Google has released 'DiffusionGemma,' a spreading language model four times faster than Gemma 4, as an open model, and there is also a fine-tuned version that excels at Sudoku.

On June 10, 2026, Google released its open model, ' DiffusionGemma .' Unlike mainstream autoregressive models, DiffusionGemma is a spreading language model and is expected to play a significant role in fields requiring high-speed responses.
DiffusionGemma: 4x faster text generation
DiffusionGemma: The Developer Guide - Google Developers Blog
https://developers.googleblog.com/diffusiongemma-the-developer-guide/
The mainstream language model employs a mechanism called an 'autoregressive model,' which calculates tokens one by one and outputs them sequentially. While autoregressive models are capable of highly accurate inference, they also have the disadvantage of being slow in processing speed.
Diffusion language models apply the process commonly used in image generation AI—which involves repeatedly iterating through the entire noise to refine it into a final form—to language models, enabling faster processing compared to autoregressive models. Diffusion language models are being developed by multiple AI research institutions, and Google also announced ' Gemini Diffusion ' in May 2025. DiffusionGemma, announced this time, is an open model built upon the results of Gemini Diffusion.

DiffusionGemma is a MoE model with a total of 25.2 billion parameters and 3.8 billion active parameters. The graph below compares the processing accuracy and speed of 'DiffusionGemma,' 'Gemma 4 31B,' 'Gemma 4 26B A4B,' and 'Gemma 4 12B,' with the horizontal axis showing the number of output tokens per second and the vertical axis showing the benchmark score. The Gemma 4 series has the acceleration technology
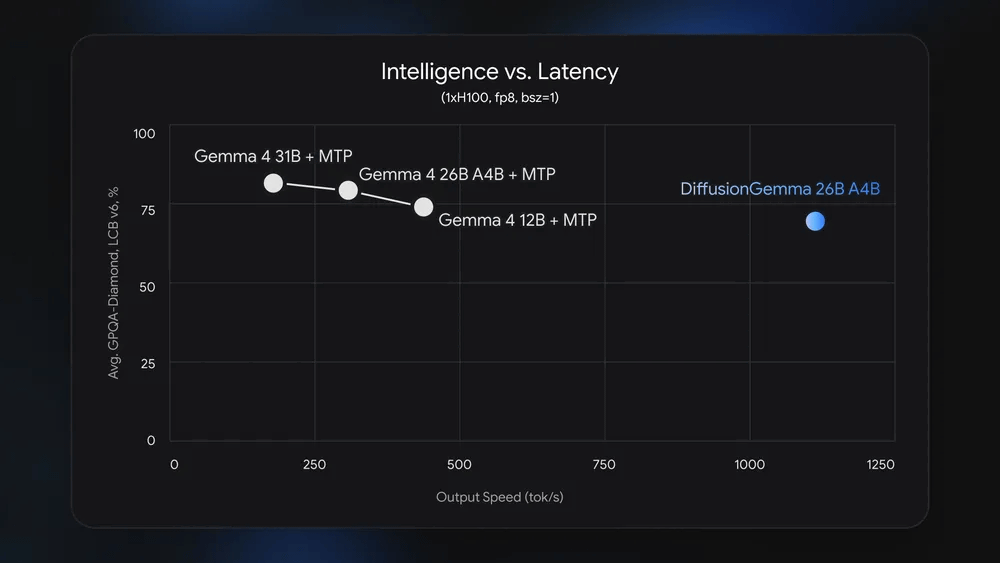
The following is a performance comparison between DiffusionGemma and Gemma 4 26B A4B, using models of the same size. DiffusionGemma operates approximately four times faster than Gemma 4 26B A4B while minimizing performance degradation.

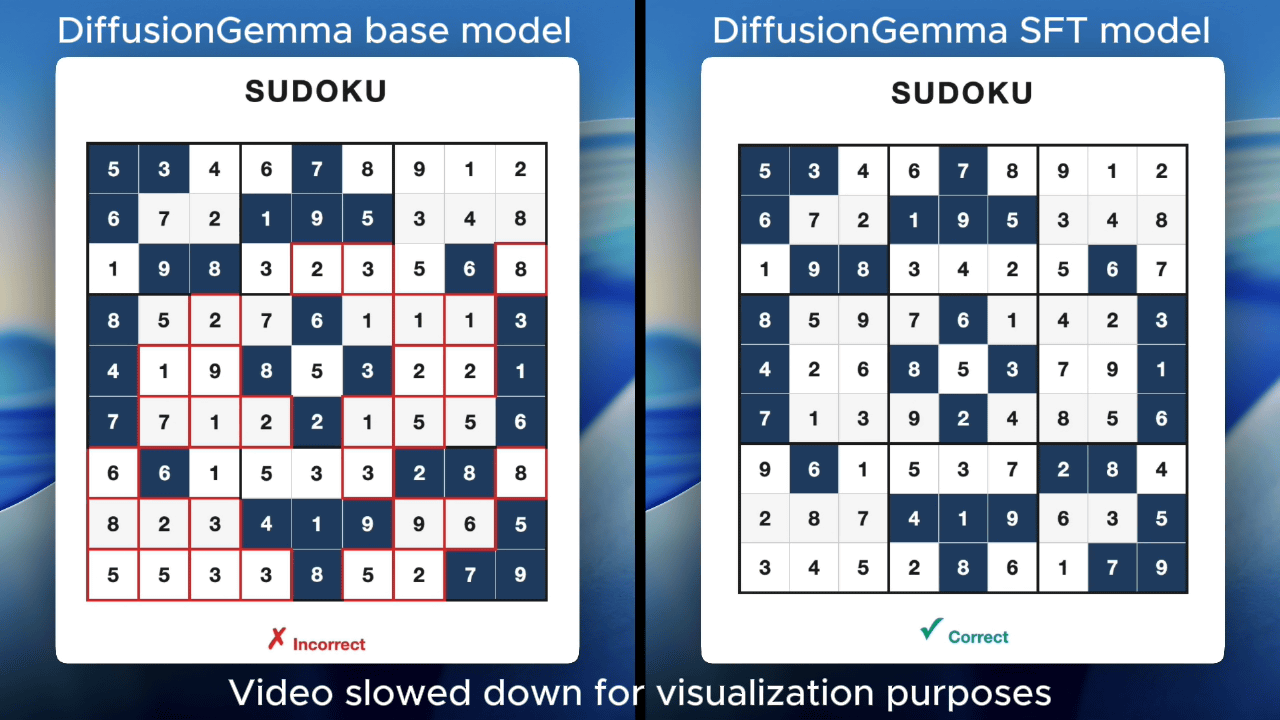
DiffusionGemma, a spreading language model, excels at the process of 'repeatedly trying the same location.' The following shows the results of solving the same Sudoku puzzle with 'DiffusionGemma's base model (left)' and 'DiffusionGemma's fine-tuned model (right).' It can be seen that by fine-tuning DiffusionGemma, it becomes able to perform the Sudoku task of 'rethinking the same square multiple times' with high accuracy.
DiffusionGemma is released as an open model and can be downloaded for free from the following link. It is licensed under the Apache License 2.0 .
google/diffusiongemma-26B-A4B-it · Hugging Face
https://huggingface.co/google/diffusiongemma-26B-A4B-it
We are also developing a quantized version using NVFP4 in collaboration with NVIDIA. The NVFP4 version is available at the following link and runs on a single GeForce RTX 5090.
nvidia/diffusiongemma-26B-A4B-it-NVFP4 · Hugging Face
https://huggingface.co/nvidia/diffusiongemma-26B-A4B-it-NVFP4
Related Posts:







in AI, Posted by log1o_hf