NVIDIA releases Nemotron Nano 2, a hybrid inference model that combines Transformer and Mamba

On August 18, 2025, NVIDIA released the Nemotron Nano 2 , a hybrid inference model that combines
NVIDIA Nemotron Nano 2 and the Nemotron Pretraining Dataset v1 - NVIDIA ADLR
https://research.nvidia.com/labs/adlr/NVIDIA-Nemotron-Nano-2/
Nvidia's open Nemotron-Nano-9B-v2 has toggle on/off reasoning | VentureBeat
https://venturebeat.com/ai/nvidia-releases-a-new-small-open-model-nemotron-nano-9b-v2-with-toggle-on-off-reasoning/
Nemotron Nano 2 is based on Nemotron-H , a hybrid model of the Transformer architecture, which is widely used in conventional language models, and the Mamba architecture , which was announced in December 2023.
The Transformer architecture is currently used in most mainstream large-scale language models, but it suffers from the problem of high memory and computational costs as the sequence length increases. On the other hand, the Mamba architecture incorporates a State Space Model (SSM), which can avoid the memory and computational cost issues associated with sequence length. Therefore, by combining the Transformer architecture and the Mamba architecture, it is possible to achieve higher throughput and equivalent accuracy even with long contexts.
Hugging Face has released the Nemotron-Nano-12B-v2-Base , the base model before pruning , the Nemotron-Nano-9B-v2-Base , the base model after pruning, and the Nemotron-Nano-9B-v2 , the model after alignment and pruning.
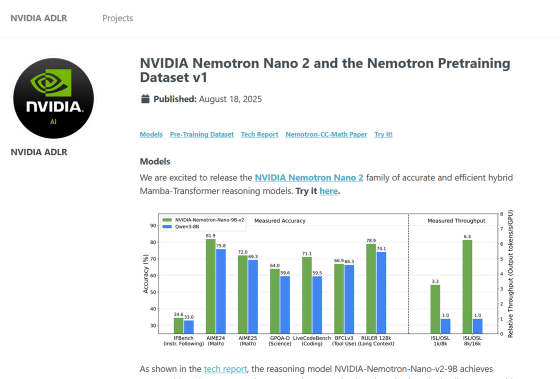
NVIDIA reports that the Nemotron-Nano-9B-v2, which can run on a single NVIDIA A10G GPU , achieved accuracy on complex inference benchmarks that was equal to or better than the leading open model of the same size, Qwen3-8B , while delivering up to six times the throughput.
In the graph below, the green bars represent Nemotron-Nano-9B-v2 and the blue bars represent Qwen3-8B, and the vertical axis represents the accuracy of the model for each benchmark. It can be seen that Nemotron-Nano-9B-v2 performs better in benchmarks including mathematics, science, coding, etc.
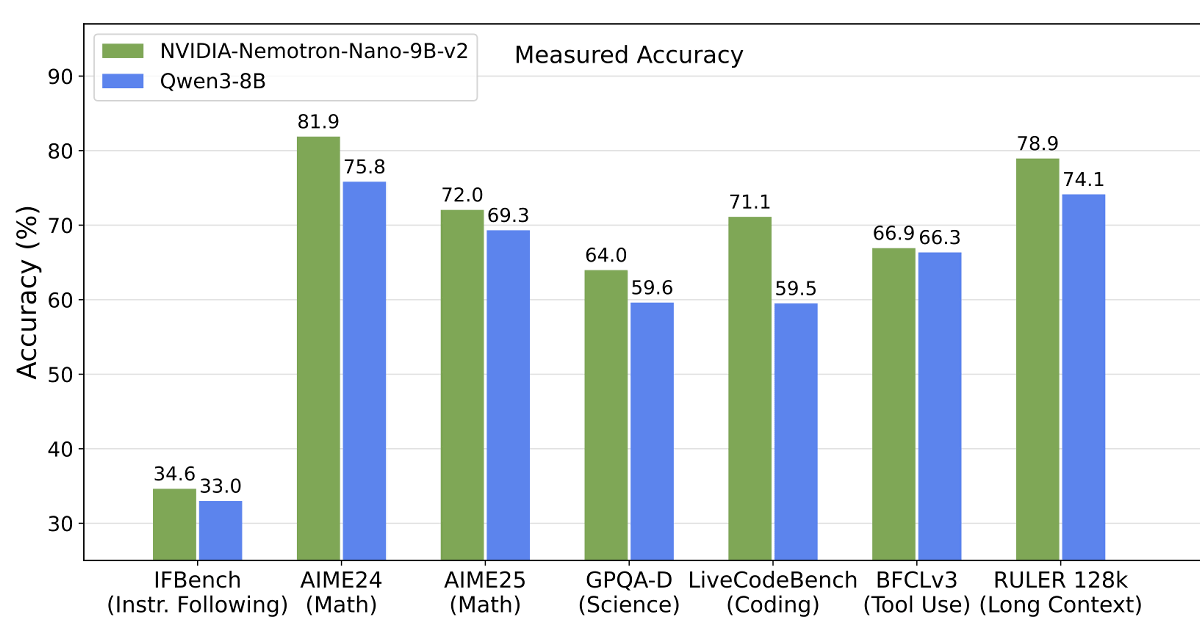
Also, looking at the graph below showing throughput for each input sequence length (ISL) relative to output sequence length (OSL), Nemotron-Nano-9B-v2 achieves better throughput, and the difference between the two models increases as the sequence length increases. It can be seen.
Nemotron Nano 2 is released under NVIDIA's proprietary open model license, the NVIDIA Open Model License, which allows developers to use the model commercially and also create and distribute derivative models, provided that developers comply with certain conditions, such as not circumventing built-in safety mechanisms without appropriate alternatives and providing attribution when redistributing.
NVIDIA Open Models License
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
Related Posts:








in Software, Web Service, Posted by log1h_ik