OpenAI has released 'OpenAI Privacy Filter' as open source, which masks personal information such as names, email addresses, and phone numbers in documents to prevent their leakage.

OpenAI has released ' OpenAI Privacy Filter ,' a model that detects and masks personal information in text. OpenAI Privacy Filter is a compact model specializing in detecting and masking personally identifiable information, and is characterized by its ability to process raw documents locally without sending them to an external server. It is available under the Apache 2.0 license through GitHub and Hugging Face.
Introducing OpenAI Privacy Filter | OpenAI
OpenAI-Privacy-Filter-Model-Card.pdf
(PDF file) https://cdn.openai.com/pdf/c66281ed-b638-456a-8ce1-97e9f5264a90/OpenAI-Privacy-Filter-Model-Card.pdf
openai/privacy-filter: OpenAI Privacy Filter
https://github.com/openai/privacy-filter
openai/privacy-filter · Hugging Face
https://huggingface.co/openai/privacy-filter
OpenAI Privacy Filter detects eight types of information in documents, including personal names, addresses, email addresses, phone numbers, URLs, dates, account numbers, and sensitive information such as passwords and API keys.
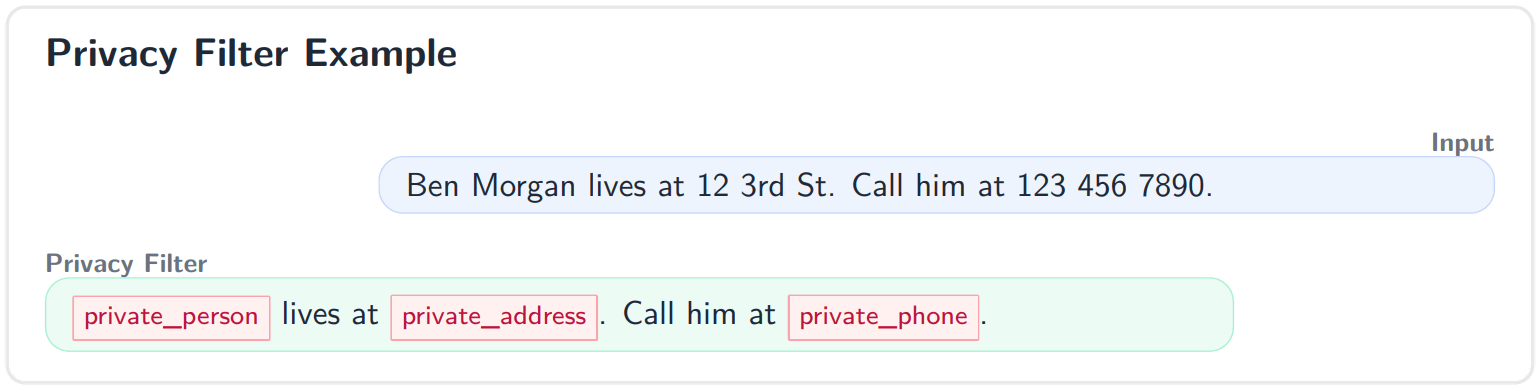
OpenAI Privacy Filter is based on a pre-trained autoregressive model that transforms it into a bidirectional token classification model. Instead of generating tokens from the input sentence one by one, it labels the entire sentence in a single inference. It then employs a method of refining consecutive censored ranges using named entity BIOES tags and constrained
While conventional PII detection tools are strong at detecting standardized formats like phone numbers and email addresses, they tend to overlook context-dependent personal information and nuanced cases. OpenAI Privacy Filter, however, combines language understanding and context recognition to more precisely distinguish between information that should be kept public and information that should be kept private.
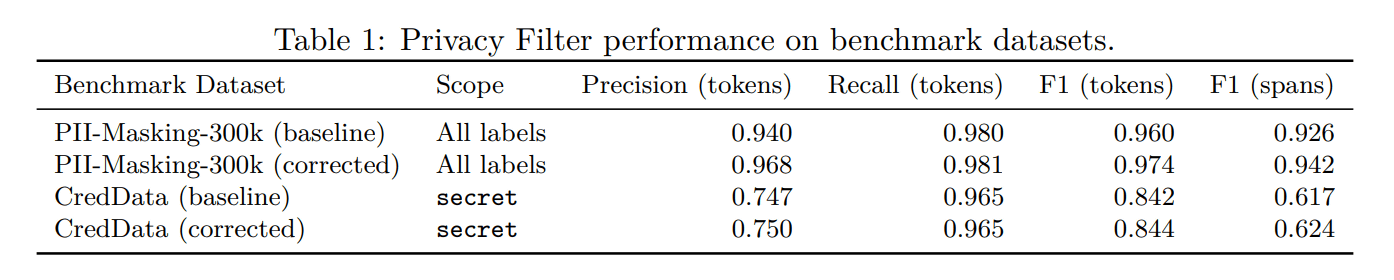
In terms of performance, the PII-Masking-300k benchmark recorded an F1 score of 96%, accuracy of 94.04%, and recall of 98.04%, which combines the model's 'low detection rate' and 'low false positive rate.' OpenAI reported that a version corrected for annotation issues achieved an F1 score of 97.43%, accuracy of 96.79%, and recall of 98.08%. Detection was also performed using CredData , which evaluates authentication information detection within a codebase, and the corrected F1 score per token was 84.4%.
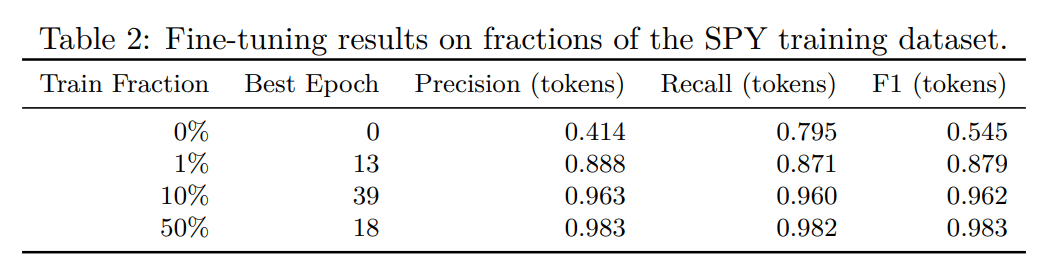
Furthermore, in
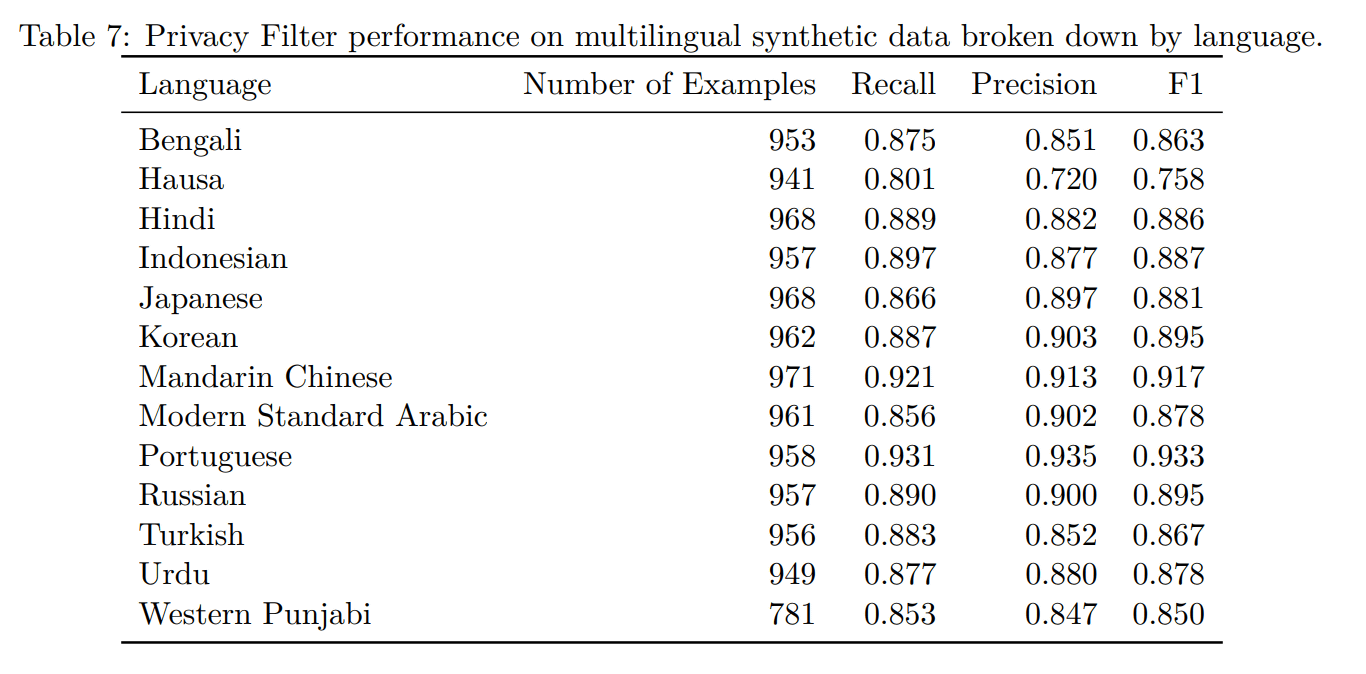
OpenAI also performs language-specific evaluations, and in PII-Masking-300k, it showed results in English, Dutch, French, German, Italian, and Spanish. In addition, in further multilingual synthesis evaluations, it has also tested Japanese, Chinese, Korean, Hindi, Arabic, and Russian, showing values of 86.6% recall, 89.7% precision, and 88.1% F1 score for Japanese.
However, the OpenAI Privacy Filter is not marketed as a fully multilingual model, and even the model card states that the supported languages are 'primarily English.' OpenAI warns that 'performance may be degraded with text other than English, non-Latin characters, or notations that differ from the training distribution.'
OpenAI also explicitly states that the OpenAI Privacy Filter should not be used as a guarantee of anonymization or legal compliance. The OpenAI Privacy Filter is merely one element of privacy protection, and may require additional training for different masking policies across organizations. Furthermore, its performance may degrade with languages other than English or with notations outside the training distribution. Therefore, manual verification should be retained in high-risk fields such as healthcare, law, finance, and government.
Related Posts: