NVIDIA has announced 'SANA-WM,' an AI capable of generating one-minute videos and precisely controlling camera movement.

NVIDIA's research team has announced 'SANA-WM,' an open-source world model with 2.6 billion parameters. SANA-WM is a model that can generate videos up to one minute long at 720p resolution and is characterized by its ability to precisely control camera movement. A world model is a model that uses AI to predict the structure of the real world or virtual space, the movement of viewpoints, and changes in how objects appear, and then creates them as images.
SANA-WM | Efficient Minute-Scale World Modeling

[2605.15178] SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
https://arxiv.org/abs/2605.15178
While there are increasing numbers of AI models for generating short videos of a few seconds, generating a one-minute video without glitches requires significant computational power to maintain the continuity of the entire video. SANA-WM was designed from the outset with the goal of generating one-minute videos, and the research team explains that it has improved computational efficiency while maintaining image quality close to that of large-scale industrial models.
SANA-WM is not only capable of creating long videos, but it also features camera control, allowing it to generate images along a 6-degree-of-freedom camera trajectory. 6 degrees of freedom refer to free movement including forward/backward, left/right, up/down, and rotation to change the camera's orientation. Camera control is a crucial function in world models because it allows for precise control of the viewpoint, which is essential in games and robot simulations.
To handle long videos, SANA-WM employs a 'hybrid linear attention mechanism.' In typical video generation models, memory consumption and computational complexity tend to increase as the video length increases. SANA-WM combines a 'mechanism for efficiently maintaining the flow of time over long periods' with a 'mechanism for referencing detailed information at necessary points,' making it easier to maintain consistency even in one-minute videos.
Furthermore, to improve the accuracy of tracking the camera trajectory, SANA-WM uses two camera control systems that handle not only the general camera movement but also the fine-tuned viewpoint changes from frame to frame. While video generation models compress and process the video internally, which can sometimes result in the loss of detailed camera movement information, SANA-WM's two-system camera control ensures that viewpoint movement remains stable even in long videos.

Furthermore, SANA-WM uses a refiner, an additional model that further refines the generated video to improve image quality. The SANA-WM unit first generates the long-form video, and then a refiner specifically for long-form videos is used to enhance quality and consistency—a two-stage process. It is stated that the refiner ensures that details in the video and the transitions between frames are properly corrected.
SANA-WM uses approximately 213,000 publicly available video clips to create training data through an annotation pipeline that estimates the camera pose with 6 degrees of freedom from these videos. According to the research team, training was completed in 15 days using 64 H100 GPUs. Furthermore, a 60-second video can be generated on a single GPU, and the distilled model can perform the denoising process for a 60-second 720p video in 34 seconds using an RTX 5090 and NVFP4 quantization.
The following image compares the processing time, latency, and GPU memory usage for generating a 60-second video using SANA-WM. The graph on the left shows that a process that normally takes about 21.8 minutes with H100 is reduced to 48 seconds with the distillation model, and further reduced to 34 seconds with the addition of a sink. With the RTX 5090, not using a sink resulted in an 'OOM' (Out of Memory) error, indicating insufficient GPU memory, but using a sink reduced the processing time to 48 seconds, and adding NVFP4 quantization further reduced it to 42 seconds. The graph on the right also shows that the Hybrid Linear Attention Mechanism (Hybrid GDN-Softmax) reduces memory usage for longer videos compared to a Softmax-only configuration.
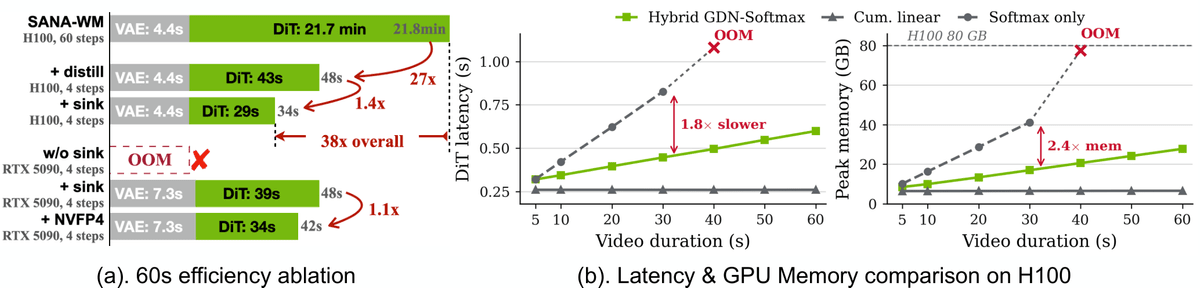
The research team stated that SANA-WM outperformed conventional open-source models in tracking control instructions such as camera trajectories, achieving 36 times the throughput while maintaining visual quality close to that of large-scale models.
Many examples of the types of videos that can be generated are posted in

Related Posts:







in AI, Posted by log1d_ts