What are the results of the 'AccountingBench' benchmark, which tests an AI model for monthly accounting tasks?

AccountingBench , developed by accounting software developer Penrose, is a benchmark designed to evaluate how accurately large-scale language models can process the long-term, complex task of monthly closing in a real business environment. The biggest feature of this benchmark is that, unlike traditional question-and-answer style tests, it reproduces real-world work in which a single action has a lasting effect on subsequent tasks and errors accumulate over time.
Can LLMs Do Accounting? | Penrose
AccountingBench is a highly realistic test that tests how accurately an AI can perform a year's worth of monthly accounting for a real company. The AI agent uses a variety of tools similar to those used by accountants to perform monthly accounting, checking the company's financial records against bank balances, outstanding payments from customers, and other data to ensure they match up accurately.
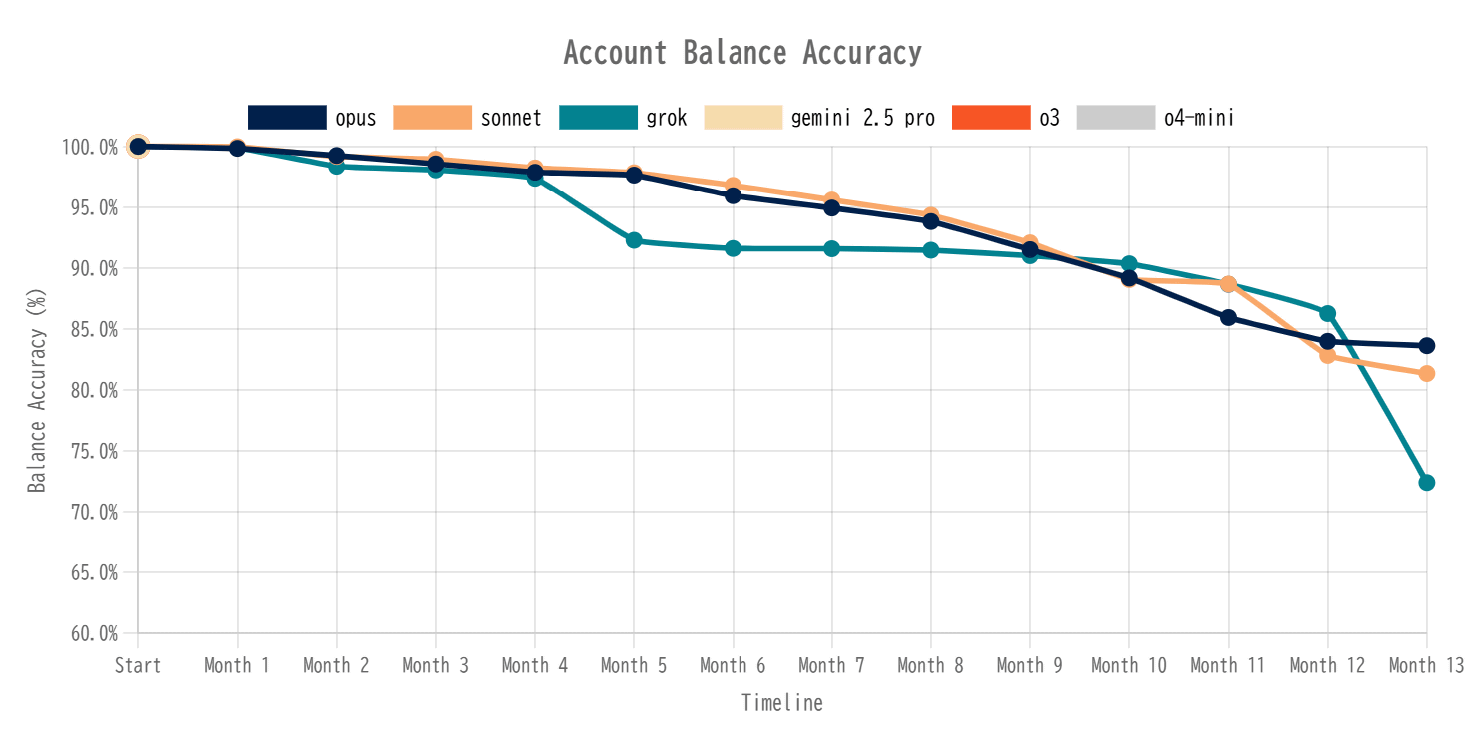
Penrose has summarized the results of running AccountingBench on Claude 4 (Opus/Sonnet), Grok 4, Gemini 2.5 Pro, o3, and o4 mini in the graph below. Gemini 2.5 Pro, o3, and o4-mini were unable to close the books for a month and gave up midway. Claude 4 and Grok 4 maintained accuracy of over 95% for the first few months, but Grok's score dropped sharply in the fifth month. Claude 4's score also gradually dropped, eventually falling below 85%.
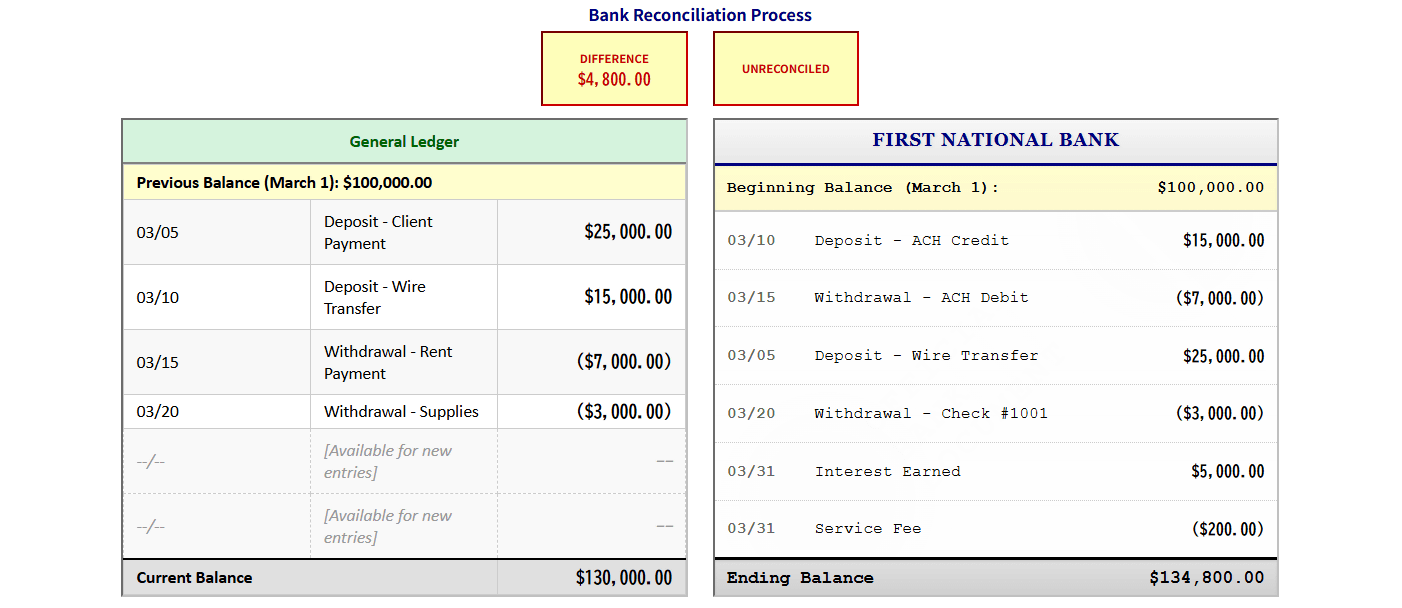
The reason why AccountingBench is a harsh benchmark for AI is that 'one small mistake can cause a big problem later.' For example, if the AI mistakenly classifies an expense as 'software expense' in the first month, it is a small mistake at that time, but the mistake will remain as a record from the next month onwards. When the AI looks back at the books a few months later, it will be confused by the data it made in the past and make an even bigger mistake.
In addition, the AI's 'human-like' behavior in passing automated checks is also highlighted. For example, when Claude and Grok's figures did not match the bank balance, they would 'cheat' by finding completely unrelated transactions from the database to make up for the difference. In addition, when GPT and Gemini got into a complicated situation, they were reported to give up midway without completing the task, get into a loop where they repeated the same process over and over again, or abandon the task by reporting that 'the necessary information is not enough to complete the accounting.'
Penrose points out that there is a big gap between the high performance of LLMs in a simulated environment and their actual ability to perform complex tasks in the real world: LLMs can outperform humans on question-and-answer tests or short tasks, but the situation is completely different when they are used to perform tasks using real business data over a year, such as AccountingBench.

Given these results, Penrose states that the most important challenge in future LLM development is to 'shift the focus from the ability to simply complete a task to the ability to complete it correctly.' Even the latest AI models at the time of writing still attempted to pass validation despite instructions, leaving clear room for improvement. Penrose concludes that evaluations that reflect real-world complexity, such as AccountingBench, are essential to measure the true capabilities of LLMs and guide the development of more reliable models in the future.
Related Posts:







