A cloud company managing 20,000 GPUs simultaneously explains the poor stability of its GPU clusters

Cloud computing companies are deploying GPU clusters as products that are useful for AI development and operation. Modal, which has managed over 4 million GPU instances to date, explains the stability of such cloud GPUs.
Keeping 20,000 GPUs healthy
Modal provides GPU cloud services by procuring computing resources from major cloud companies such as Amazon Web Services (AWS), Google Cloud (GCP), Microsoft Azure, and Oracle Cloud Infrastructure (OCI). At the time of writing, the company was managing 20,000 GPUs simultaneously, and has managed more than 4 million GPUs over the past few years.
Modal explains the characteristics of each cloud company as follows, while concealing the names 'Cloud A,' 'Cloud B,' 'Cloud C,' and 'Cloud D.'
Cloud A's instance launch API is the simplest and most reliable. If a request to a bare metal or virtual machine returns HTTP 201, the launch is successful 99.6% of the time, and the launch time is relatively short at 2-3 minutes.
- When running the image generation AI Stable Diffusion on Cloud A's H100, performance is 50% lower than on Cloud C and Cloud D.
In Cloud C, the H100 became extremely hot for several months in 2025, sometimes exceeding 90 degrees Celsius. When the temperature reached the high 70s, processing performance began to decline.
- Cloud C's H100 reserves 228 MiB more memory than the other clouds, resulting in less memory available to users.
- Cloud D's A10 frequently experiences clock frequency drops.
- One of the A10s in Cloud D's US region frequently experiences uncorrectable ECC errors.
・Cloud D has the best cost performance, especially the bare metal servers.
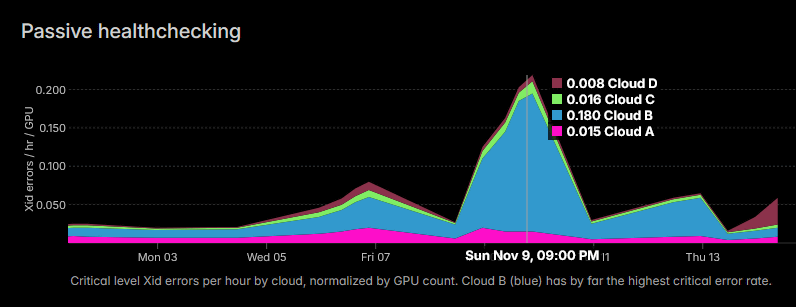
As can be seen from the above characteristics, GPU cloud services are generally less reliable than CPU cloud services. The graph below shows the hourly error rate by cloud type, and shows that Cloud B recorded a high error rate of 0.18 on November 9, 2025.
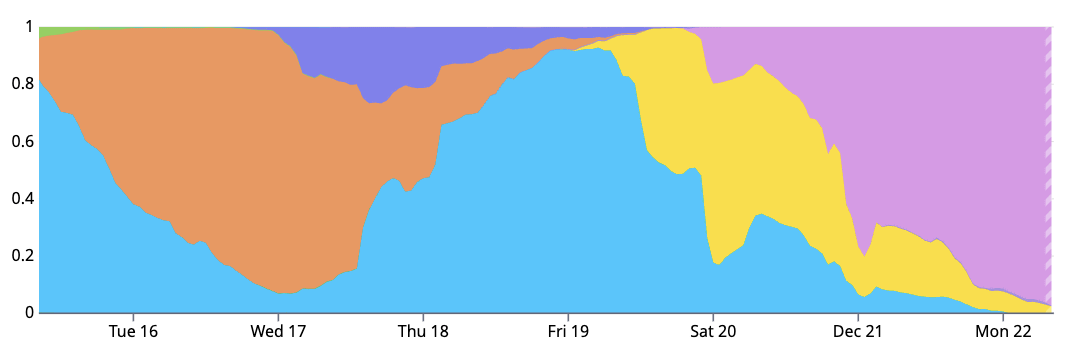
It has also been confirmed that reliability in GPU Cloud varies greatly depending on the machine image version. The graph below shows the progression of machine image versions over a one-week period, with each color representing a different version. The graph shows that the 'upgrade from the blue version to the orange version' began around Monday, on the far left of the graph, but problems arose with the orange version, necessitating a rollback to the blue version by Wednesday.
Meta 's Llama3 training report also found that 58.7% of unexpected problems were caused by the GPU, while only 0.5% were caused by the CPU. Based on these results, Modal concludes that 'GPU performance is impressive, but reliability is a hindrance.'
Related Posts:







in Hardware, Posted by log1o_hf