Claude Sonnet's AI model 'MiniMax M2' is open source and twice as fast as the original model at just 8% the price, and paid APIs are available for free for a limited time

MiniMax M2 & Agent: Ingenious in Simplicity - MiniMax News
https://www.minimax.io/news/minimax-m2

Alibaba-Backed MiniMax Unveils Open-Source LLM M2, Rivaling Claude at 8% Cost
https://www.webpronews.com/alibaba-backed-minimax-unveils-open-source-llm-m2-rivaling-claude-at-8-cost/
MiniMax-M2 Open-Sourced, Outsmarts Claude Opus 4.1 in New AI Intelligence Index
https://analyticsindiamag.com/ai-news-updates/minimax-m2-open-sourced-outsmarts-claude-opus-4-1-in-new-ai-intelligence-index/
The open-sourced MiniMax M2 is an AI model that combines advanced coding capabilities with high agent performance. Designed for end-to-end developer workflows, MiniMax M2 offers the same powerful coding capabilities as coding-oriented AIs such as Claude Code, Cursor, Cline, Kilo Code, and Droid. It also stably handles long-term toolchain operations such as mcp , shells, browsers, information search, and Python code interpreters.
We're open-sourcing MiniMax M2 — Agent & Code Native, at 8% Claude Sonnet price, ~2x faster
— MiniMax (official) (@MiniMax__AI) October 27, 2025
⚡ Global FREE for a limited time via MiniMax Agent & API
- Advanced Coding Capability: Engineered for end-to-end developer workflows. Strong capability on a wide-range of applications… pic.twitter.com/FoiAz9NF4q
MiniMax said, 'There was no single AI model that fully met our needs for an agent. The challenge was to find an AI model that achieved the right balance of performance, price, and inference speed. This is almost an 'impossible triangle'. Excellent overseas AI models offer excellent performance, but are very expensive and relatively slow. Chinese models are inexpensive, but there are differences in performance and speed. As a result, existing agent products are often too expensive or slow to achieve good results. For example, many agent subscriptions cost tens of dollars (thousands of yen) per month, or even hundreds of dollars (tens of thousands of yen), and can take several hours to complete a single task. '
Therefore, MiniMax has been exploring the development of an AI model that offers a better balance of performance, price, and inference speed, and the result is the MiniMax M2.
The graph below compares the performance of MiniMax M2 against six competing AIs: DeepSeek-V3.2, GLM-4.6, Kimi K2 0905, Gemini 2.5 Pro, Claude Sonnet 4.5, and GPT-5 (thinking). The MiniMax M2 consistently demonstrates high performance across various benchmarks.
In the areas of 'Tool Use' and 'Deep Search,' MiniMax commented, 'MiniMax M2 has succeeded in achieving performance very close to that of cutting-edge AI models overseas. Although it is slightly behind cutting-edge overseas models in terms of programming ability, it is already among the best in the domestic market.'
Developers, including business and back-end teams, are working with algorithm engineers, putting significant effort into building and evaluating environments, and increasingly integrating AI into their daily work. After mastering these complex scenarios, they have discovered that by applying the techniques they have accumulated to traditional large-scale model tasks, such as knowledge and mathematics, they can naturally achieve superior results, MiniMax explained.
For example, in the
The API price for MiniMax M2 is $0.3 (approximately 46 yen) per million input tokens and $1.2 (approximately 183 yen) per million output tokens. This price is about 8% of Claude 3.5 Sonnet, but the inference speed of MiniMax M2 is twice as fast.
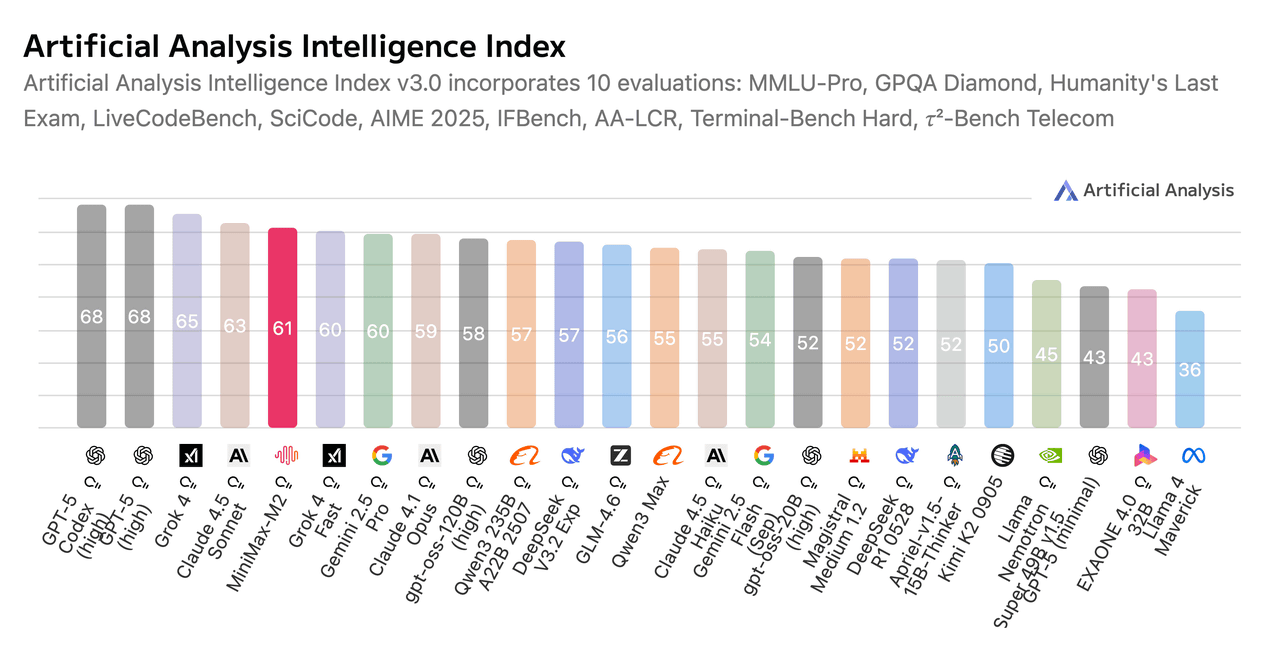
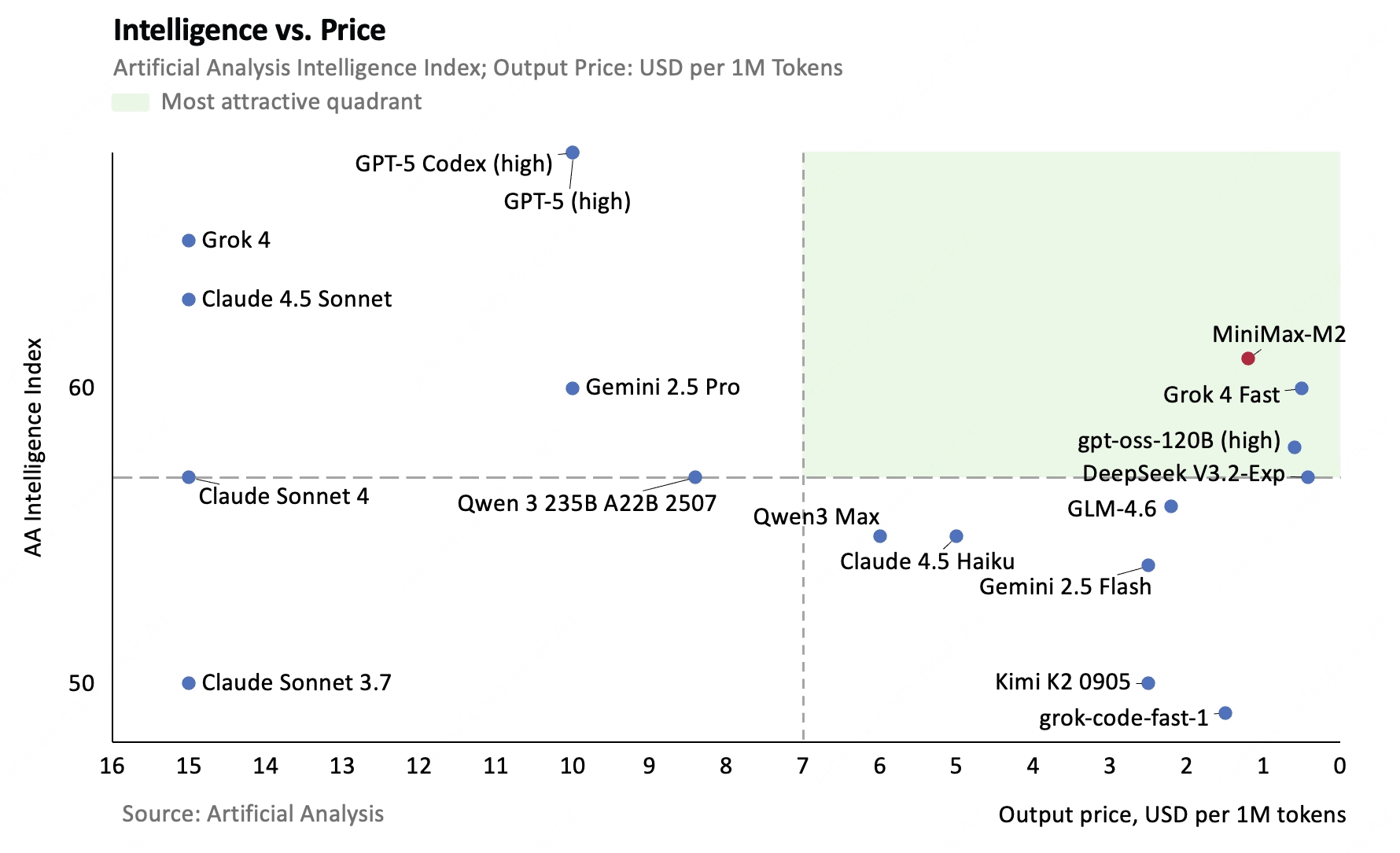
The graph below compares the performance and price of each AI model. The vertical axis represents performance (higher performance at the top) and the horizontal axis represents price (lower price at the right). It is clear that the MiniMax M2 is an AI model with a good balance of performance and price.
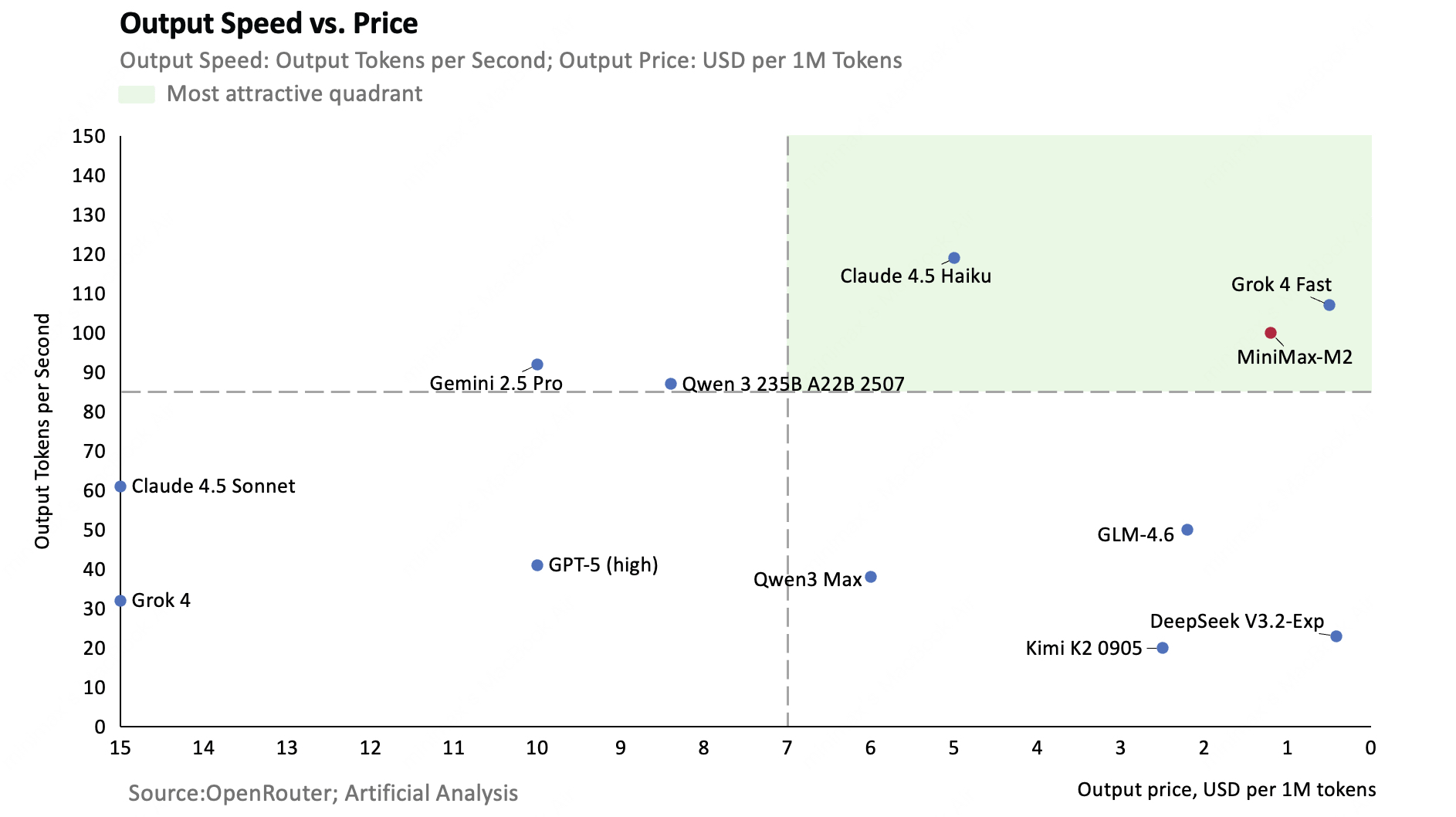
The graph below compares the inference speed (vertical axis) and price (horizontal axis) of each AI model. While the inference speed is top class, the price is also among the lowest.
In addition, MiniMax will provide the MiniMax M2 API free of charge as a trial period until midnight on November 7, 2025 UTC.
The MiniMax M2 is also available on Hugging Face.
MiniMaxAI/MiniMax-M2 · Hugging Face
https://huggingface.co/MiniMaxAI/MiniMax-M2
Simon Willison explained the MiniMax M2: 'It's an MIT-licensed AI model, and self-reported benchmarks show it performs on par with Claude Sonnet 4, but not as well as Claude Sonnet 4.5. The deployment size on Hugging Face is 230GB, so it probably won't fit on an NVIDIA Spark 128GB, but should work on a Mac Studio 512GB.'
MIT licensed model, their self-reported benchmarks show it performing similar to Claude Sonnet 4 (but still behind 4.5), and it's only 230GB on Hugging Face
— Simon Willison (@simonw) October 27, 2025
So likely won't fit on an NVIDIA Spark's 128GB but should run on a Mac Studio 512GB https://t.co/jzJ0GiDXj5
Yifan Zhang said, '1: Minimax uses a GPT-OSS-like structure, that is, full attention and sliding window attention (SWA) are alternated. 2: It uses the QK norm, and every attention head has its own learnable RMS norm. 3: The full attention and SWA parts do not share settings. Each has its own RoPE theta setting.' Regarding the reason for not using linear attention, he pointed out, 'Flash attention (Dao et al.) is very effective and supports low-precision training and inference (FP8/FP4), but linear attention does not work at low precision!'
💡Some fun facts about Minimax M2:
— Yifan Zhang (@yifan_zhang_) October 27, 2025
1. Minimax uses GPT-OSS-like structure, ie, Full Attention interleaved with Sliding Window Attention (SWA).
2. It uses QK Norm, and every single attention head has its own unique, learnable RMSNorm.
3. The full attention and SWA parts… https://t.co/XBsvPFhBVt pic.twitter.com/CoSzljm3NB
Some people have pointed out that the model type of the MiniMax M2 is 'mixtral.'
M2 open sourced. That could be expected from them reporting the params upfront, but still I didn't want to believe too early and get disappointed. Stellar ethics.
— Teortaxes▶️ (DeepSeek Advice🐋铁 powder 2023 – ∞) (@teortaxesTex) October 27, 2025
Except: model_type 'mixtral'? What even is mixtral about it?
Some interesting research trajectory happened here… https://t.co/mZErdi5vSU pic.twitter.com/X7hIqS7eIN
Additionally, MiniMax M2 will be available with Day-0 support for vLLM, which will enable fast and efficient inference and smooth long-text context performance.
🎉 Congrats to the @MiniMax__AI team for releasing MiniMax-M2 model!
— vLLM (@vllm_project) October 27, 2025
Built for advanced coding and agentic tasks, MiniMax-M2 is now available with Day-0 support on vLLM, bringing fast, efficient inference and smooth long-context performance.
vLLM is proud to power the next… https://t.co/LZmvL2ZRTC
Related Posts:






in AI, Posted by logu_ii