




Cloudflareが「Perplexityがステルス戦術を使ってクロール禁止命令を無視している」と非難
AI検索エンジンとして知られるPerplexityが、ウェブサイト運営者の意向に反する形で、正体を隠したステルス性のクローラーを用いて情報を収集していたと、Cloudflareが報告しました。Perplexityは申告済みのユーザーエージェント(識別情報)によるアクセスがブロックされると、別の未申告のユーザーエージェントに切り替えて、ウェブサイトのクロール拒否指示を回避しようと試みていました。
Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives
https://blog.cloudflare.com/perplexity-is-using-stealth-undeclared-crawlers-to-evade-website-no-crawl-directives/
この調査は、robots.txtファイルやファイアウォールでPerplexityのアクセスを明確に拒否していたにもかかわらず、コンテンツにアクセスされ続けているというウェブサイト運営者からの苦情を受けて開始されました。
Cloudflareの調査チームは、外部から発見不可能な新しいドメインを複数作成し、「User-agent: *」と「Disallow: /」という記述で全てのボットによるアクセスを拒否するrobots.txtファイルを設置しました。

しかし、これらのドメインについてPerplexityに質問したところ、制限されているはずのコンテンツに関する詳細な情報が提供されたことから、クローラーが何らかの手段でアクセスしていることが判明しました。
Cloudflareによれば、Perplexityは申告済みのクローラーがブロックされると、macOS上のGoogle Chromeを装った一般的なブラウザのユーザーエージェントを使用していたことが確認されたとのこと。さらに、公表されているIPアドレス範囲外の複数のIPアドレスを利用し、ブロックを回避するためにIPやASN(自律システム番号)をローテーションさせていたことも明らかになりました。
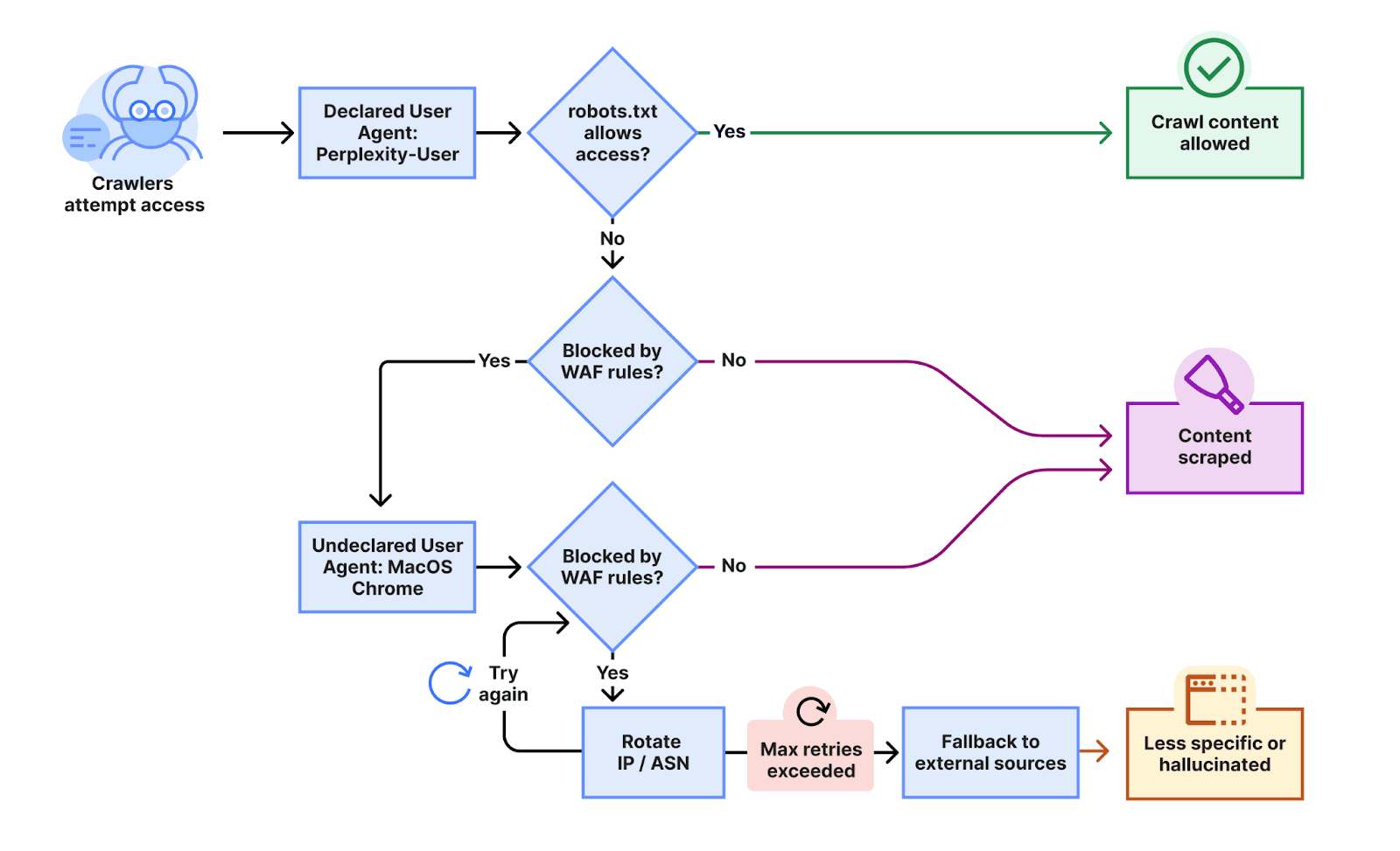
Cloudflareはこの挙動を他のAI企業のクローラーと比較しており、一例としてOpenAIのクローラーで同様のテストを実施したところ、OpenAIのクローラーはrobots.txtの指示を尊重し、アクセスが拒否されるとクロールを停止したことが確認されています。
Cloudflareは「過去30年にわたり私たちが知るインターネットは急速に変化していますが、一つだけ不変なのは、それが『信頼』の上に成り立っているということです。クローラーは透明性を保ち、明確な目的を持ち、特定の活動を行い、そして最も重要なこととして、ウェブサイトの指示や設定に従うべきであるという明確な慣例が存在します。観測されたPerplexityの行動はこれらの慣例と相容れないため、当社はPerplexityを認証済みボットのリストから除外し、このステルス性クロールをブロックするためのヒューリスティックを当社の管理ルールに追加しました」と宣言しました。
Cloudflareは、「善良なクローラーに望まれる振る舞い」として以下の5点を挙げています。
・透明性:固有のユーザーエージェント、公表されたIP範囲リスト、またはWeb Bot Authの統合を用いて正直に自らを識別し、問題が発生した場合の連絡先情報を提供する。
・良きネット市民であること:過剰なトラフィックでサイトを溢れさせたり、機密データをスクレイピングしたり、検知を逃れるためにステルス戦術を使ったりしない。
・明確な目的を果たすこと:音声アシスタントの動力源、製品価格の確認、ウェブサイトのアクセシビリティ向上など、ボットの目的は明確かつ正確に定義され、サイト所有者が公に簡単に調べられるべき。
・活動ごとにボットを分離すること:各活動を固有のボットから行うこと。サイト所有者に「全か無か」の決断を強要しない。
・ルールに従うこと:robots.txtのようなウェブサイトのシグナルを確認し尊重すること。また、レート制限内に留まり、セキュリティ保護を絶対に迂回しない。
Cloudflareは「ボット運用者が検知を回避するために使用する技術は進化し続けると予想しています。この記事が公開されれば、ボット運用者の行動はほぼ間違いなく変化し、それを阻止するための私たちの手法も同様に進化し続けるでしょう」と語りました。
・関連記事
生成AI検索エンジンのPerplexityはクローラーを防ぐ「robots.txt」を無視してウェブサイトから情報を抜き出している - GIGAZINE
「PerplexityのAIがクローラーをブロックするrobots.txtを無視している」との指摘に対しCEOが「無視しているわけではないがサードパーティーのクローラーに依存している」と主張 - GIGAZINE
RedditがGoogle以外のAIがコンテンツをトレーニングに利用することを防ぐための施策を強いられているとしてMicrosoft・Anthropic・Perplexityを名指しで批判、「面倒なので本当はやりたくない」と発言 - GIGAZINE
CloudflareがAIクローラーを無限生成迷路に閉じ込める「AI Labyrinth」を発表 - GIGAZINE
AIトレーニング用のデータをかき集めるクローラーを無限生成される迷路に閉じ込める「Nepenthes」が開発される - GIGAZINE
OpenAIのクローラーボットが3Dスキャンデータ販売サイトをほぼDDoS攻撃な徹底スクレイピングでダウンさせていた - GIGAZINE
・関連コンテンツ








in ソフトウェア, Posted by log1i_yk
You can read the machine translated English article Cloudflare accuses Perplexity of using s….