This is what happens when you create a 1.5TB VRAM AI cluster with 4 Mac Studios and RDMA over Thunderbolt

Engineer and YouTuber Jeff Gearing tested an AI cluster consisting of four
1.5 TB of VRAM on Mac Studio - RDMA over Thunderbolt 5 | Jeff Geerling
https://www.jeffgeerling.com/blog/2025/15-tb-vram-on-mac-studio-rdma-over-thunderbolt-5
Apple didn't have to go this hard... - YouTube
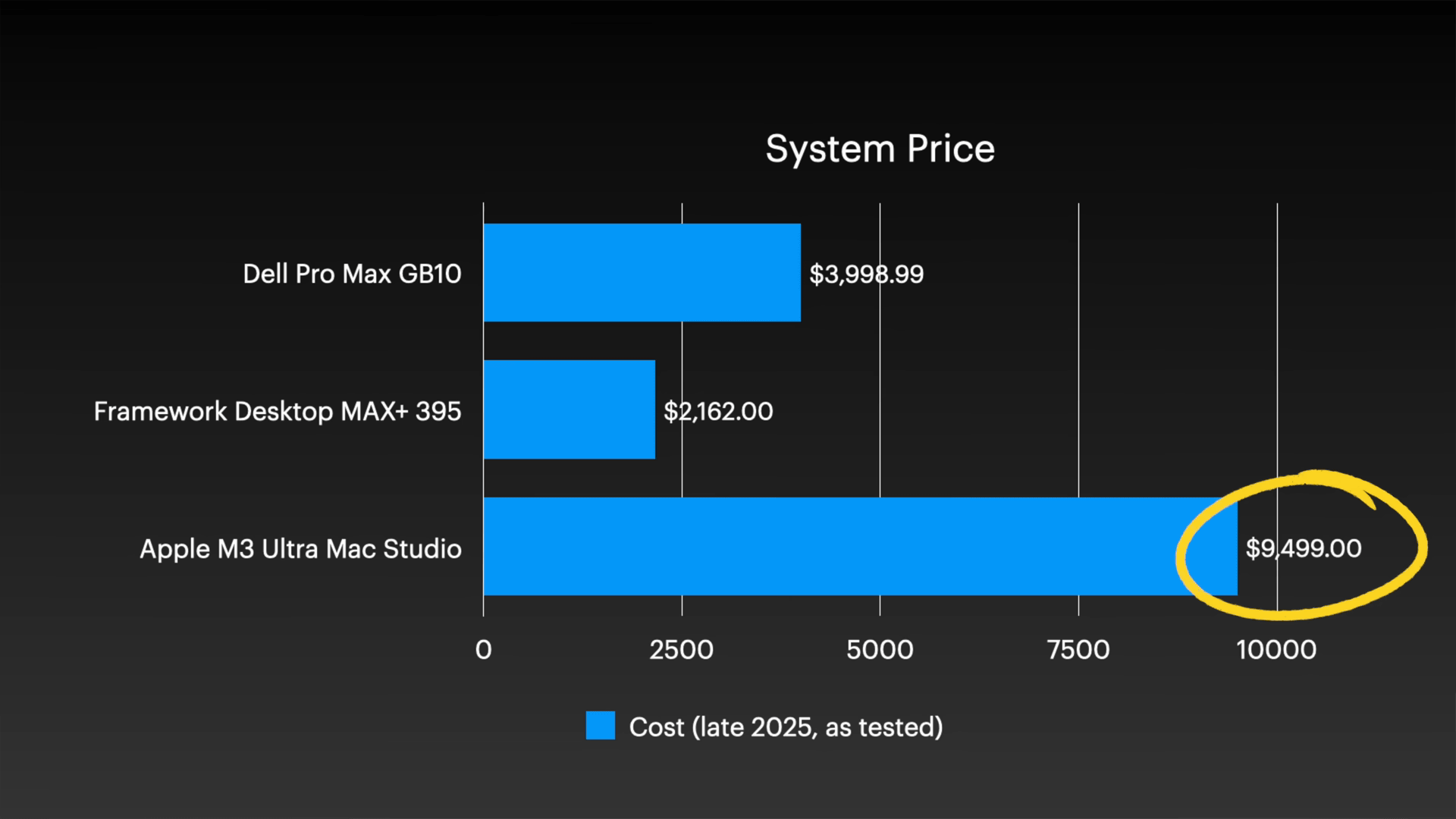
The four Mac Studios were equipped with M3 Ultra processors provided by Apple. Two of the machines were top-of-the-line configurations with 32 CPU cores, 512GB of unified memory, and 8TB of storage, while the remaining two had 256GB of unified memory and 4TB of storage. The combined total for the cluster was 1.5TB of unified memory, and the total cost for the four machines was just under $40,000.

In terms of interfaces, the Mac Studio has five Thunderbolt 5 ports in addition to a 10 Gigabit Ethernet port, and Apple says that all of these ports are RDMA over Thunderbolt capable.

To house his Mac Studio, Gearing uses a new four-post mini-rack called the TL1 from

The most difficult problem here is the placement of the power button. The Mac Studio's power button is located on the right side of the back, in a rounded corner, making it extremely difficult to access when mounted in a rack. Gearing's previous desk rack mount required a complex arm mechanism to access the button from the front, but the new mini rack has open sides, allowing him to reach in from the side and press the button.

On the other hand, the ports are located on the front of the case, making it convenient for connecting a management keyboard and monitor. Also, while many small PCs have large AC adapters installed externally to make the device look smaller, the Mac Studio has an internal power supply, which means less clutter in the rack when it comes to managing cables.

To test the performance of the Mac Studio cluster, Gearing chose two AI desktop systems for comparison:

The other system uses a Framework Desktop mainboard with AMD's

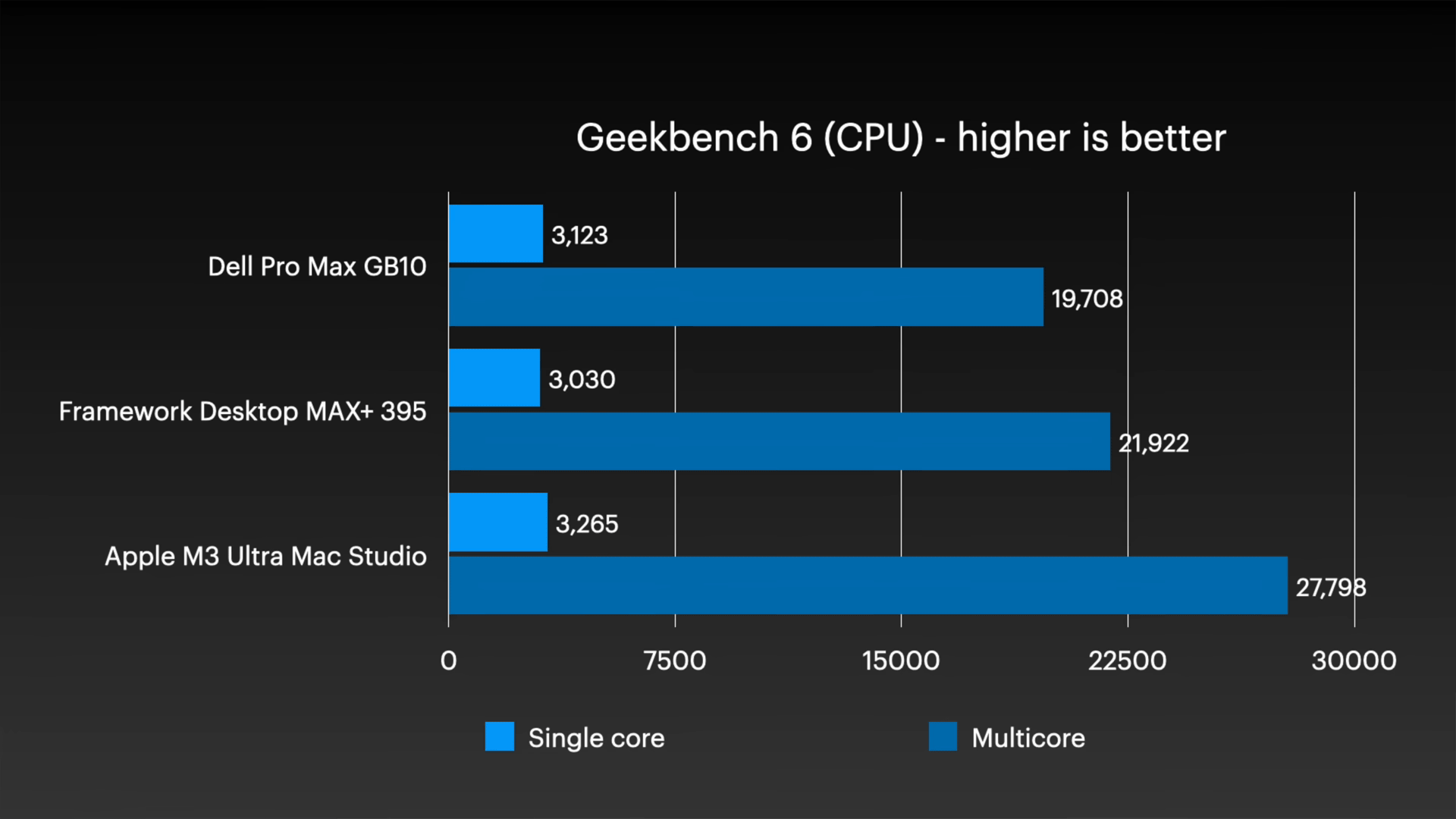
First, here's a comparison of single-core (light blue) and multi-core (dark blue) performance in Geekbench 6. The M3 Ultra Mac Studio, which is equipped with two generations of CPU cores, outperformed the Dell Pro Max with GB10 and Framework Desktop.
In double-precision (FP64) tests, the M3 Ultra Mac Studio exceeded 1 TFLOPS, nearly twice as fast as the Dell Pro Max with GB10 and more than four times faster than Framework Desktop.
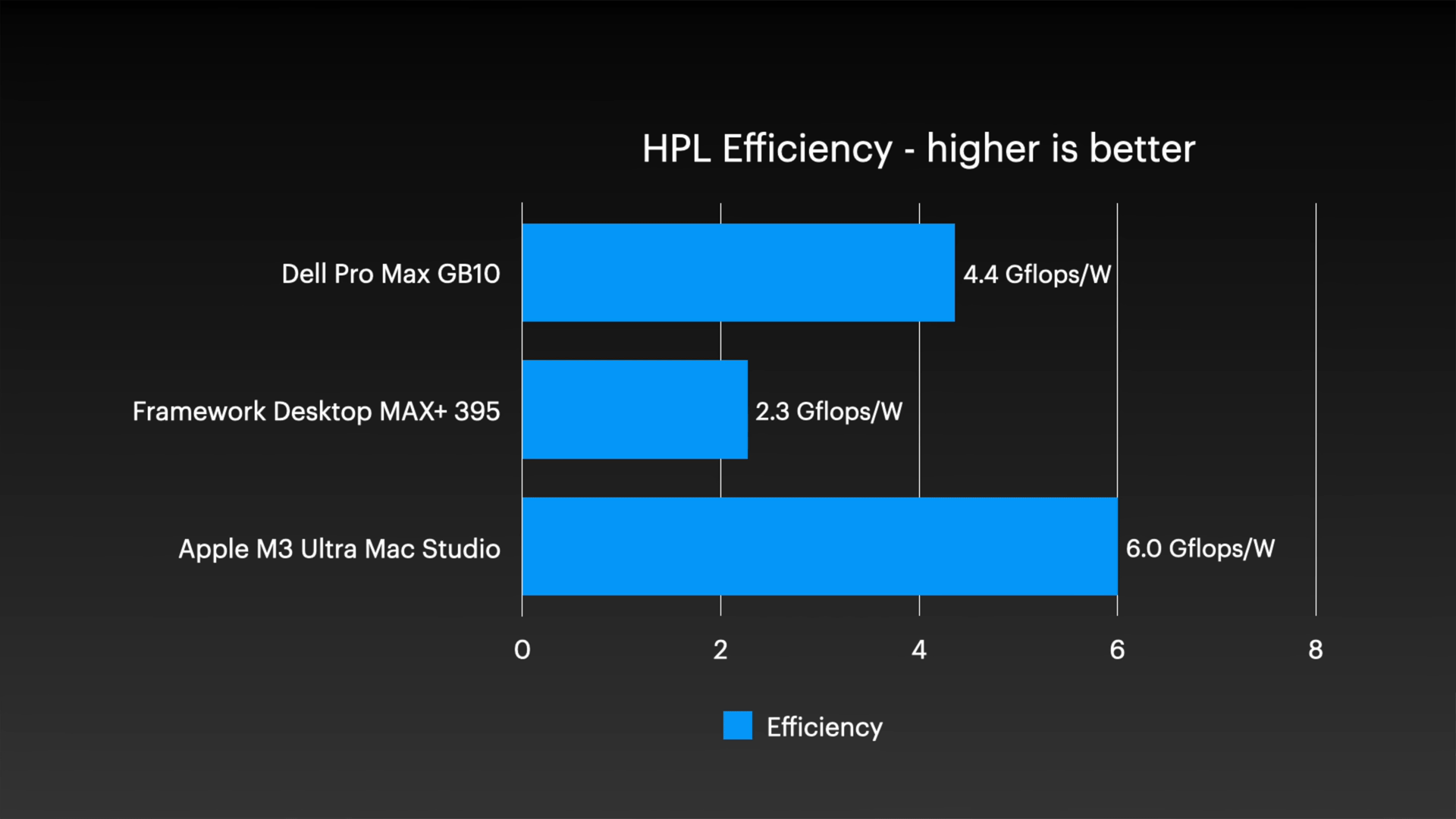
Regarding CPU efficiency, Gearing said, 'This is true of Apple's chips in general, but it's fantastic.'
The M3 Ultra Mac Studio also consumes less than 10W of power when idle.
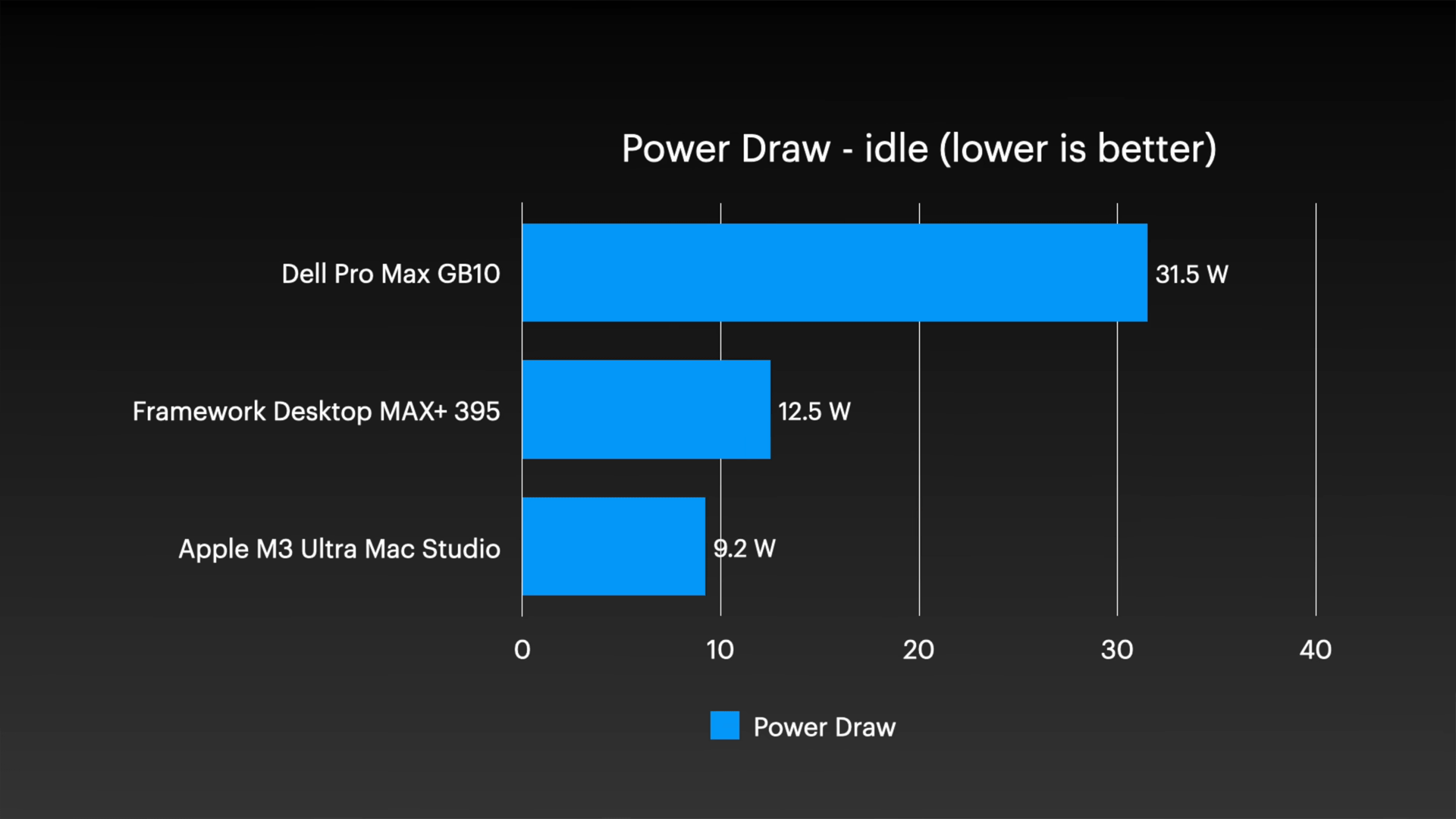
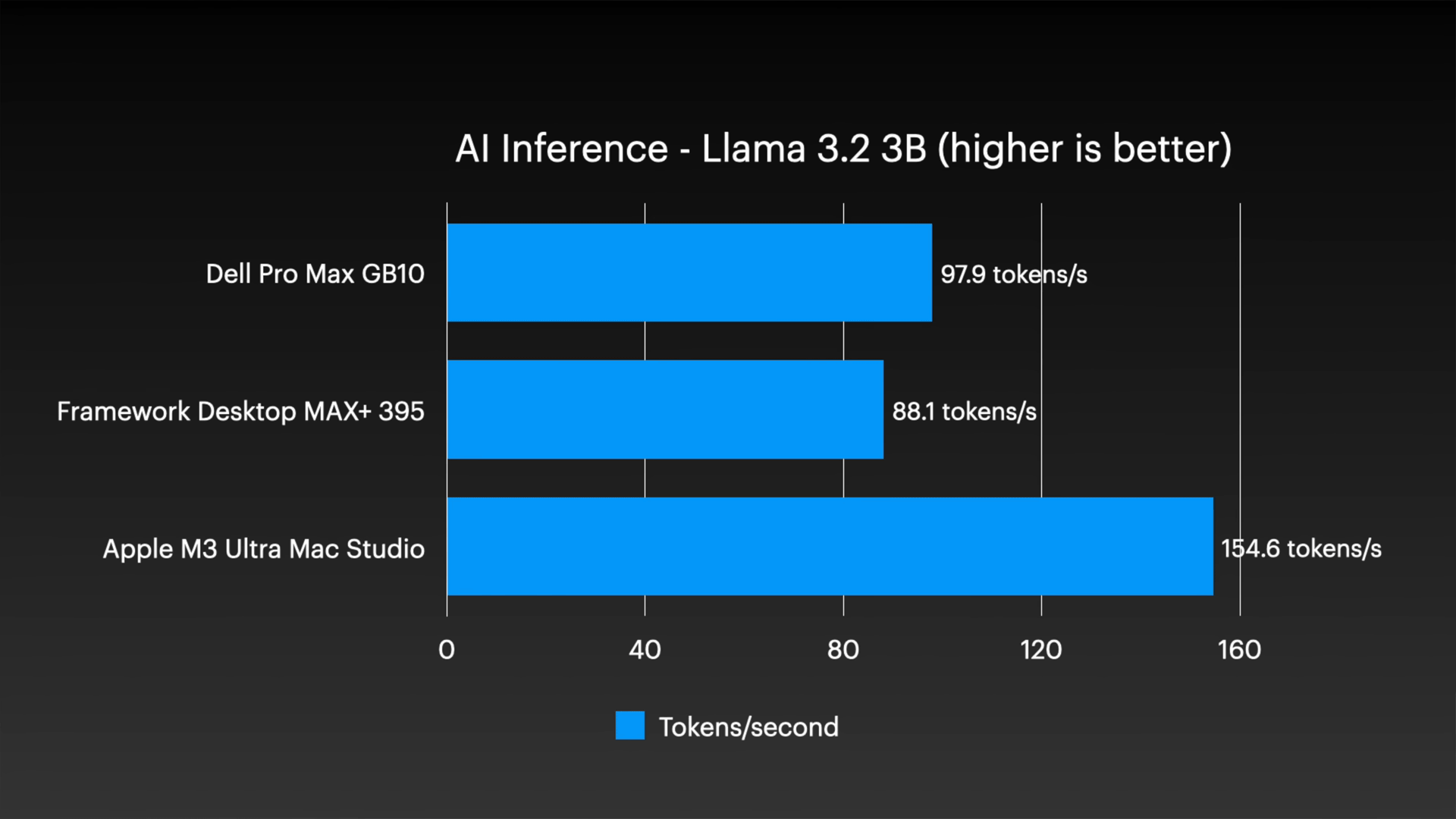
Even in the AI inference test, the Mac Studio's advantage is clear: In the test using Llama 3.2 3B, the Mac Studio recorded 154.6 tokens per second, compared to 97.9 tokens per second for the Dell and 88.1 tokens per second for the Framework.
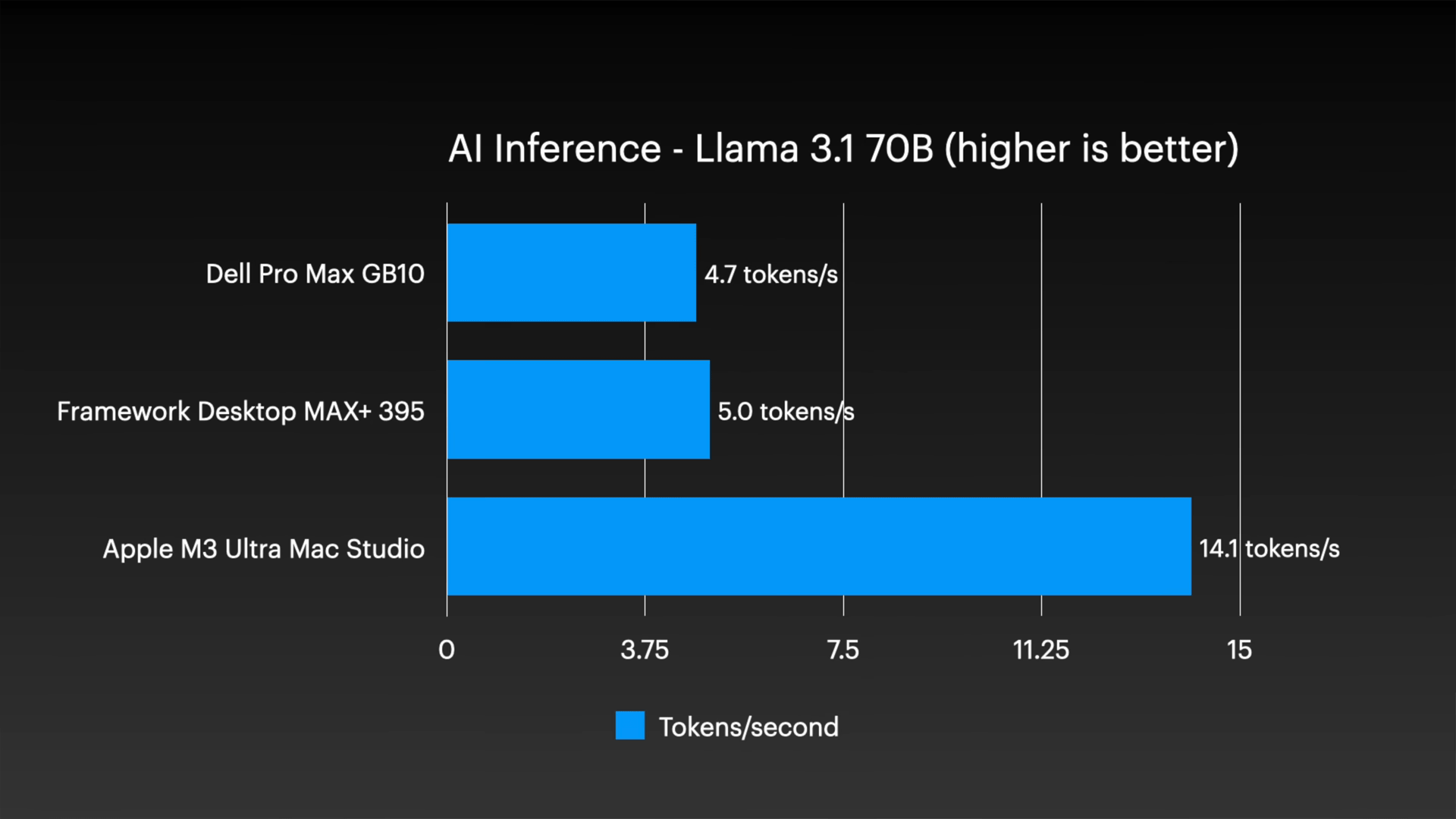
On the larger Llama 3.1 70B, the Mac Studio maintained 14.1 tokens per second, while the other two systems dropped significantly to around 5 tokens per second or less.
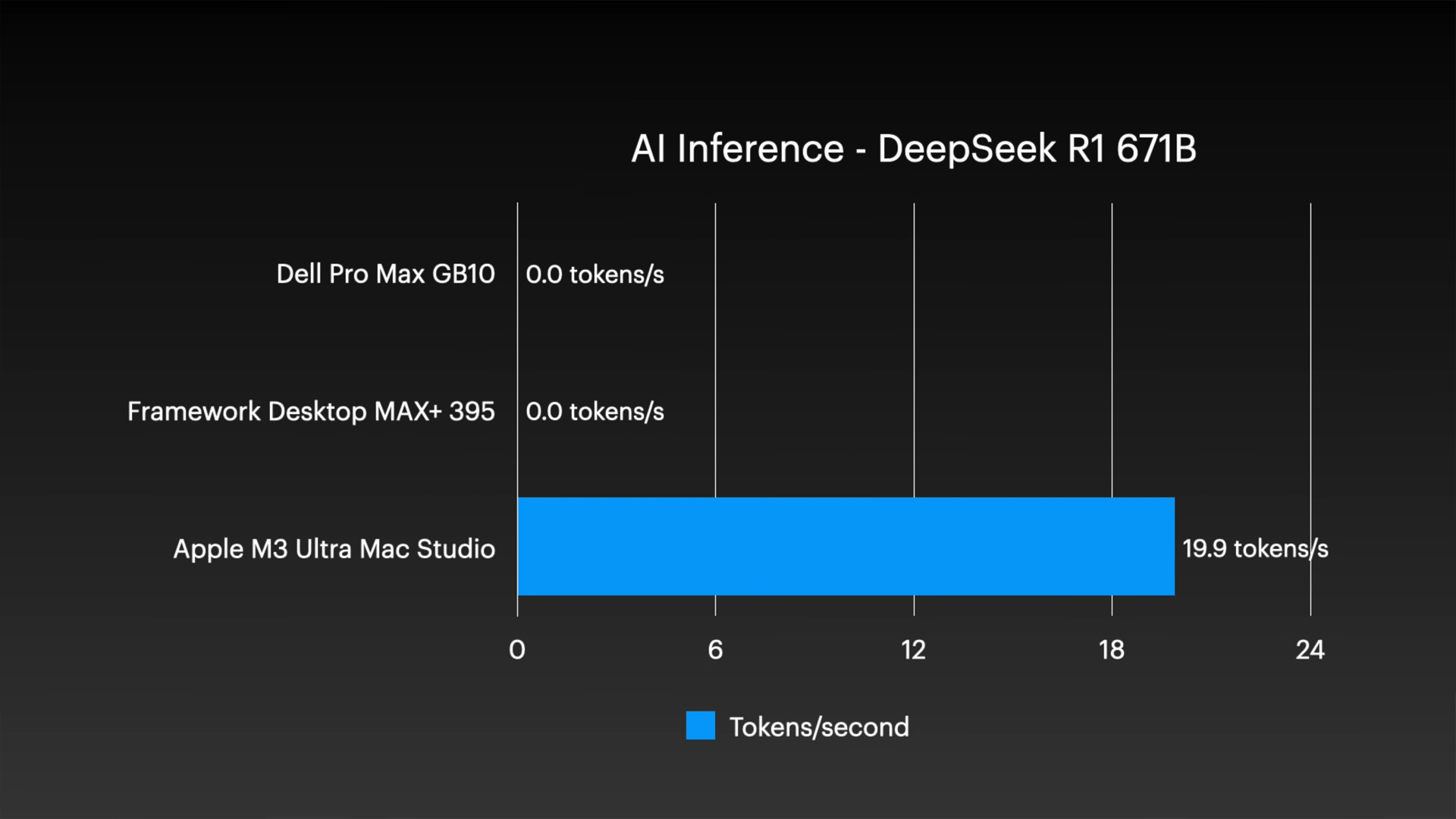
In particular, when it comes to ultra-large-scale models such as DeepSeek R1, the other two systems are unable to even run them on a single node, clearly demonstrating the advantage of the Mac Studio's huge unified memory.
However, it should be noted that the cost of a Mac Studio cluster is approximately $9,500 (approximately 1.5 million yen) per unit, which is significantly more expensive than the other two systems.
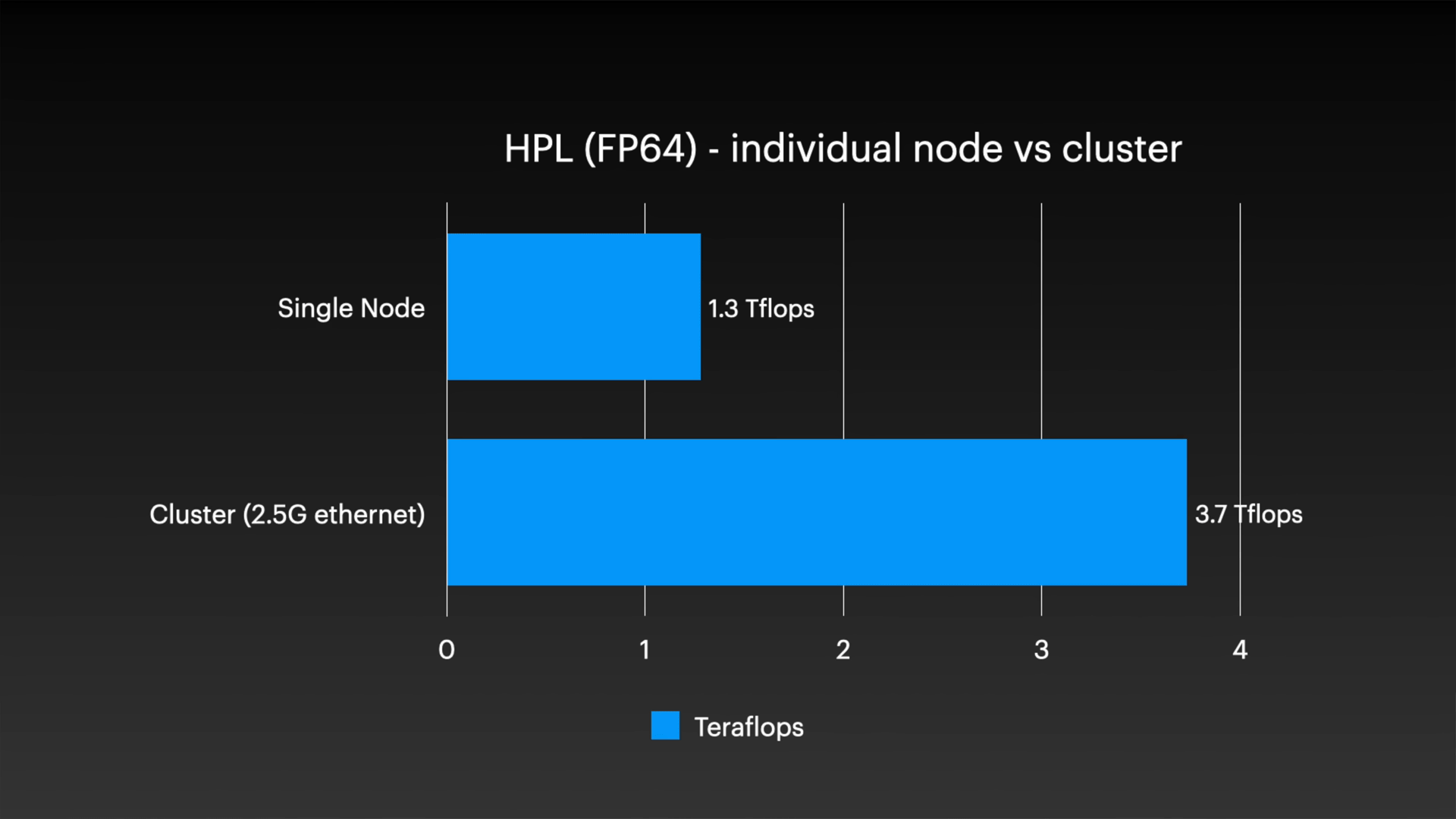
The scaling performance of clustering was also examined in detail. In tests using HPL, a four-node cluster configuration recorded 3.7 TFLOPS, compared to 1.3 TFLOPS for a single node, confirming a speed increase of approximately 2.8 times. Considering that two of the nodes in the cluster have only half the memory capacity of the others, this scaling performance is close to what we would expect.
On the other hand, when using TCP communication with Thunderbolt 5, unstable behavior was observed, with the system crashing and restarting under high load.
A comparative study of RDMA over Thunderbolt and conventional TCP communication in distributed AI inference confirmed a decisive difference in terms of network latency and scalability. To build a cluster using RDMA over Thunderbolt, Gearing uses exo, a system that connects multiple devices to a network to create a cluster for AI processing.

While memory access latency with conventional TCP-based connections was around 300 microseconds, enabling RDMA over Thunderbolt dramatically reduces it to less than 50 microseconds. This low latency allows memory distributed across multiple Mac Studios to behave as if it were one huge shared memory pool.
The results of the inference speed tests clearly show the impact that differences in communication protocols have on performance scaling. With the conventional RPC method of llama.cpp, which uses TCP connections, the more compute nodes added, the more network overhead accumulates, which tends to actually slow down the inference speed.
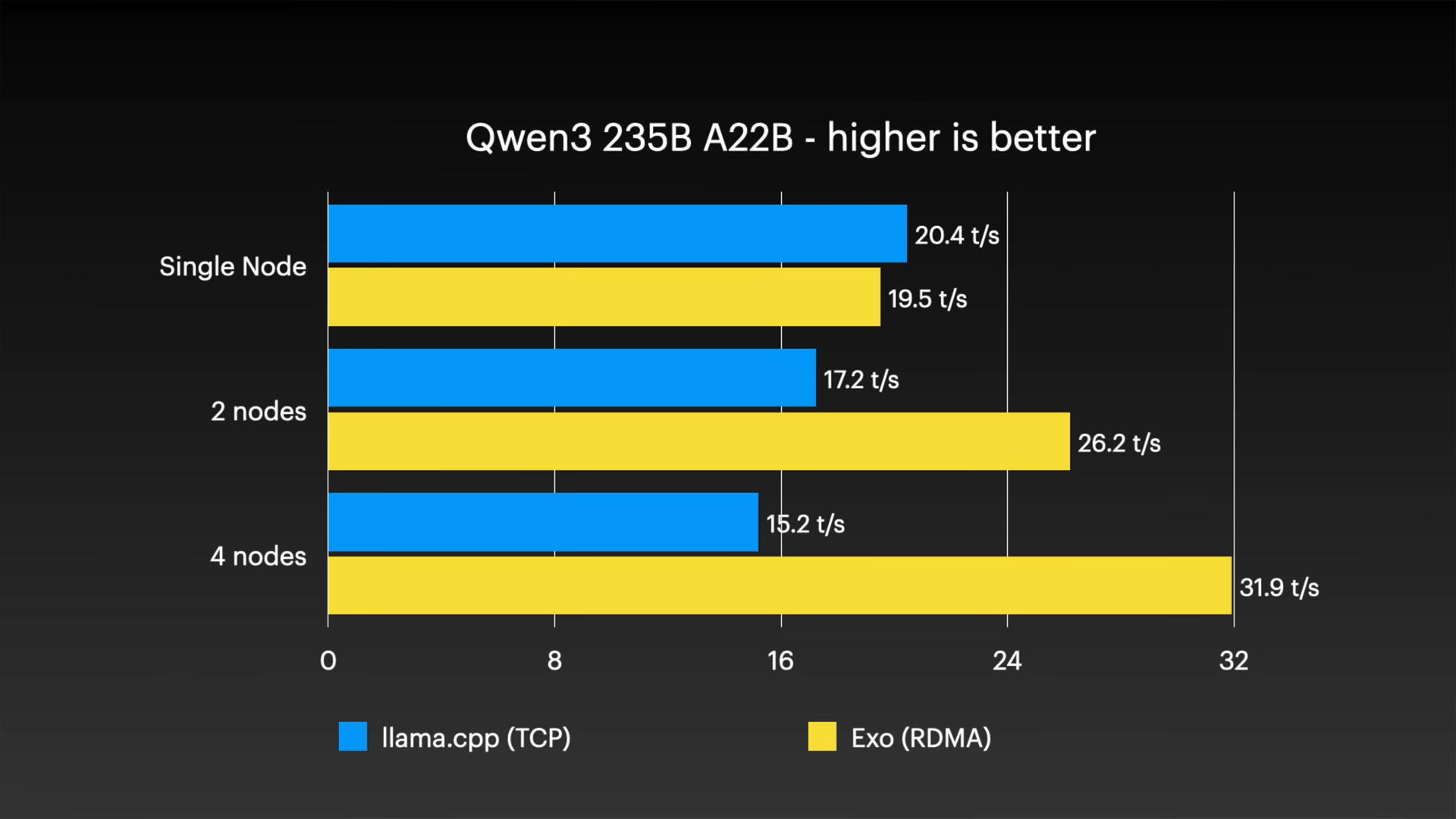
For example, in a test using the Qwen3 235B A22B model, llama.cpp's speed dropped from 20.4 tokens per second with one node to 15.2 tokens per second with four nodes. In contrast, in an exo environment with RDMA over Thunderbolt enabled, the speed increased as nodes were added, from 19.5 tokens per second with one node, and a high throughput of 31.9 tokens per second was recorded in a four-node configuration.
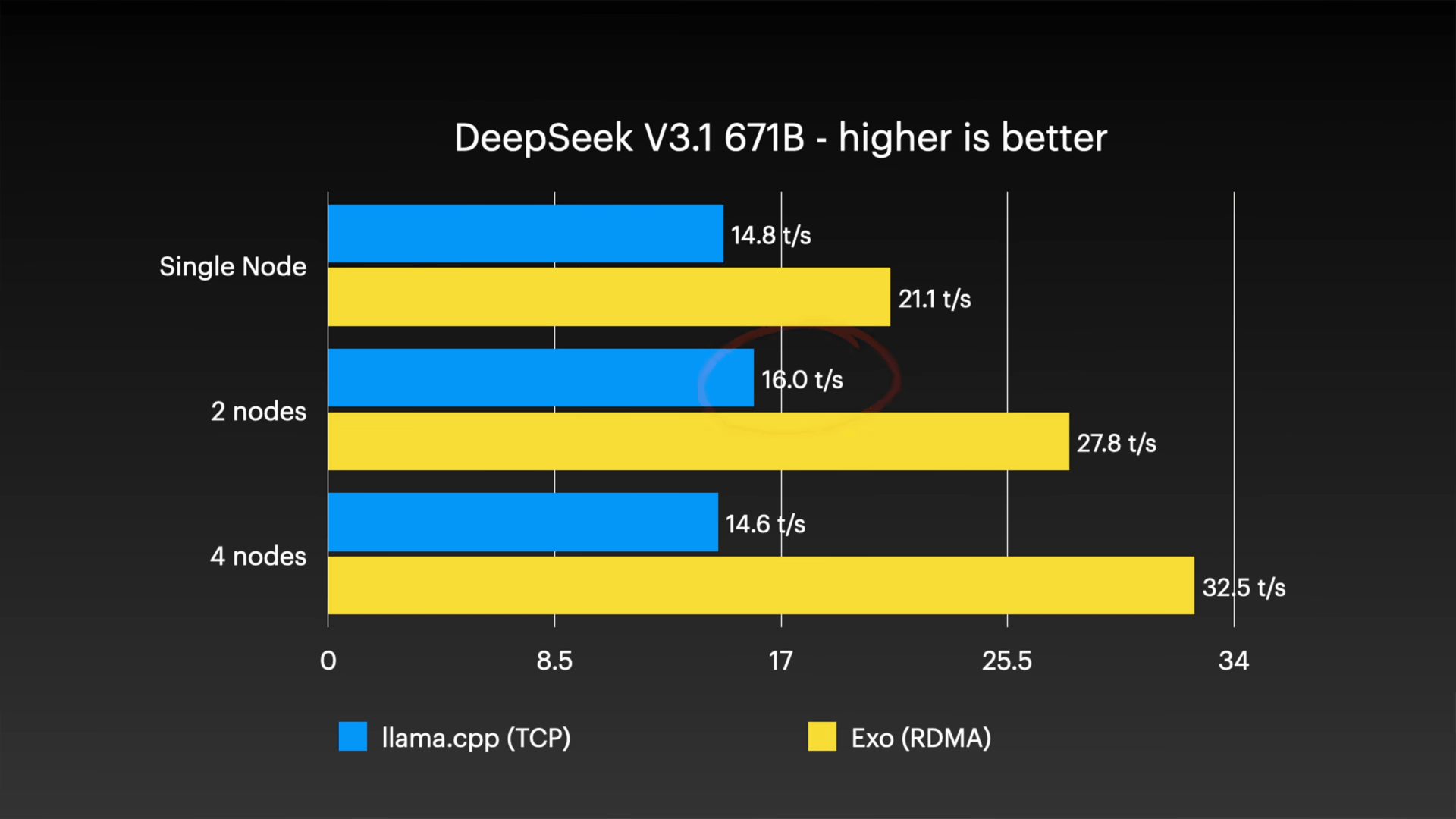
Furthermore, a similar trend was confirmed in DeepSeek V3.1, a huge model with 671 billion parameters. In the exo environment, a four-node configuration reached 32.5 tokens per second, more than double the performance of llama.cpp (TCP), which reached 14.6 tokens per second.
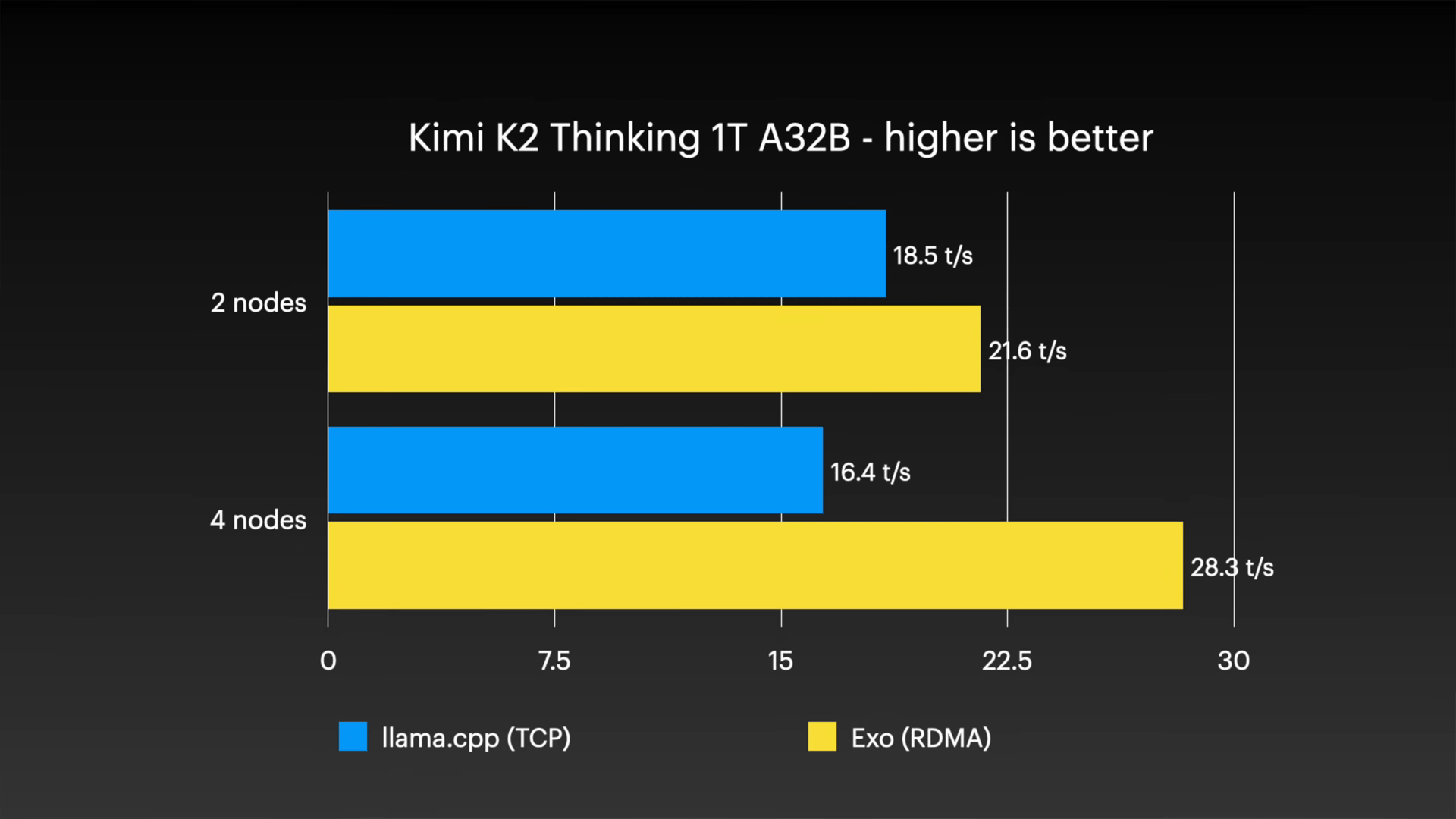
In addition, the Kimi K2 Thinking model, which is the largest model tested in this test with 1 trillion parameters (32 billion active parameters), recorded 28.3 tokens per second in a four-node configuration in the exo environment, achieving a practical level of interaction speed.
However, the exo used in this test is a pre-release version, and although many bugs have been fixed during testing, there are still some stability issues. In particular, RDMA over Thunderbolt is a new technology, so while it performs very well while working properly, it can also be unstable and cause the system to become uncontrollable if a problem occurs.
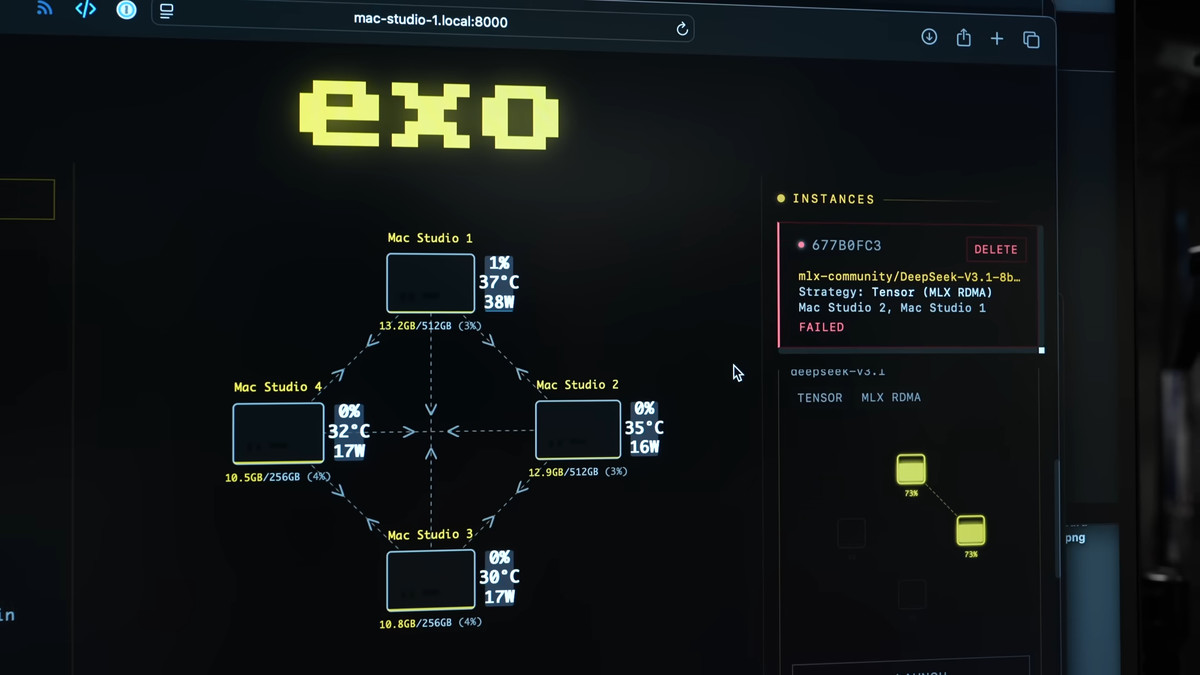
To prepare for such unstable operation, Gearing had set up the configuration management tool Ansible in advance. This allowed him to quickly shut down and restart all nodes through a script, rather than having to manually operate each node one by one, even when the entire cluster stopped, which Gearing says was a great help in continuing the verification work.
Gearing pointed out that the exo development team had been inactive for a while, and the development process with Apple was unclear, so both the hardware and software were still in the development stage.
Related Posts: