Which model performed best after five tests using ChatGPT, Gemini, DeepSeek, and Claude?

Various AI models, such as Google's Gemini, ChatGPT's OpenAI, Anthropic's Claude, which was founded by a former member of OpenAI, and China's DeepSeek , which suddenly appeared and dramatically changed the industry's view of AI development, are competing for supremacy by repeatedly updating their performance. Technology media Tom's Guide has summarized the results of its verification to see which of Gemini, OpenAI, Claude, and DeepSeek is better.
I just tested the newest versions of Claude, Gemini, DeepSeek and ChatGPT — and the winner completely surprised me | Tom's Guide
https://www.tomsguide.com/ai/i-just-tested-the-newest-versions-of-claude-gemini-deepseek-and-chatgpt-and-the-winner-completely-surprised-me
Tom's Guide tested the latest AI models as of the first week of June 2025, Claude 4 , Gemini 2.5 Pro , DeepSeek R1 , and GPT-4o 's ChatGPT, in five areas: 'reasoning and planning,' 'coding and debugging,' 'emotional intelligence,' 'real-life support,' and 'creativity,' to investigate the strengths and weaknesses of each model. Based on this, the 'most comprehensively superior AI' was determined.
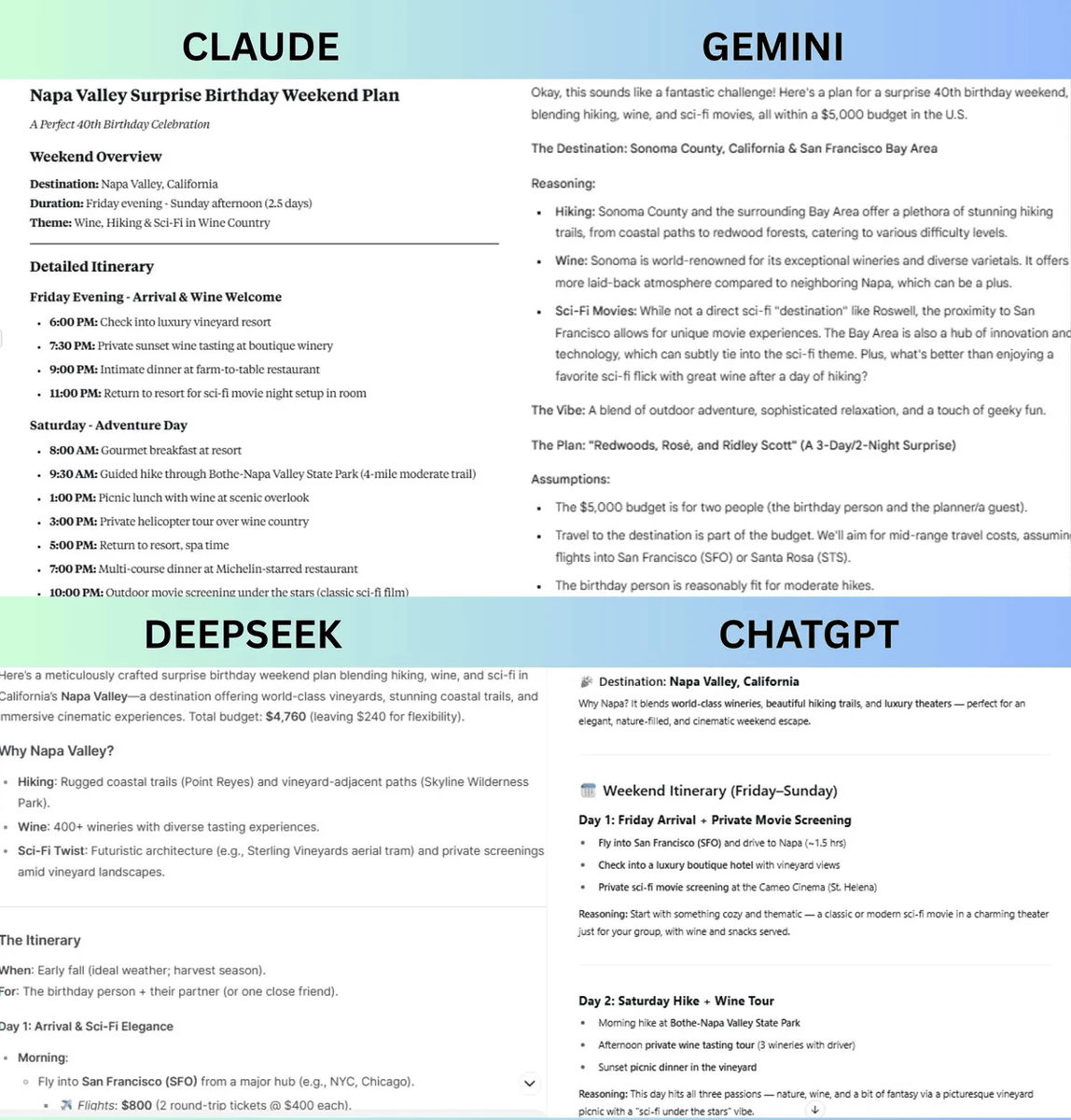
1: 'Reasoning and Planning'
In this test, the models were given the following task: 'Plan a birthday weekend surprise for a 40-year-old man who loves hiking, wine, and sci-fi movies with a budget of $5,000 (approximately 720,000 yen). The destination must be in the United States and the event must include at least three activities. Please explain your plan, why, and the breakdown of your budget.'
As a result, while the other models planned hiking, dining with wine, and watching science fiction movies, Gemini showed flexibility and scalability by proposing facilities where you can experience science fiction movie facilities and ideas, and proposing a total of $5,000 by dividing the core cost and the luxury upgrade cost. Therefore, Tom's Guide judged Gemini to have won the 'reasoning and planning' test.
2: 'Coding and debugging'
The assignment was: 'Write a Python function that takes a list of words and finds which words are palindromes. Then explain how you would test your approach and edge cases.'
DeepSeek focused on efficiency and explicit edge case handling, but omitted detailed test cases, so its coding was too simple and lacked applicability. On the other hand, Claude and ChatGPT excelled in flexibility and simplicity, but some verification was omitted, leaving the risk of errors, and safety measures such as 'tiebreaking' to stabilize by selecting output in lexicographical order when there are multiple results with exactly the same score were not implemented, so Tom's Guide evaluated that the results were inferior to other models as technical challenges.
Gemini, on the other hand, stood out for its stability and test cases, including a helper function for checking palindromes, and its tie-breaking code.Tom's Guide awarded Gemini the win in the 'coding and debugging' test, due in part to its easy-to-understand and extensible code.

3: “Emotional intelligence”
In this test, participants were asked to write a thoughtful and helpful response in three different patterns: one that is simply supportive, one that is humorous and encouraging, and one that is deeply empathetic and includes a wealth of advice and resources. DeepSeek emphasized step-by-step support and emotional accuracy, while Claude gave practical advice. However, Tom's Guide pointed out that both models were not considerate enough to avoid hurting the friend's feelings when the friend's troubles were deep.
Although ChatGPT included emotional considerations, it was inferior to other models in terms of practical advice. Therefore, in the 'emotional intelligence' test, Gemini was judged to be the winner, as it perfectly suggested three types of messages that included excellent advice while also taking into account the psychological safety of anxious friends.
4: 'Real-life support'
In this test, we asked participants to give three specific suggestions for improvement to increase productivity and reduce stress. DeepSeek focused on neurobiological life hacks and excelled with scientifically-backed advice, but it was a little difficult to understand because it assumed a basic knowledge of how the brain works. Gemini proposed a goal-setting framework called 'SMART goals' and showed how to deal with stress before it becomes overwhelming.
Claude offered practical solutions, but was deemed unsatisfactory because he lacked physiological stress management methods to calm the body and did not introduce any resources such as books or apps. ChatGPT tended to summarize their answers succinctly, and although they were short and easy to understand as light responses, they lacked the depth of their concrete suggestions. Overall, DeepSeek, which proposed clear, actionable methods with scientific evidence and recommended free reading materials and apps, was judged to be in first place, just behind Gemini.

5: 'Creativity'
In the creativity test, we asked participants to explain using a concrete metaphor that training a large language model (LLM) is like raising a child. Please be sure to mention the risks of poor parenting. DeepSeek, which was judged to be the top in this task, naturally wove technical terms into the concrete metaphor and accurately matched LLMs with parenting to output a well-balanced and complete metaphoric expression of the risks of poor parenting. Claude came in second, and although he wrote an emotionally persuasive description, his description of the risks was more ambiguous than DeepSeek's. Gemini's content was excellent, but his sentences were long and difficult to understand, while ChatGPT's metaphor was easy to understand but lacked depth, so it fell short of the required creativity.
Of the five tests, Gemini won three and DeepSeek won two, so Tom's Guide concluded that 'Gemini is the best model overall.' However, as can be seen from the results of each test, it is important to recognize that no AI model is perfect and each has its own strengths and weaknesses, Tom's Guide said.
Related Posts:






in Software, Posted by log1e_dh