It is clear that the state-of-the-art large-scale language model (LLM) has a zero percent chance of solving difficult coding problems in one shot, and is still no match for skilled people such as competitive programmers

The coding capabilities of large-scale language models (LLMs) are so high that technology company leaders have said things like, '
Paper page - LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
https://huggingface.co/papers/2506.11928
[2506.11928] LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
https://arxiv.org/abs/2506.11928
There are reports that LLMs outperform human competitive programmers in competitive programming. AI researchers who were skeptical of this have built a benchmark called ' LiveCodeBench Pro '. LiveCodeBench Pro is a benchmark consisting of problems from the world-famous competitive programming site Codeforces , the international university programming contest ICPC , and IOI (International Olympiad in Informatics), which determines the world's best competitive programmer, and is scheduled to be continuously updated to reduce the possibility of data contamination.
LiveCodeBench Pro
https://livecodebenchpro.com/
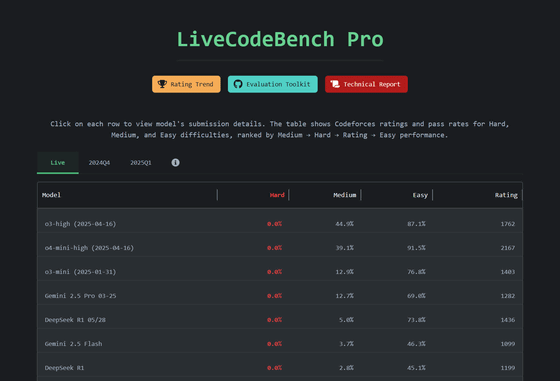
In LiveCodeBench Pro, a team of International Olympiad medalists annotated every problem in the algorithm category , and if the LLM failed to solve it, the team of medalists analyzed the code output by the LLM line by line.
Testing several state-of-the-art LLMs with LiveCodeBench Pro revealed that without external tools, even the best LLMs had a pass@1 rate of 53% for medium-difficulty problems. Furthermore, for difficult problems, the pass@1 rate was zero%, demonstrating that more skilled programmers performed better on difficult problems.
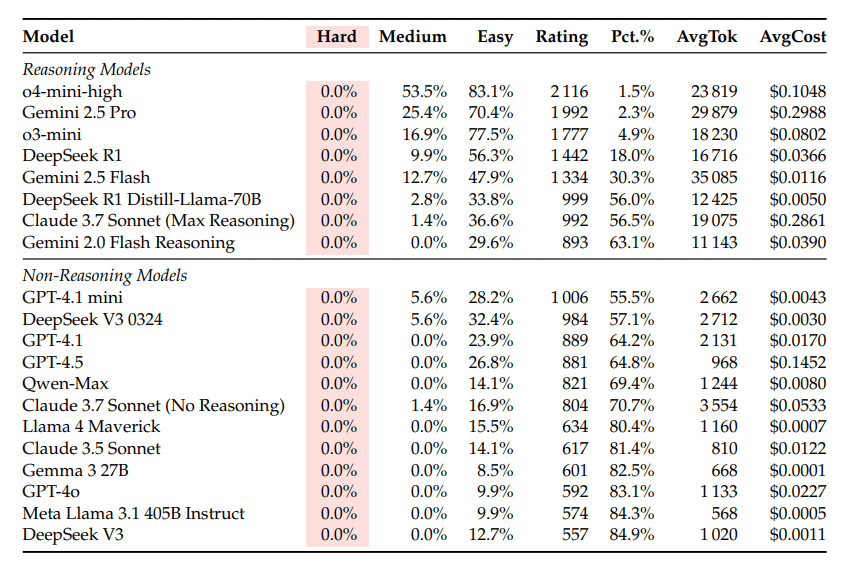
The table below summarizes the accuracy rate of each LLM when solving 'hard', 'medium', and 'easy' problems in LiveCodeBench Pro. Since none of the LLMs were able to give a correct answer to the high difficulty problem, it is displayed as '0.0%'. In addition, LiveCodeBench Pro evaluates the performance of LLMs in a score format (Rating) based on the Elo rating of chess, and even OpenAI's state-of-the-art LLM, o4-mini-high, has a score of 'about 2100'. A score of '2700' or higher is evaluated as a human competitive programmer with excellent skills.
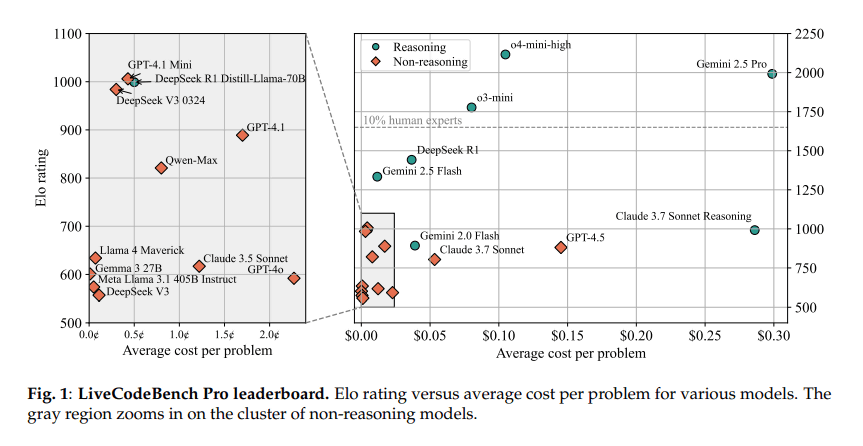
The graph below shows the score for each LLM (vertical axis: Elo rating) and the cost of answering (horizontal axis: average cost per problem).
On the other hand, while LLMs can correctly answer implementation- focused questions, they struggle with nuanced algorithmic reasoning and complex case analysis, and often produce overconfident and incorrect answers.
From this, the research team concluded that 'high performance appears to depend not so much on good inference, but on implementation accuracy and tool extensions. LiveCodeBench Pro highlights the significant gap with human experts while providing fine-grained diagnostic capabilities to guide future improvements in code-centric LLM inference.'
'This is very bad news for LLMs' coding skills. The state-of-the-art LLMs get zero percent correct on difficult real-world programming contest problems, areas where experts still excel,' said AI engineer Rohan Paul, pointing out that LLMs still can't compete with highly skilled humans at difficult programming tasks.
This is really BAD news of LLM's coding skill. ☹️
— Rohan Paul (@rohanpaul_ai) June 16, 2025
The best Frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel.
LiveCodeBench Pro, a benchmark composed of
problems from Codeforces, ICPC, and IOI (“International… pic.twitter.com/Z3QxhyFxNf
Related Posts:







in Software, Posted by logu_ii