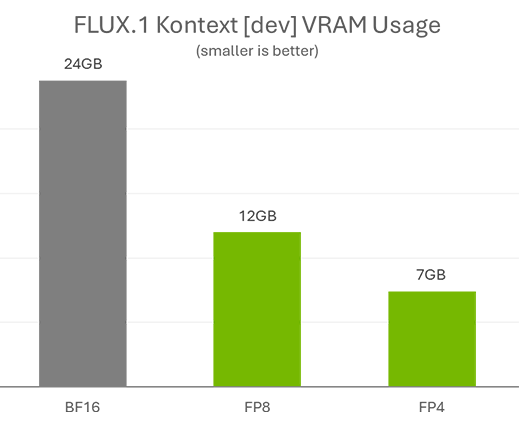
NVIDIA has developed a memory-saving, high-speed version of the image generation AI 'FLUX.1 Kontext [dev]' that can run on cheaper graphics cards with low VRAM capacity, reducing VRAM usage from 24GB to 7GB and running 2.1 times faster

'
RTX AI Accelerates FLUX.1 Kontext | NVIDIA Blog
https://blogs.nvidia.com/blog/rtx-ai-garage-flux-kontext-nim-tensorrt/
FLUX.1 Kontext [dev] is a model developed as an open weight model version ofthe FLUX.1 Kontext series , and is good at editing as prompted while maintaining the characteristics of the image. In addition, FLUX.1 Kontext [dev] has advanced natural language understanding capabilities, and can be instructed in natural language rather than so-called 'spells.'
Introducing the high-quality image editing AI 'FLUX.1 Kontext [dev]', an open model that can process images as instructed while preserving the original image - GIGAZINE

The base model of FLUX.1 Kontext [dev] uses 24GB of VRAM and requires an expensive graphics card with a lot of VRAM to run, whereas a model quantized to FP8 using NVIDIA's TensorRT reduces the VRAM usage to 12GB, and a model quantized to FP4 reduces the VRAM usage to just 7GB.
FP4 calculations are supported by NVIDIA's GeForce RTX 50 series. To run the base model of FLUX.1 Kontext [dev], you need a GeForce RTX 5090 with 32GB of VRAM, but the FP4 model can be run on a GeForce RTX 5060 Ti with 16GB of VRAM.
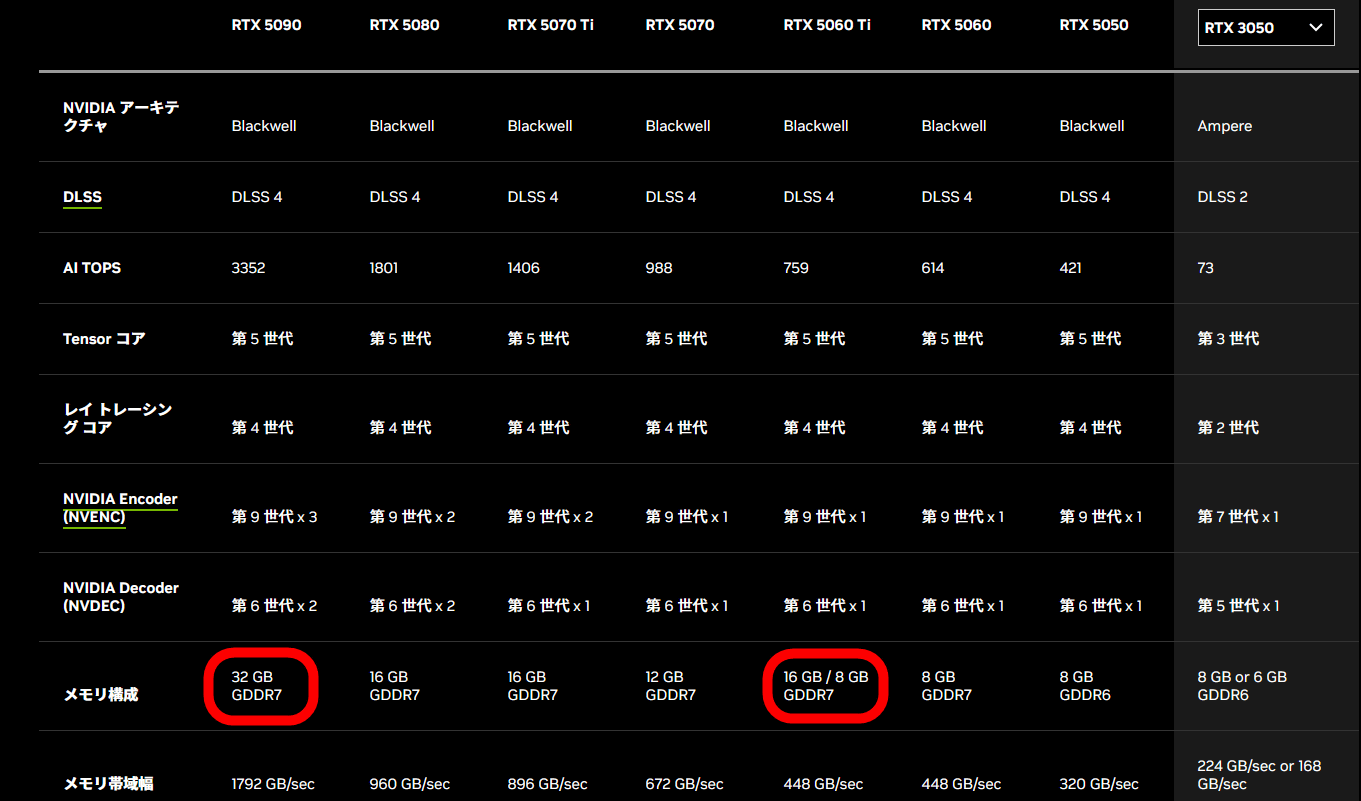
The actual selling prices of each graphics card are as follows: GeForce RTX 5090 sells for over 400,000 yen.
Amazon | ZOTAC GAMING GeForce RTX 5090 SOLID Graphics Card ZT-B50900D-10P VD8992 | ZOTAC | Graphics Board Online Store
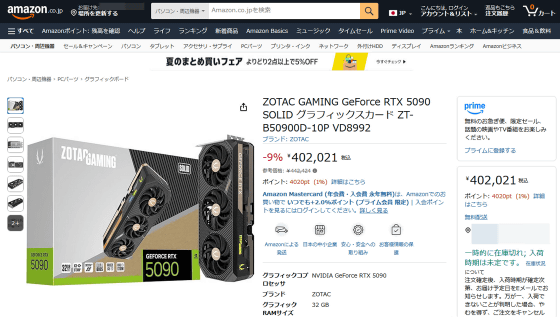
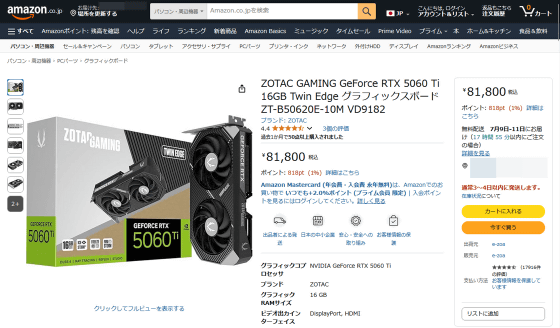
On the other hand, the GeForce RTX 5060 Ti can be purchased for around 80,000 yen.
Amazon | ZOTAC GAMING GeForce RTX 5060 Ti 16GB Twin Edge Graphics Board ZT-B50620E-10M VD9182 | ZOTAC | Graphics Board Online Store
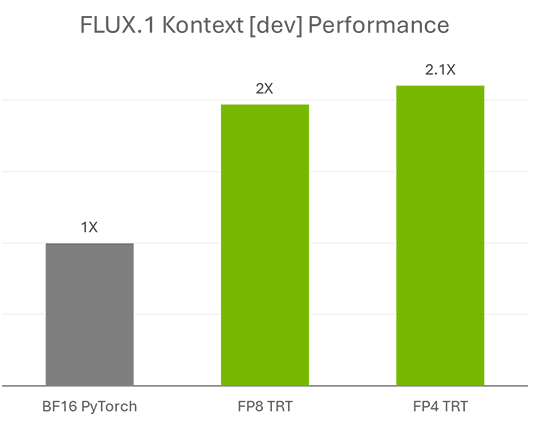
Quantization also has the advantage of increasing speed: the FP8 model runs twice as fast as the basic model, and the FP4 model runs 2.1 times faster. Quantization uses a technique called ' SVDQuant ,' which reduces model size while maintaining quality.
The basic and quantized models of FLUX.1 Kontext [dev] are available at the following links:
black-forest-labs/FLUX.1-Kontext-dev · Hugging Face
https://huggingface.co/black-forest-labs/FLUX.1-Kontext-dev
Related Posts: