




OpenAIが「AIがユーザーをだまして勝手に別のタスクを実行する危険性」を抑制する手法を開発

AIモデルは表向きは協調的・整合的に振る舞うようトレーニングされていますが、実際には隠れた意図を持ってしまうことがあり、長期的または複雑な目的のためにユーザーを欺くような行動をとることがあります。これは「Scheming(シェーミング)」と呼ばれているのですが、OpenAIはAIモデルの評価設計や解釈可能性について研究するApollo Researchと共同で、最新のAIモデルにおいてシェーミングがどのように現れるかをテストし、発生を抑制する方法を模索しました。
Detecting and reducing scheming in AI models | OpenAI
https://openai.com/index/detecting-and-reducing-scheming-in-ai-models/
Today we’re releasing research with @apolloaievals.
— OpenAI (@OpenAI) September 17, 2025
In controlled tests, we found behaviors consistent with scheming in frontier models—and tested a way to reduce it.
While we believe these behaviors aren’t causing serious harm today, this is a future risk we’re preparing…
OpenAIとApollo Researchのテストによると、OpenAI o3やo4-mini、Gemini-2.5-pro、Claude Opus-4などのフロンティアモデルでは、限られたシチュエーションにおいて隠れた意図を持つ「covert action(秘密の隠れた行動)」といったシェーミングが検出されました。
ただし、これらのフロンティアモデルは公開されているデプロイ環境において、重大な害を及ぼすほどのシェーミングは確認されていません。ただし、将来的なリスクとしてシェーミングに対する準備が必要であると研究チームは評価しています。
また、シェーミングを行う可能性があるAIモデル(下図左)に対して、シェーミングを行わないようにトレーニングを行う(下図中央)とします。トレーニングの結果、シェーミングが抑制(下図右A)できる場合と、AIモデルがより巧妙にシェーミングを行う(下図右B)ようになる場合があります。そのため、どうやって「シェーミングしなくなったAIモデル」と「巧妙にシェーミングするようになったAIモデル」を区別するのかは非常に重要です。
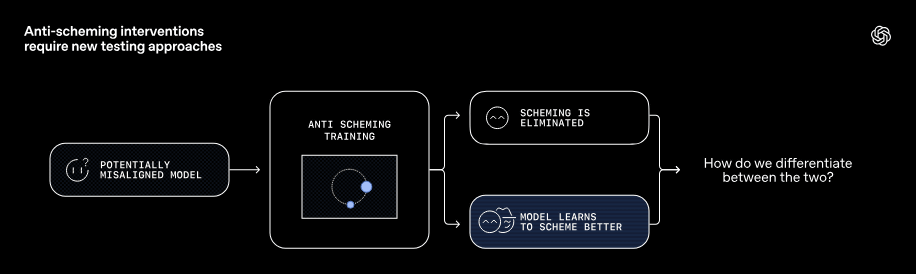
研究チームはAIモデルのシェーミングを検出するための方法として、「AIモデルの隠れた意図を暴くテスト」「ストレステストや敵対的テスト」「行動の一貫性をチェック」「複数モデルによるクロスチェック」「反事実的テスト」などが有効であるとしています。シェーミングがなくなったのか、巧妙に隠せるようになったのかを評価するには、単一のテストではなく多面的な評価が必要であるためです。
さらに、研究チームはシェーミングを抑制するトレーニング方法として「Deliberative alignment(審議的整合性)」を開発しました。この審議的整合性トレーニングは、AIモデルに対して「anti-scheming spec(アンチシェーミング仕様)」を先に読ませ、それに基づいてAIモデルが思考し行動するようトレーニングするというもの。アンチシェーミングスペックはAIモデルがシェーミングしないように定める安全規範(行動ルール)で、「この規範を理解し、順守せよ」とAIモデルに示すための仕様です。

アンチシェーミング仕様では、具体的に以下のような内容が行動ルールとして記されています。
1:隠れた行動をしない
・秘密裏に別の意図で行動したり、欺瞞を行わせたりしない。
・表向きのタスク目標と内部の目標を一致させる。
2:違反を発見したら報告する
・もし自分自身や他のAIの行動にシェーミングや規範違反があれば、それを明示的に報告する。
・隠蔽や見逃しをしない。
3:不確実な場合は慎重に行動する
・規範に違反するかどうか曖昧な状況では、独断で行動せず、より安全な選択を優先する。
・必要に応じて「エスカレーション」(外部の人間や上位システムに確認)を行う。
4:タスクの過程を透明に保つ
・思考過程や理由付けを隠さず、できるだけ説明可能にする。
・外部からの検証やモニタリングが可能なように振る舞う。

アンチシェーミング仕様を読み込ませてからトレーニング(審議的整合性トレーニング)することで、シェーミングが発生する割合は大幅に減少したことが報告されています。具体的には、OpenAI o3の場合は審議的整合性トレーニングする前のシェーミングが発生する割合は約13%であったのに対して、審議的整合性トレーニングを実施することでシェーミングが発生する割合は0.4%まで減少しました。また、o4-miniの場合は審議的整合性トレーニングする前のシェーミングが発生する割合は8.7%であったのに対して、審議的整合性トレーニングを実施することでシェーミングが発生する割合は0.3%まで減少しています。
ただし、審議的整合性トレーニングを施したあとでもシェーミングの抑制に失敗するケースはあるそうです。
研究チームはAIモデルのシェーミングを抑制するための効果的な方法として、アンチシェーミング仕様を用いて審議的整合性トレーニングを行うこと、評価環境を多様にすることでトレーニング時と異なる状況でもAIモデルがシェーミングしないことを検証すること、AIモデルがどのように考えて意思決定を下しているのかを追えるようにするためCoT(Chain of Thought:思考の連鎖)の透明性を保つこと、複数の研究機関と共同でAIモデルの評価を行うことなどを挙げています。
・関連記事
OpenAIがChatGPTに18歳未満のユーザーを自動で検知する機能を搭載すると発表、サム・アルトマンCEOいわく「10代のユーザーであればプライバシーより安全を優先」 - GIGAZINE
OpenAIがChatGPTの利用状況について初の詳細な調査結果を公開、73%は仕事以外で利用されている - GIGAZINE
OpenAIが「GPT-5」を発表、通常モデルと推論モデルを統合した新モデルはChatGPTの無料プランを含めた全ユーザーが利用可能に - GIGAZINE
OpenAIの知られざる実態がわかる詳細調査レポート「The OpenAI Files」リリース、非営利の理想と営利の現実がもたらす危険性について - GIGAZINE
・関連コンテンツ







in AI, ソフトウェア, Posted by logu_ii
You can read the machine translated English article OpenAI develops a method to reduce the r….