of performance, there is a more than double difference between GPT-4o, which will be released in spring 2024, and GPT-5, which will be released in summer 2025, so it is expected that the record could be broken in just a few years.
OpenAI emphasized that 'state-of-the-art models can complete tasks approximately 100 times faster and at 100 times lower cost than experts.' However, they added that the speed and price of AI do not include the human supervision and replication required to utilize the results in real-world environments. OpenAI stated, 'Still, we expect that time and money can be saved by entrusting AI with tasks that each model excels at before humans try them.'
GDPval is in its early stages and will continue to be improved to expand the range of jobs and tasks and improve the meaningfulness of the results.
Related Posts: