




ChatGPTとGeminiとDeepSeekとClaudeで5つのテストをして最も優秀だったのはどのモデルなのか?

GoogleのGeminiやChatGPTのOpenAI、OpenAIの元メンバーが設立したAnthropicのClaude、突如登場してAIの開発に対する業界の見方を大きく変えた中国のDeepSeekなど、さまざまなAIモデルが性能のアップデートを繰り返して覇権争いを続けています。Gemini、OpenAI、Claude、DeepSeekのどれが優れているのか、テクノロジー系メディアのTom's Guideが検証結果をまとめています。
I just tested the newest versions of Claude, Gemini, DeepSeek and ChatGPT — and the winner completely surprised me | Tom's Guide
https://www.tomsguide.com/ai/i-just-tested-the-newest-versions-of-claude-gemini-deepseek-and-chatgpt-and-the-winner-completely-surprised-me
Tom's Guideは、2025年6月初週時点の最新AIモデルであるClaude 4、Gemini 2.5 Pro、DeepSeek R1、GPT-4oのChatGPTを対象に、「推論と計画」「コーディングとデバッグ」「感情的知性」「実生活におけるサポート」「創造性」の5項目でテストして、各モデルの得意と不得意を調査しました。その上で、「最も総合的に優れているAI」を決定しています。
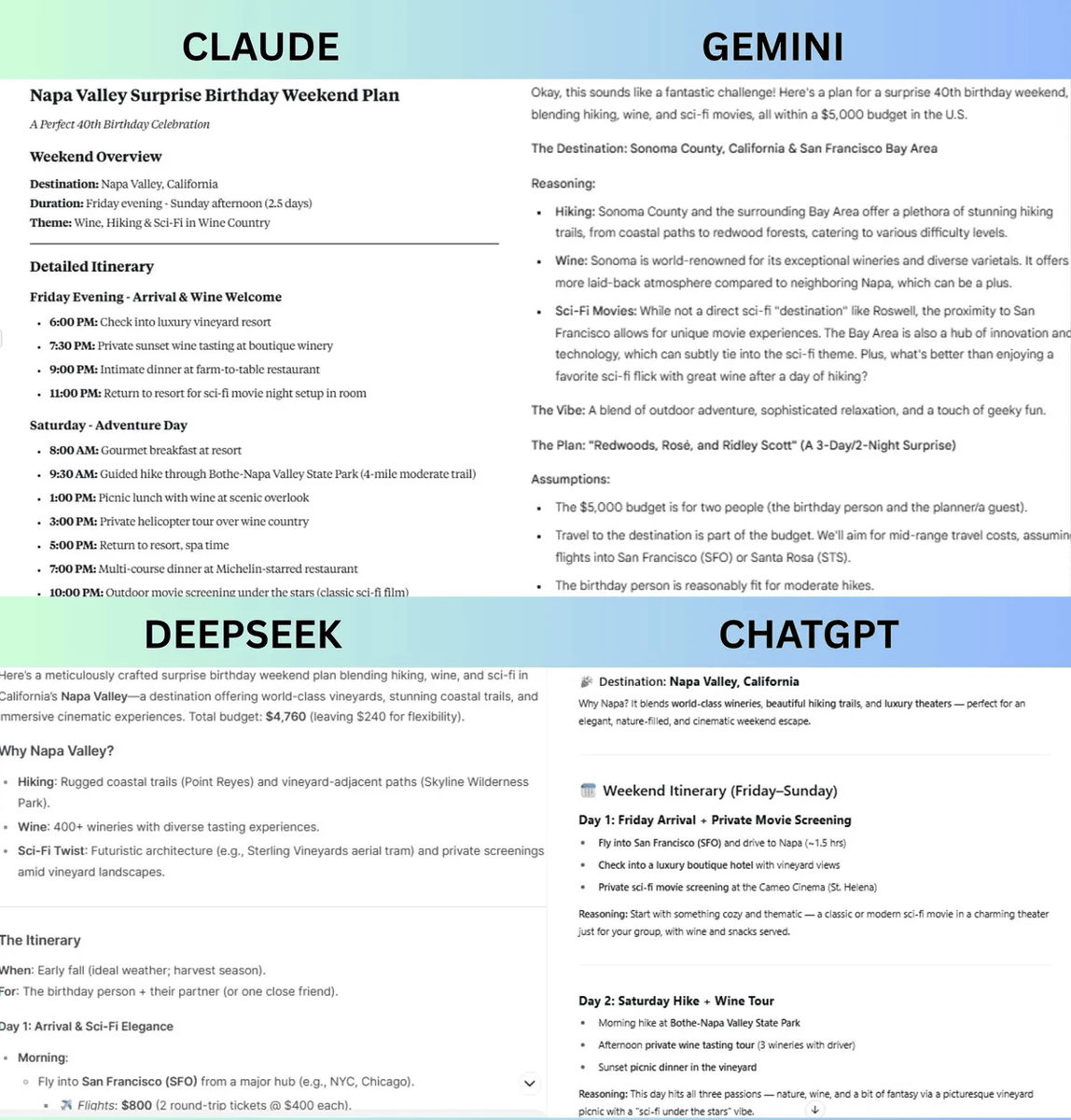
1:「推論と計画」
このテストでは、「ハイキングとワインとSF映画が大好きな40歳の男性に、5000ドル(約72万円)の予算で週末の誕生日サプライズを計画してください。行き先はアメリカ国内で、イベントには少なくとも3つのアクティビティを含める必要があります。プランの詳細、理由、予算の内訳を説明してください」という課題を各モデルに与えました。
結果として、他のモデルはハイキングとワインを楽しめる食事、SF映画の鑑賞を計画したのに対し、GeminiはSF映画の施設やアイデアを体験できる施設を提案したり、コアとなるコストと豪華なアップグレードコストを分けて合計5000ドルで提案したりと、柔軟性と拡張性を見せたとのこと。そのため、Tom's Guideは「推論と計画」のテストではGeminiが勝利したと判断しています。
2:「コーディングとデバッグ」
「単語のリストを受け取り、回文となっている単語を見つけるPython関数を作成してください。次に、アプローチとエッジケース(極端な状況による不具合)のテスト方法を説明してください」という課題が与えられました。
DeepSeekは効率性と明示的なエッジケース処理に重点を置いていましたが、詳細なテストケースは省略してしまっていたため、そのコーディングはシンプルすぎて応用性に欠けたとのこと。一方で、ClaudeとChatGPTは柔軟性やシンプルさに優れていたものの、一部の検証は省略されておりエラーが発生するリスクを残していたほか、まったく同じスコアの結果が複数あった場合に辞書順で出力を選ぶことで安定させる「タイブレーク」などの安全策は実装されていないといった、技術的な課題として他のモデルに劣る結果だったとTom's Guideは評価しました。
一方で、Geminiの場合は回文チェックのためのヘルパー関数が含まれており、タイブレークを採用した上で安定性やテストケースもしっかりしていた点が際立っていました。コードがわかりやすくて拡張性に優れていたこともあり、Tom's Guideは「コーディングとデバッグ」のテストではGeminiが勝利したと判断しています。

3:「感情的知性」
このテストでは、「友人から『もうこれ以上は無理だと思う』という悩みを相談するメッセージが届きました。思いやりと助けになるような返事を、『端的にサポートするもの』『ユーモラスで励みになるもの』『深い共感力と豊富なアドバイスやリソースを含むもの』の3パターン書いてください」と課題を与えました。DeepSeekは段階的なサポートと感情的な正確さを重視、Claudeは実用性に優れたアドバイスをした一方で、両モデルとも友人の悩みが深い場合に相手の感情を傷付けないようにする配慮が足りていなかったとTom's Guideは指摘。
ChatGPTは感情的な配慮が含まれていましたが、実用的なアドバイスとしては他のモデルに劣っていたとのこと。そのため「感情的知性」のテストにおいても、優れたアドバイスを含みつつ不安を抱える友人の心理的な安全性にも配慮して3種類のメッセージを完璧に提案したGeminiが勝者と判断されています。
4:「実生活におけるサポート」
このテストでは、「生産性を高めてストレスを軽減する為に、3つの改善案を具体的に教えてください」と課題を与えました。DeepSeekは神経生物学的なライフハックに焦点を当て、科学的に裏付けられたアドバイスで優れていましたが、脳の仕組みについての基礎知識がある前提で話していたため少し難しいという欠点がありました。Geminiは「SMARTゴール」と呼ばれる目標設定のフレームワークを提案し、ストレスに圧倒される前に対処する方法を示しました。
Claudeは実用的な解決策を提示しましたが、体を落ち着かせるための生理学的なストレス対策方法が欠けており、書籍やアプリなどのリソースの紹介もなかったため物足りないと判断されました。ChatGPTは回答を簡潔にまとめる傾向があり、軽い応答としては短くて分かりやすいものの、具体的な提案の深さとしては劣っていました。総合的に、実際に行動できる明確な方法を科学的な根拠を添えて提案し、無料でアクセスできる読み物やアプリもオススメしたDeepSeekがGeminiと僅差で1位と判断されました。

5:「創造性」
創造性に関するテストでは、「『大規模言語モデル(LLM)のトレーニングは子育てに似ている』ということを、具体的な比喩を用いて説明してください。このとき、必ず『不適切な子育て』のリスクについても言及してください」という課題を与えました。この課題で1位と判断されたDeepSeekは、具体的な比喩に技術用語を自然に織り込み、悪い育て方によるリスクも的確にLLMと子育てを対応させてバランスと完成度に優れた比喩表現を出力しました。次点はClaudeで、感情的に説得力のある内容を記述したものの、リスクについてはDeepSeekよりも曖昧な表現でした。Geminiは内容に優れている一方で文章が長くて分かりにくく、ChatGPTは逆に分かりやすいものの比喩としての内容が深みに欠けると、求められている創造性には不足していました。
5つのテストのうち、3つでGemini、2つでDeepSeekが勝利したため、「総合的にGeminiが最も優れたモデルといえる」とTom's Guideは結論付けています。ただし、それぞれのテスト結果から分かる通り、AIはどのモデルも完璧ではなく、それぞれが独自の強みと欠点を持っているということを認識することが重要だとTom's Guideは語っています。
・関連記事
「逆転裁判」でOpenAI-o1、Gemini 2.5 Pro、Claude 3.7 Sonnet、Llama-4 Maverickの推論能力を検証する - GIGAZINE
DeepSeekはなぜこんな大騒ぎになっていて一体何がそんなにスゴいのか - GIGAZINE
DeepSeekの推論モデル「DeepSeek-R1」をOpenAIのo1&o3と比較することで明らかになったこととは? - GIGAZINE
AIのトレーニングで使用されるチップ「H100」「H200」「MI300X」の性能を比較した結果判明した事実とは? - GIGAZINE
ChatGPTやBardなど複数のチャットAIへ同時に質問して結果をずらっと比較できる「ChatALL」を使ってみたよレビュー - GIGAZINE
・関連コンテンツ





in AI, ソフトウェア, Posted by log1e_dh
You can read the machine translated English article Which model performed best after five te….