




2万基のGPUを同時管理するクラウド企業がGPUクラスタの安定性の低さを解説

クラウドコンピューティング企業はAIの開発や運用に役立つGPUクラスタを製品として展開しています。そんなクラウドGPUの安定性について、これまでに400万基以上のGPUインスタンスを管理してきたModalが解説しています。
Keeping 20,000 GPUs healthy
https://modal.com/blog/gpu-health
Modalは「Amazon Web Services(AWS)」「Google Cloud(GCP)」「Microsoft Azure」「Oracle Cloud Infrastructure(OCI)」といった大手クラウド企業からコンピューティングリソースを調達してGPUクラウドサービスを展開しています。記事作成時点では2万基のGPUを同時に管理しており、過去数年間で管理したGPUの数は400万基を超えています。
Modalは「クラウドA」「クラウドB」「クラウドC」「クラウドD」と名前を伏せつつ、各クラウド企業の特徴を以下のように説明しています。
・クラウドAのインスタンス起動APIは最もシンプルで信頼性が高い。ベアメタルもしくは仮想マシンにリクエストしてHTTP 201が返ってきた場合、99.6%の確率で起動に成功し、起動時間は2~3分と比較的短時間である。
・クラウドAのH100で画像生成AIのStable Diffusionを実行した場合、クラウドCやクラウドDと比べてパフォーマンスが50%低くなる。
・クラウドCでは2025年の数カ月間にH100が非常に高温になり、90度を超えることもあった。温度が70度後半に達すると処理性能が低下し始める。
・クラウドCのH100は他のクラウドより228MiB多くメモリを予約する。このため、ユーザーが使用できるメモリが少なくなる。
・クラウドDのA10ではクロック周波数の低下が頻繁に発生する。
・クラウドDのアメリカリージョンの1つのA10では修正不可能なECCエラーが頻繁に発生する。
・クラウドDはコストパフォーマンスが最も良好。特にベアメタルサーバーは最高である。
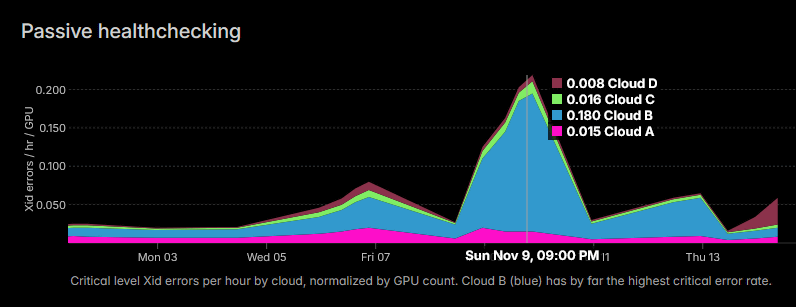
上記の特徴からも分かる通り、GPUクラウドサービスはCPUクラウドサービスと比べて全体的に信頼性が低いとのこと。以下のグラフは1時間ごとのエラー発生率をクラウド別に示したもので、2025年11月9日にはクラウドBで0.18という高いエラー率を記録したことが分かります。
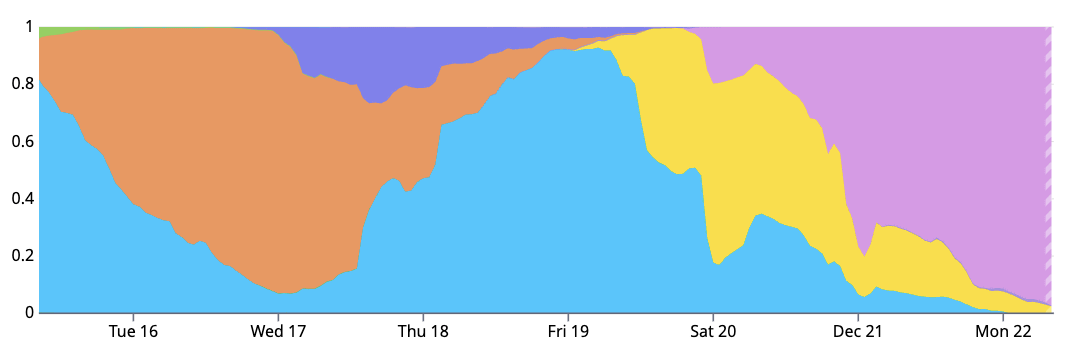
また、GPUクラウドではマシンイメージのバージョンによって信頼性が大きく変化することも確認されています。以下のグラフはある1週間におけるマシンイメージのバージョン推移を示したもので、各色が異なるバージョンを表しています。グラフ左端の月曜日頃から「青色バージョンからオレンジ色バージョンへのアップデート」が始まったものの、オレンジ色バージョンで問題が発生し、水曜日を境に青色バージョンへのロールバックが必要となったことが分かります。
Metaが発表したLlama3のトレーニングに関するレポートでも「予期せぬ問題の58.7%がGPUに由来するものだった。一方で、CPUに由来する問題は0.5%だった」ということが報告されています。これらの結果をもとに、Modalは「GPUの性能は驚異的ですが、信頼性が足かせとなっています」と結論付けています。
・関連記事
半導体業界は前例のない「ギガサイクル」に突入、AIの大規模な発展によりコンピューティング・メモリ・ネットワーク・ストレージの経済性が同時に高まる - GIGAZINE
「データセンター」の中身はどうなっているのか? - GIGAZINE
NVIDIAがジョブスケジューラー「Slurm」の開発企業を買収、AIやHPCのエコシステム強化へ - GIGAZINE
TPU vs GPU、なぜGoogleは長期的にAI競争に勝てる立場にあるのか? - GIGAZINE
AIブームによってSSD価格が急騰して重量当たりの価格が「金」に匹敵するレベルに - GIGAZINE
2026年は供給されるメモリの最大70%をデータセンターが消費し他分野にも品不足が波及へ - GIGAZINE
・関連コンテンツ








in ハードウェア, Posted by log1o_hf
You can read the machine translated English article A cloud company managing 20,000 GPUs sim….