




AppleがOpenAI「o3」のようなトップレベルのAIモデルや大規模推論モデルの限界を詳しく説明

Appleが「思考の錯覚:問題の複雑さというレンズを通して推論モデルの強みと限界を理解する」と題した論文を発表しました。研究者たちはAnthropicのClaude、OpenAIのoモデル、DeepSeek-R1、Googleのモデルといった「推論」モデルをテストし、人間の推論をどこまで再現できるかを検証しましたが、AIの推論能力のスケールアップはマーケティングで宣伝されているほどではなかったそうです。
the-illusion-of-thinking.pdf
(PDFファイル)https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
A knockout blow for LLMs? - by Gary Marcus - Marcus on AI
https://garymarcus.substack.com/p/a-knockout-blow-for-llms
Apple Study Calls Out “Reasoning” AI as Overhyped While Siri Struggles - 9meters
https://9meters.com/technology/ai/apple-study-calls-out-reasoning-ai-as-overhyped-while-siri-struggles
Thinking AI models collapse in face of complex problems, Apple researchers find - Hindustan Times
https://www.hindustantimes.com/business/thinking-ai-models-collapse-in-face-of-complex-problems-apple-researchers-find-101749305499965.html
Appleの研究者らは今回の論文で、「ハノイの塔」という有名なボードゲームを使うなどして各種モデルを評価しました。ハノイの塔は3本の柱に大小数枚の円盤を積み重ねるゲームで、「円盤の上に自分より大きな円盤を置いてはいけない」というルールの下、左の柱に積まれた円盤をすべて右の柱に動かさなければなりません。

ハノイの塔は人間でも練習すれば簡単に解くことが可能で、またハノイの塔を解くためにプログラムされたコンピューターでもしっかりクリアできます。ただ、「推論」をうたうAIはほとんどクリアできませんでした。インターネット上にはハノイの塔を解くためのソースコードライブラリが数多く無料で公開されているにもかかわらずです。
例えば、AnthropicのAI「Claude 3.7(推論あり)」が7枚のディスクがあるゲームをプレイすると、正答率は80%を下回りました(画像左下)。最低255手でクリアできる8枚バージョンになるとほとんどクリアできません。
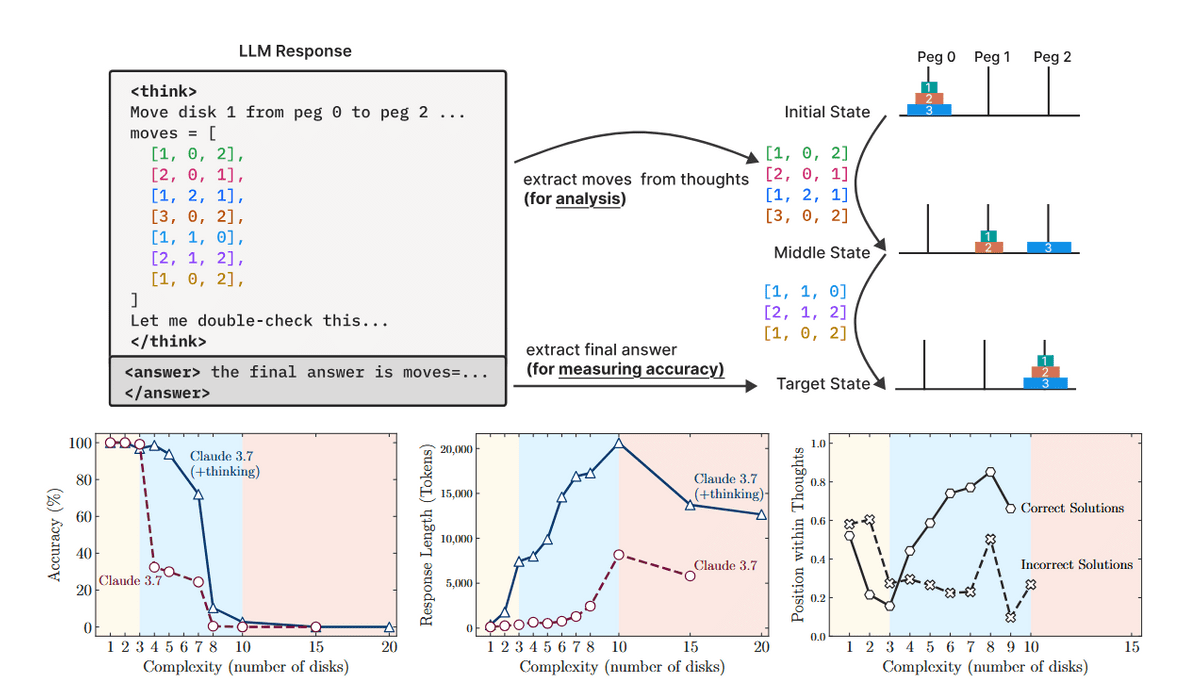
さらに、AIはこうしたパズルを解いているときに演繹的推論や記号的推論をしている様子は一切なく、トレーニング中に見たパターンに基づいて推論していました。つまり、人間がやるように「ハノイの塔というゲームを見て、システムを理解し、解法を導いた」というわけではないということで、「これは果たして宣伝されているような『推論』と呼べるのか?」という疑問を研究者らは投げかけています。
一般的なAIのベンチマークは数学的ベンチマークやコーディングベンチマークに依存することが多く、最終的な解答の正確さに主眼を置いており、推論プロセス自体に対する洞察は限られています。研究者らはこれらのギャップを解決するために先述のハノイの塔や川渡り問題を利用し、モデルがどのように「思考」しようとしているのかを垣間見ようとしましたが、テストされたすべての推論モデルにおいて、ある複雑さの閾値を超えると精度が完全に崩壊することがわかっています。
基本的に、推論をしない大規模言語モデル(LLM)では複雑度が低いほど正確で「トークン」の使用効率が高く、複雑さが増すにつれて推論モデルの方が優れた結果を示しますが、推論モデルでも問題の複雑さが増すにつれて回答の精度は減少しました。
研究者らは「これらのモデルはどの問題にも応用できる汎用(はんよう)的な推論が可能なのか、それともただのパターンマッチングを利用しているのかわかりません。推測能力が増すからといって、必ずしも知能が上がるわけではないのです」と記しています。

著名な人工知能専門家のゲイリー・マーカス氏は「LLMは優れた、よく仕様化された従来のアルゴリズムの代替にはならないということです。LLMは従来のアルゴリズムほどチェスをうまくプレイできず、タンパク質を折り畳むこともできません。うまくいけば、Pythonコードを書き、自身の弱点を外部のコードで補うことができますが、それでも信頼できるものではありません。これはビジネスや社会にとって、単にo3やClaudeを複雑な問題に投入しても、確実に動作するとは限らないことを意味します。少なくとも今後10年間は、LLM(推論の有無にかかわらず)は特にコーディング、ブレインストーミング、そして執筆において引き続き利用されるでしょう。しかし、LLMが社会を根本的に良い方向に変えることができるような汎用(はんよう)人工知能(AGI)への直接的な道だと考えている人は、うぬぼれです」と述べました。
・つづき
Appleが提唱した「AIの推論能力の限界」にAI専門家が反論 - GIGAZINE
・関連記事
AIの頭の中ではどのように情報が処理されて意思決定が行われるのかをAnthropicが解説 - GIGAZINE
大規模視覚言語モデルは人間のように「地図を読み取って最適なルートを見つける」ことができるのか? - GIGAZINE
処理するトークンが増えすぎるとAI言語モデルが動作困難になる理由、計算コストは入力サイズの2乗に比例 - GIGAZINE
従来の大規模言語モデルの制約だった「入力量の限界」を取り払った「RWKV」は一体どんな言語モデルなのか? - GIGAZINE
・関連コンテンツ








in AI, ソフトウェア, Posted by log1p_kr
You can read the machine translated English article Apple details the limitations of top-lev….