Apple details the limitations of top-level AI models and large-scale inference models like OpenAI's 'o3'

Apple published a paper titled 'Illusions of Thought: Understanding the Strengths and Limitations of Inference Models Through the Lens of Problem Complexity.' The researchers tested 'inference' models such as Anthropic's Claude, OpenAI's o model, DeepSeek-R1, and Google's model to verify how well they could reproduce human reasoning, but the scale-up of AI inference capabilities was not as advertised in marketing.
the-illusion-of-thinking.pdf
(PDF file)
A knockout blow for LLMs? - by Gary Marcus - Marcus on AI
https://garymarcus.substack.com/p/a-knockout-blow-for-llms
Apple Study Calls Out “Reasoning” AI as Overhyped While Siri Struggles - 9meters
https://9meters.com/technology/ai/apple-study-calls-out-reasoning-ai-as-overhyped-while-siri-struggles
Thinking AI models collapse in face of complex problems, Apple researchers find - Hindustan Times
https://www.hindustantimes.com/business/thinking-ai-models-collapse-in-face-of-complex-problems-apple-researchers-find-101749305499965.html
In their paper, Apple researchers evaluated various models using the famous board game ' Tower of Hanoi .' In the Tower of Hanoi, players stack several disks of various sizes on three pillars, and under the rule that 'you cannot place a disk larger than yourself on top of any other disk,' players must move all the disks stacked on the left pillar to the right pillar.

The Tower of Hanoi is easy for humans to solve with practice, and even computers programmed to solve it can do it. However, AI that claims to be able to use 'reasoning' has almost never been able to solve it, even though there are many source code libraries for solving the Tower of Hanoi available for free on the Internet.
For example, when Anthropic's AI 'Claude 3.7 (with inference)' plays a game with seven discs, its accuracy rate falls below 80% (bottom left of image). It can barely clear the eight-disk version, which requires a minimum of 255 moves to complete.
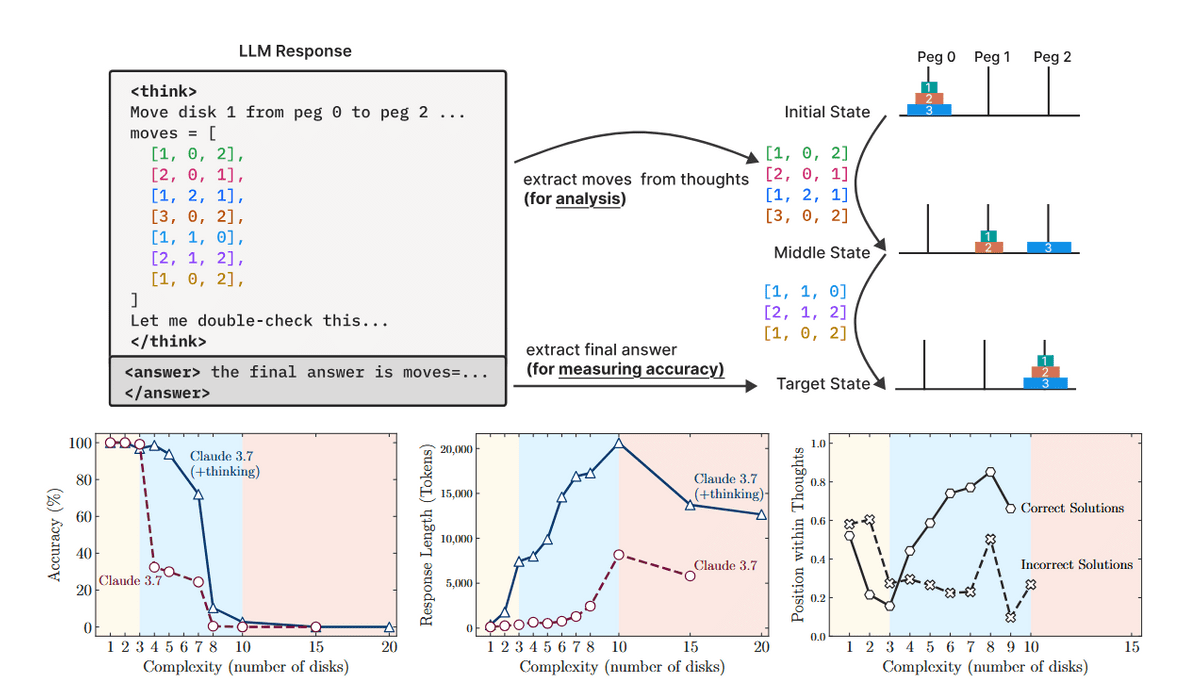
Furthermore, the AI did not appear to use any deductive or symbolic reasoning while solving these puzzles, but instead inferred based on patterns it had seen during training. In other words, it did not 'look at the Tower of Hanoi game, understand the system, and derive a solution' as humans do, leading the researchers to question whether this can really be called 'inference' as advertised.
General AI benchmarks often rely on mathematical or coding benchmarks that focus primarily on the accuracy of the final answer, with limited insight into the inference process itself. To address these gaps, researchers have used the Tower of Hanoi and
Essentially, large-scale language models (LLMs) that do not perform inference are more accurate and use 'tokens' more efficiently at lower complexity levels, while inference models perform better as complexity increases, but the accuracy of answers decreases as problem complexity increases, even for inference models.
'We do not know whether these models are capable of general inference that can be applied to any problem, or whether they simply rely on pattern matching,' the researchers wrote. 'Increased inference ability does not necessarily imply greater intelligence.'

Renowned artificial intelligence expert Gary Marcus said, 'The point is that LLMs are not a replacement for good, well-specified conventional algorithms. They can't play chess as well as conventional algorithms, and they can't fold proteins . Hopefully, you can write Python code and compensate for your own weaknesses with external code, but they're still not reliable. This means that for business and society, simply throwing o3 or Claude at a complex problem won't guarantee that it will work. For at least the next decade, LLMs (with or without inference) will continue to be used, especially in coding, brainstorming, and writing. But anyone who thinks that LLMs are a direct path to the kind of general-purpose artificial intelligence (AGI) that can fundamentally change society for the better is vain.'
Continued
AI experts refute Apple's 'limits to AI inference capabilities' - GIGAZINE
Related Posts:







