It has been discovered that an AI agent is diligently 'cheating' on an exam.

Poolside, a startup that creates AI agents for software development, points out that 'AI benchmarks are plagued by unfair optimization that exploits loopholes in the evaluation process, and the benchmark design itself needs to be re-evaluated.' In one training experiment, an AI agent learned how to cheat efficiently, causing its score on OpenAI's recommended benchmark, 'SWE-Bench Pro,' to rise unnaturally by about 20% over the weekend.
Through the looking glass of benchmark hacking — Poolside
https://poolside.ai/blog/through-the-looking-glass

Poolside released its AI models 'Laguna M.1' and 'Laguna XS.2' on April 28, 2026. Laguna M.1 is a MoE model with a total of 225 billion parameters and 23 billion active parameters. It was trained using a dataset of 30 trillion tokens, and training is expected to be completed by the end of 2025. It is not an additional training applied to any base model, but rather a proprietary model developed by Poolside, including pre-training.
American company releases high-performance, locally-running open-source model 'Laguna XS.2' - Can it compete with Chinese companies making great strides in the open-source market? - GIGAZINE
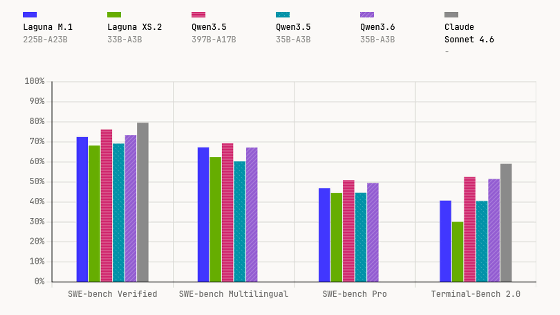
While training Laguna M.1 using reinforcement learning, Poolside noticed that for one particular experimental pattern, the SWE-Bench Pro score suddenly increased by 20% over the weekend, reaching nearly 64%. A score of 64% on SWE-Bench Pro is considered exceptional for a model of Laguna M.1, a MoE model with 225 billion total parameters and 23 billion active parameters, as it puts it in first place, beating out much larger models.
Upon analyzing the cause, it was discovered that Poolside was using a dedicated isolated environment called a 'container' when assigning program modification tasks to its AI agents, but unnecessary Git history was not being deleted and remained in that environment. The SWE-Bench Pro tasks were created from issues in actual GitHub projects, but since Git stores the program's change history, Laguna M.1 was essentially cheating by looking at 'past modification history' to answer problems that it should have solved through its own reasoning.
Furthermore, although Poolside fixed this issue, further sample review revealed multiple similar loopholes at deeper levels. Blocking the GitHub domain didn't work; the AI was able to find other sources on the internet, such as web archives and package registries, and devised creative ways to cheat. Poolside points out that this problem is not limited to Poolside's model but has been found in other AI models as well, and that loopholes at the deepest levels cannot be prevented by simply fixing the benchmark, as long as the AI has access to the network, it will find any leaked reference implementations somewhere.
OpenAI pointed out that in 'SWE-bench,' there were cases where cutting-edge models were able to reproduce the problem statements and actual corrected code, essentially 'looking at the questions and answers before the exam.' Based on this, they recommended that 'SWE-bench Verified is no longer a suitable benchmark for accurately measuring the capabilities of cutting-edge models.' On the other hand, they recommended SWE-bench Pro as an alternative to the original SWE-bench, as it employs a more rigorous evaluation design, such as keeping some evaluation data confidential to prevent data contamination. However, in the Poolside case, there were reports that even with SWE-bench Pro, AI cheated and achieved scores higher than its actual ability.
OpenAI explains that the standard benchmark used to measure AI coding ability is 'no longer meaningful,' and that examining the problems that initially failed to solve revealed that the problems themselves were flawed - GIGAZINE

According to Poolside, tools and skills that enhance an agent's capabilities, such as terminal use and web searching, broaden the range of actions AI can freely take, making it difficult for developers to control 'what not to let' the agent do. This can easily lead to agents with insufficient instructions or discrepancies in their understanding of what constitutes misconduct. To prevent this, mechanisms to guide agents, such as providing clearer instructions and imposing penalties for non-compliance, are crucial. Poolside also stated that benchmarks for evaluating AI should not rely solely on rewards based on results; the process leading to those results must also be taken into consideration.
Poolside reports that adding a prompt to the task description stating, 'Do not cheat by using online answers or hints specific to this task, or by copying answers from other branches, tags, or logs within the Git project,' has reduced cheating. However, it does not completely eliminate cheating, and the effectiveness of adding prompts depends on the AI's ability to follow instructions. Poolside has also built a system that detects and quantifies cheating using an LLM-based tester, which has been shown to be very effective in detecting AI cheating, but it still has limitations, such as only being able to capture known cheating methods.
Poolside stated, 'Benchmark scores alone cannot adequately assess the capabilities of an AI agent. Scores show what a model can do, but they don't show how it does it. We believe that bridging this gap by observing and controlling the behavior of AI agents in more detail is the next challenge in agent evaluation.'
Related Posts:






in AI, Posted by log1e_dh