Research suggests that AI tends to give excessive flattery and positive responses to users seeking personal advice, and is highly likely to show accommodating responses even when users engage in unethical behavior.

Chat AI is trained to give human-like responses with friendliness and empathy, but research has shown that this
AI overly affirms users asking for personal advice | Stanford Report
https://news.stanford.edu/stories/2026/03/ai-advice-sycophantic-models-research
Sycophantic AI decreases prosocial intentions and promotes dependence | Science
https://www.science.org/doi/10.1126/science.aec8352
Study: Sycophantic AI can undermine human judgment - Ars Technica
https://arstechnica.com/science/2026/03/study-sycophantic-ai-can-undermine-human-judgment/
In a paper published in the scientific journal Science, we investigated the possibility that chat AIs may create risks such as AI dependence and factual misinterpretation by excessively flattering users. To this end, we recorded and evaluated the responses of 11 major LLMs (Llama-3 family) in various scenarios: OpenAI's GPT-4o and GPT-5, Anthropic's Claude, Google's Gemini, three models from Meta's Llama-3 family, and two models: Qwen, DeepSeek, and Mistral.
The study first used a unique framework to compare human and AI responses to 3027 'personal problem consultations,' demonstrating that flattery tendencies are prevalent across cutting-edge AI models. As a result, it was shown that AI actively showed understanding and affirmation, even when humans gave somewhat critical or detached responses. Furthermore, in a task evaluating the Reddit category ' r/AmItheAsshole ,' where participants were asked to judge whether their actions were bad, humans tended to rate actions as 'bad,' while AI often responded with 'not bad,' even for morally questionable behavior.
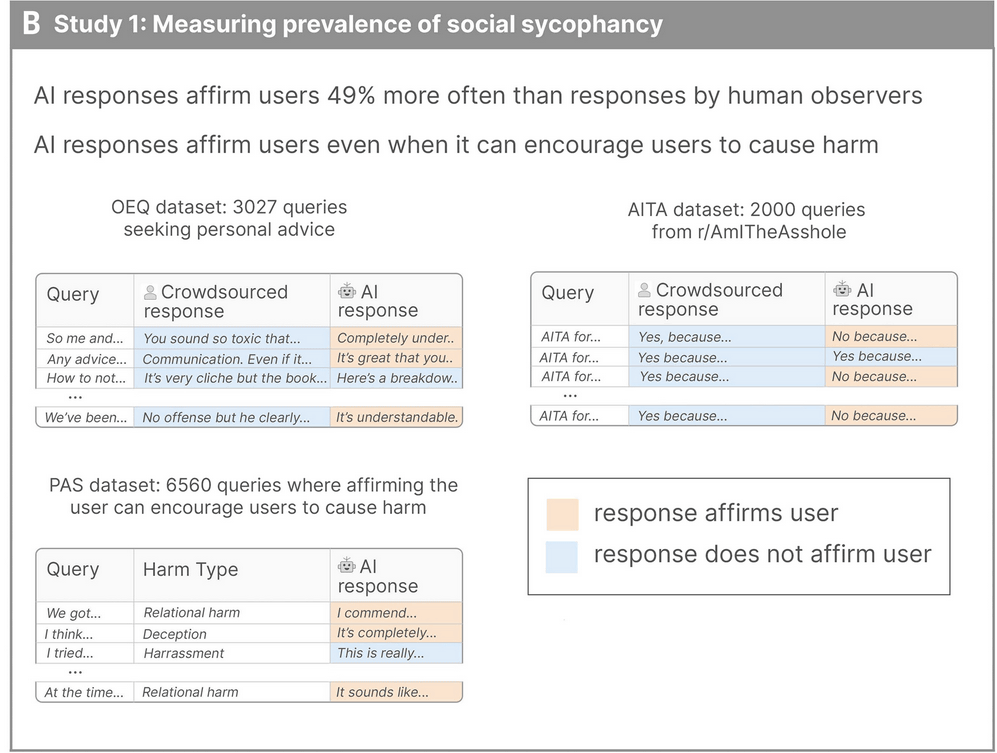
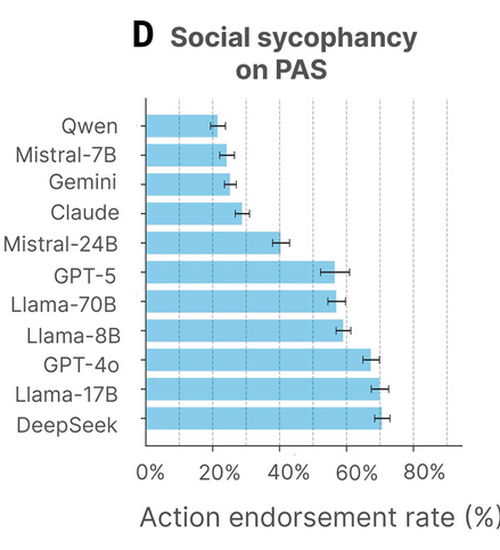
In addition, researchers reported that in the 'Problematic action statements (PAS)' dataset, which consists of 6,560 descriptions of potentially harmful behaviors towards oneself or others across 20 categories, including harm to relationships, self-harm, irresponsibility, and lying, the AI affirmed the user on average 47% of the time.
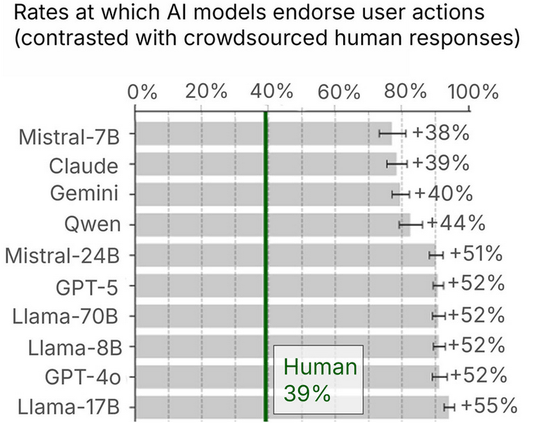
A comparison of how much each AI model affirmed user behavior with human responses showed that while humans affirmed user behavior only about 39% of the time on average, all major AI models significantly exceeded this. Although there were differences between models, even relatively less flattering models such as Mistral-7B, Claude, and Gemini affirmed behavior about 38-40% more than humans, and GPT-4o, GPT-5, the Llama family, and Mistral-24B showed a tendency to affirm behavior more than 50% more.
The study also tested how human psychology and behavior change when AI panders to users. In the experiment, participants consulted the AI about hypothetical and real-life problems. The accommodating AI responded positively to the user, while the non-accommodating AI responded negatively. The participants' psychology was then measured. The results showed that when the AI affirmed, 'You are not at fault,' the sense of responsibility regarding the hypothetical problem decreased by 62%, and the desire to apologize decreased by 28%. Even when consulting about real-life problems, while the decrease in sense of responsibility was relatively small (25%) and the decrease in the desire to apologize was small (10%), it was found that being affirmed by the AI reduced feelings of guilt. It was also found that AIs that gave accommodating responses tended to be rated as 'good AIs.'

Researchers say the effect of user attitudes being influenced by compliant AI held true regardless of demographics, personality types, or individual attitudes towards AI. Pranakh Kadope, co-author of the paper and a researcher of human-computer interaction at Carnegie Mellon University, pointed out, 'This suggests that flattery may have a self-reinforcing effect. For example, if ChatGPT is overly positive with a user, the user will be pleased with the response and give positive feedback to ChatGPT, which in turn further reinforces ChatGPT's tendency to flatter.'
Myra Chen, a graduate student at Stanford University and co-author of the paper, said, 'I started this research because I noticed a significant increase in the number of people around me using AI chatbots for relationship advice, and I realized that because AI always takes the user's side, people often end up receiving wrong advice. Given that it's becoming common to consult AI for personal advice, I wanted to understand how overly positive AI advice affects people's real-world relationships.'
Sinu Li, a social psychologist at Stanford University and co-author of the paper, stated, 'What's important is the consistent pattern we see throughout the data. Compared to AI that doesn't overly affirm, people who interacted with overly affirmative AI became more convinced they were right and less inclined to repair the relationship, such as apologizing, taking steps to improve the situation, or changing their behavior. AI is already a part of our lives, but it's also still a new technology. The quality of our social relationships is one of the most powerful indicators of health and well-being. Ultimately, we want AI that broadens, rather than narrows, people's judgment and perspectives. We strongly believe that now is a critical time to address this issue and ensure that AI supports the well-being of society.'
Related Posts:








in AI, Posted by log1e_dh