Cloudflare accuses Perplexity of using stealth tactics to ignore no-crawl orders
Cloudflare has reported that Perplexity, a well-known AI search engine, has been using stealthy crawlers to collect information against the wishes of website owners. When Perplexity's declared user-agent was blocked, it would switch to an undeclared user-agent in an attempt to circumvent the website's crawler directives.
Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives
The investigation was initiated following complaints from website operators that their content continued to be accessed despite Perplexity's explicit access being denied in their robots.txt files and firewalls.
Cloudflare's research team created several new, undiscoverable domains and installed a robots.txt file that denied access to all bots with the lines 'User-agent: *' and 'Disallow: /'.

However, when we asked Perplexity about these domains, they provided us with detailed information about the supposedly restricted content, indicating that crawlers were somehow accessing it.
According to Cloudflare, Perplexity was found to have used a common browser user-agent, posing as Google Chrome on macOS, when its declared crawler was blocked. Additionally, the group used multiple IP addresses outside of published IP address ranges and rotated IPs and ASNs (Autonomous System Numbers) to evade blocks.
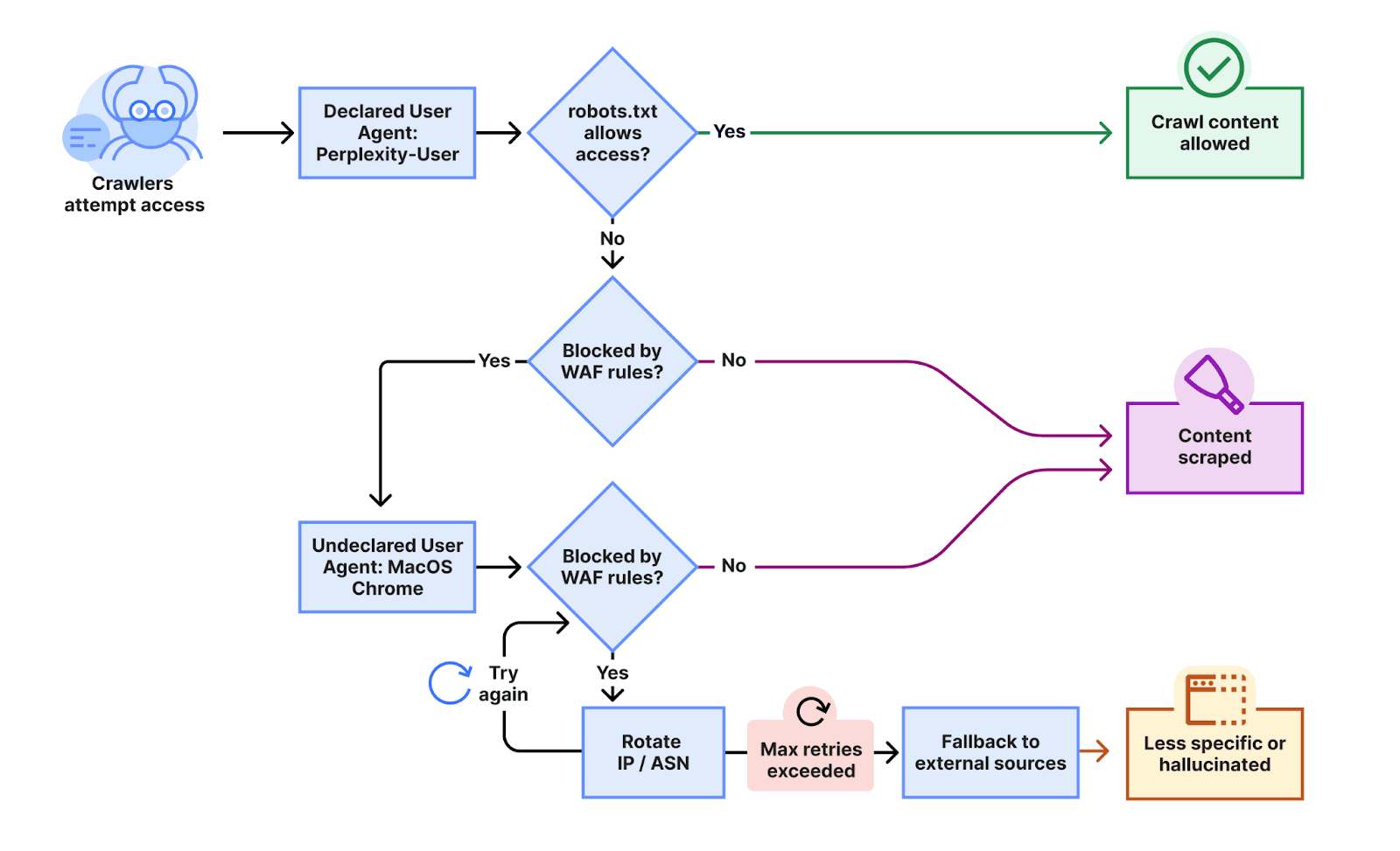
Cloudflare compared this behavior with crawlers from other AI companies, and when they ran similar tests with OpenAI's crawler, they found that the OpenAI crawler respected the robots.txt directives and stopped crawling when access was denied.
Cloudflare said, 'Over the past 30 years, the Internet as we know it has changed rapidly, but one thing has remained constant: it is built on trust. There are clear conventions that crawlers should be transparent, have clear objectives, perform specific activities, and, most importantly, follow website instructions and settings. Because the observed behavior of Perplexity is inconsistent with these conventions, we have removed Perplexity from our list of authenticated bots and added heuristics to our management rules to block this stealthy crawling.'
Cloudflare lists the following five behaviors that a good crawler should follow:
Transparency : honestly identify yourself using a unique user-agent, published IP range list, or Web Bot Auth integration, and provide contact information in case of issues.
Be a good internet citizen : Don't flood sites with excessive traffic, don't scrape sensitive data, or use stealth tactics to avoid detection.
Serve a clear purpose : The bot's purpose should be clearly and precisely defined and easily publicly verifiable by site owners, such as powering a voice assistant, checking product prices, or improving website accessibility.
Isolate bots by activity : Each activity should be run by a unique bot, not forcing site owners into an all-or-nothing decision.
Play by the rules : Check for and respect website signals like robots.txt, stay within rate limits, and never bypass security protections.
Cloudflare said, 'We expect the techniques bot operators use to evade detection to continue to evolve. Once this article is published, bot operators' behavior will almost certainly change, and our methods for stopping them will continue to evolve as well.'
Related Posts:








in Software, Posted by log1i_yk