




富士通がAI効率を475倍にするTransformer代替アーキテクチャ「PHOTON」を開発

2026年6月24日、富士通が大規模言語モデル(LLM)の大幅なコスト削減を実現するアーキテクチャ「Parallel Hierarchical Operation for TOp-down Networks(PHOTON)」を発表しました。LLMの基盤アーキテクチャであるTransformerと比較して、GPUリソース当たりのスループットを最大475倍に改善します。
Transformerと比較し、GPU当たり最大475倍の出力トークン数を持つ新アーキテクチャを開発 | 富士通
https://global.fujitsu/ja-jp/technology/research/article/topics/202606-photon-architecture
TransformerはGoogleの研究者が2017年に発表した深層学習アーキテクチャで、多くのAIで使用されています。しかし、Transformerには「入力が長くなったり、同時に多くの問い合わせを処理したりすると、過去の情報を保持するためのメモリアクセスが増え、処理速度が落ちやすい」などの課題がありました。Transformerでは特に長い文書を扱う場合や、多数のユーザーから同時利用がある場合に、この課題が顕著になります。
これに対して、富士通の開発したPHOTONはマルチエージェントのような複数の入出力を必要とする処理を低コストで効率的に処理することが可能です。PHOTONの特徴は大まかに以下の2つ。
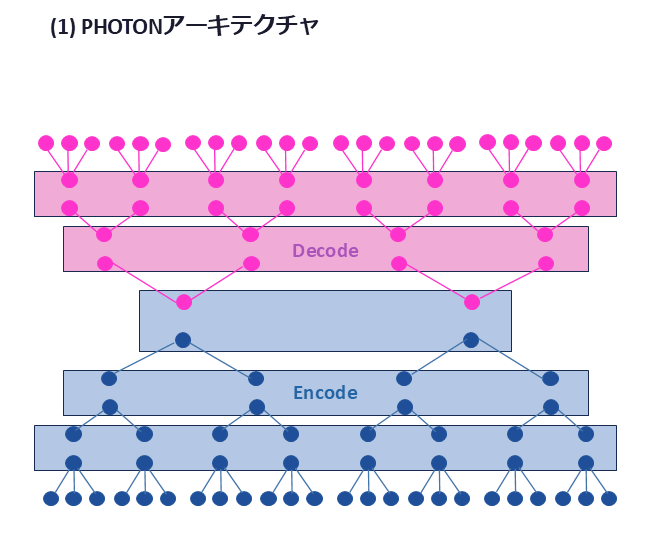
◆トークン単位ではなく、意味単位で階層的に処理
Transformerは文章を細かなトークンに分解し、それぞれすべての関係を計算します。一方、PHOTONは文章を意味のまとまりとして捉え、階層的に処理することで計算量を削減する仕組みです。さらに、複数の文章を同時に処理することで、GPU当たり最大475倍の計算効率を発揮します。
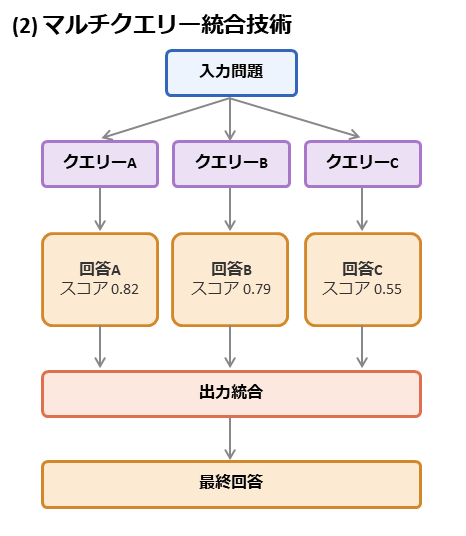
◆大量の出力を統合することで性能を向上するマルチクエリー統合技術を採用
マルチクエリー統合技術は、同じ問題に対して少しずつ異なる複数の質問や候補を作り、その結果をまとめて最終的な答えを決める技術です。PHOTONでは、多数決や最も良い候補を選ぶ方法などで結果を統合することで、1回の推論だけで、より安定した高い性能を実現します。
数値実験の結果、PHOTONはパラメーターサイズが6億、9億、12億の各モデルに対して、従来のTransformerと比較して、メモリ使用量を抑えながら高い生成スループットを実現しました。特に、12億パラメーターのモデルでは、わずかな性能劣化と引き換えに従来のTransformerと比べて最大475倍のマルチクエリー計算能力(GPUリソース当たりのスループット)を実現しています。
さらに、PHOTONでは1回当たりの生成に必要なKVキャッシュ使用量が小さいため、同じGPUメモリ予算内で複数の生成結果を並列に得ることができます。検証ではわずか9クエリーを統合することで従来のTransformerと同水準の性能を実現しました。
なお、富士通は2026年7月2日から7月7日にかけてアメリカのサンディエゴで開催される自然言語分野のトップカンファレンスである「ACL 2026」のオーラルセッションで詳細を発表予定です。
・関連記事
Microsoftが「AIへの質問1回の消費電力量は電子レンジを数秒動かす程度」と主張、従来推定の最大20分の1 - GIGAZINE
AIのメモリ使用量を6分の1に削減するGoogleの「TurboQuant」はメモリ需要を減少させるどころか増加させるとの指摘 - GIGAZINE
AIのトレーニングに必要なデータ量を1万分の1に減らす画期的な方法をGoogleが発表 - GIGAZINE
AIによる画像生成を30倍高速化する手法をマサチューセッツ工科大学が開発 - GIGAZINE
・関連コンテンツ







in AI, Posted by logu_ii
You can read the machine translated English article Fujitsu develops 'PHOTON,' a Transformer….