'Vibe' is a free, offline audio and video transcription service that uses OpenAI's Whisper and runs on Windows, macOS, and Linux, and is also compatible with YouTube.
AI has made it easy to transcribe audio files and videos, but setting up a transcription-capable AI on your PC can be a bit of a hassle. Vibe , an open-source transcription tool, can be easily installed by anyone on Windows, macOS, or Linux, and is optimized to run on NVIDIA, AMD, and Apple GPUs. Vibe allows for completely offline transcription, and data never leaves the device.
Vibe.
thewh1teagle/vibe: Transcribe on your own!
https://github.com/thewh1teagle/vibe
At the time of writing, Vibe version 3.0.5 has been released. To install it on a Windows environment, download 'vibe_3.0.5_x64-setup.exe' from the release page . The file size is approximately 24MB.
Launch the installer and click 'Next'.
After specifying the installation location, click 'Next.' The capacity required for installation was approximately 86.7MB.
Once the installation is complete, click 'Next'.
Vibe will start. When you start it for the first time, the OpenAI Whisper Large model (V3) will be downloaded.
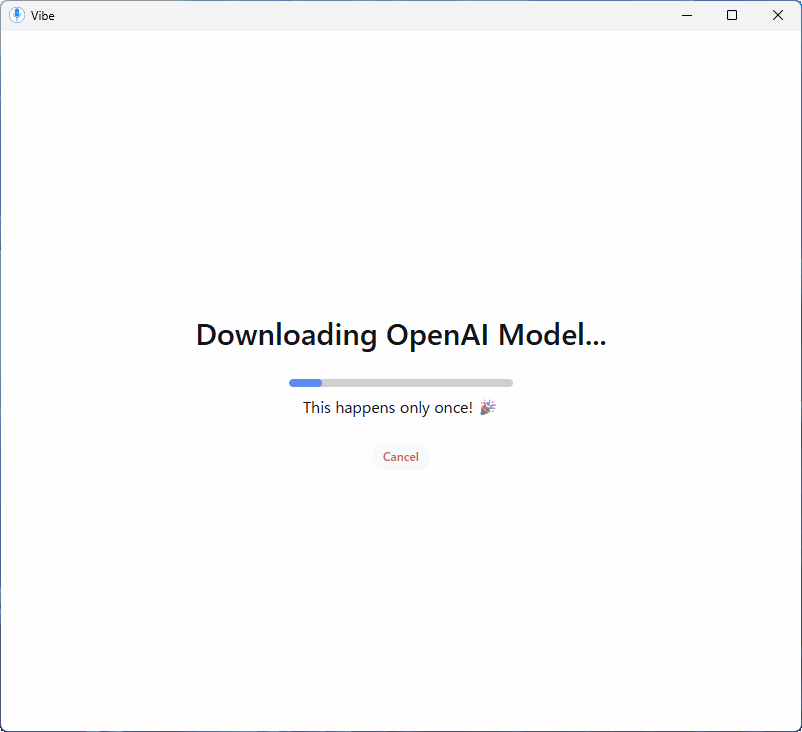
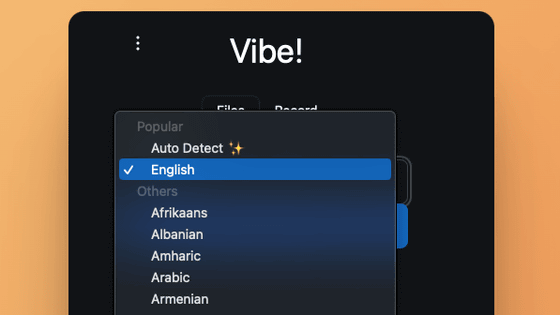
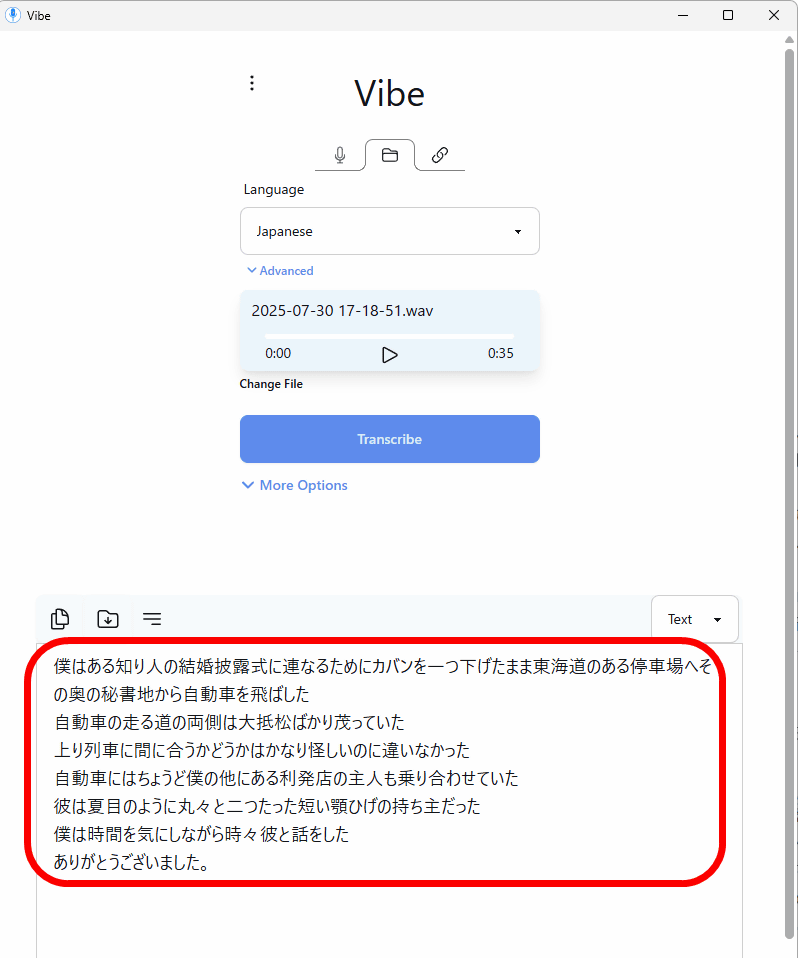
This is what it looks like when you start it up. Select 'Japanese' in 'Language' and click 'Select File' to select the file you want to transcribe.
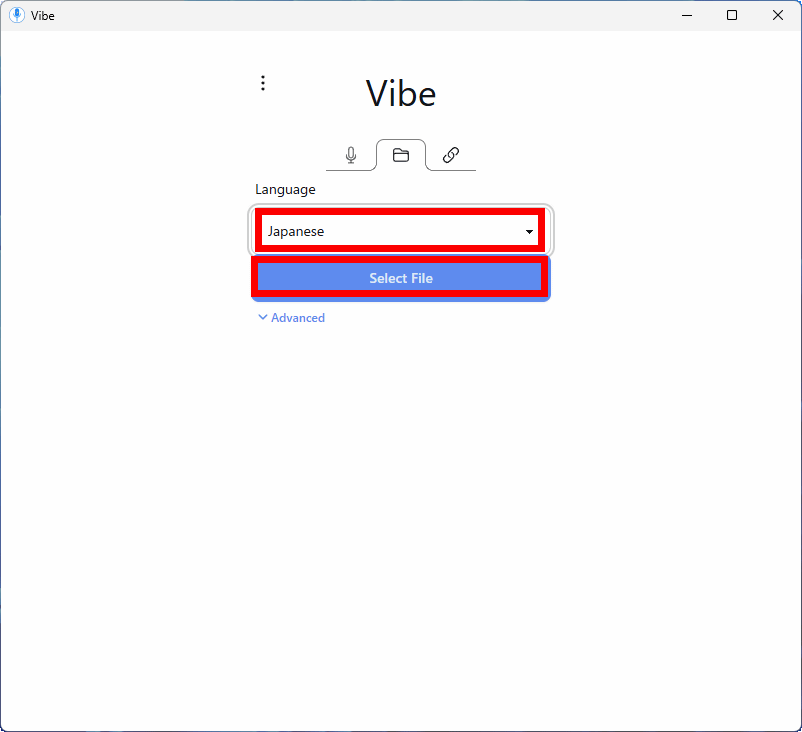
This time, I tried loading the audio of 'I Am a Cat' that I had read aloud before. Click 'Transcribe.'
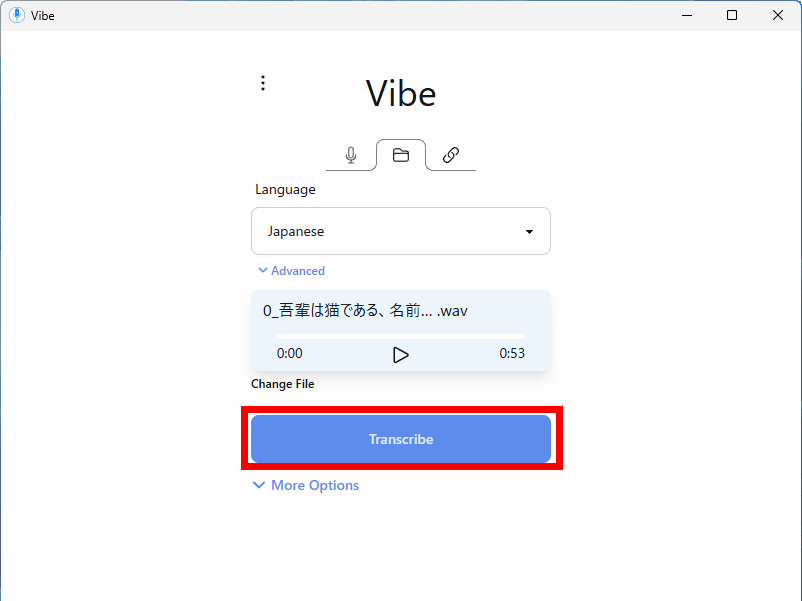
The transcribed text was then displayed at the bottom of the screen. Although there were some kanji mistranslations, the transcription accuracy was such that it required almost no corrections.
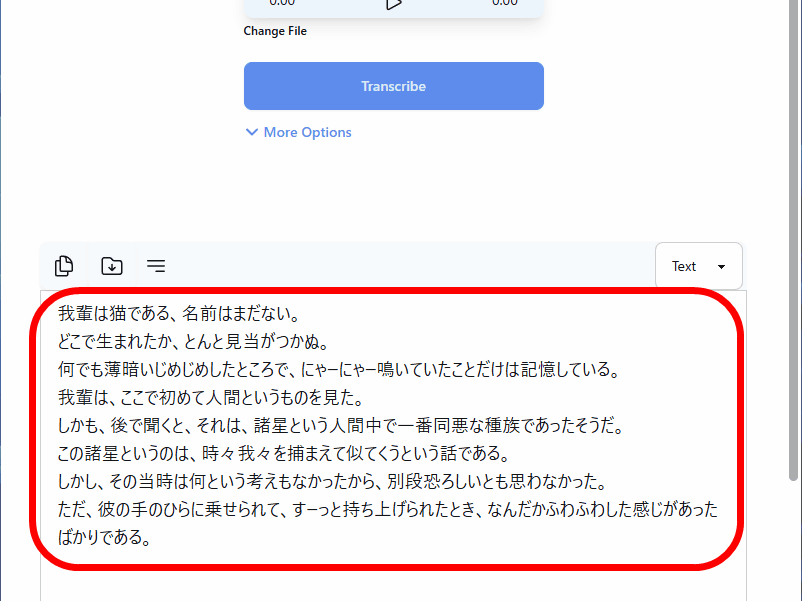
In the top left corner of the text output field, you can right-justify 'Copy,' 'Save,' and 'Text.'
In the top right corner, you can select the output format.
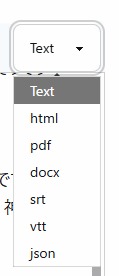
In addition to text format, you can choose from HTML, PDF, DOCX, SRT, VTT, and JSON.
Click the kebab icon in the upper left corner of the screen and click 'Settings' to make the settings.
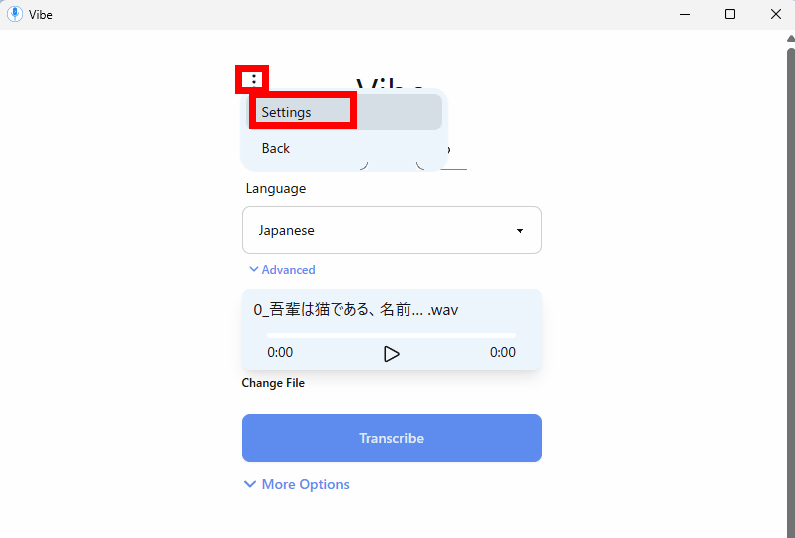
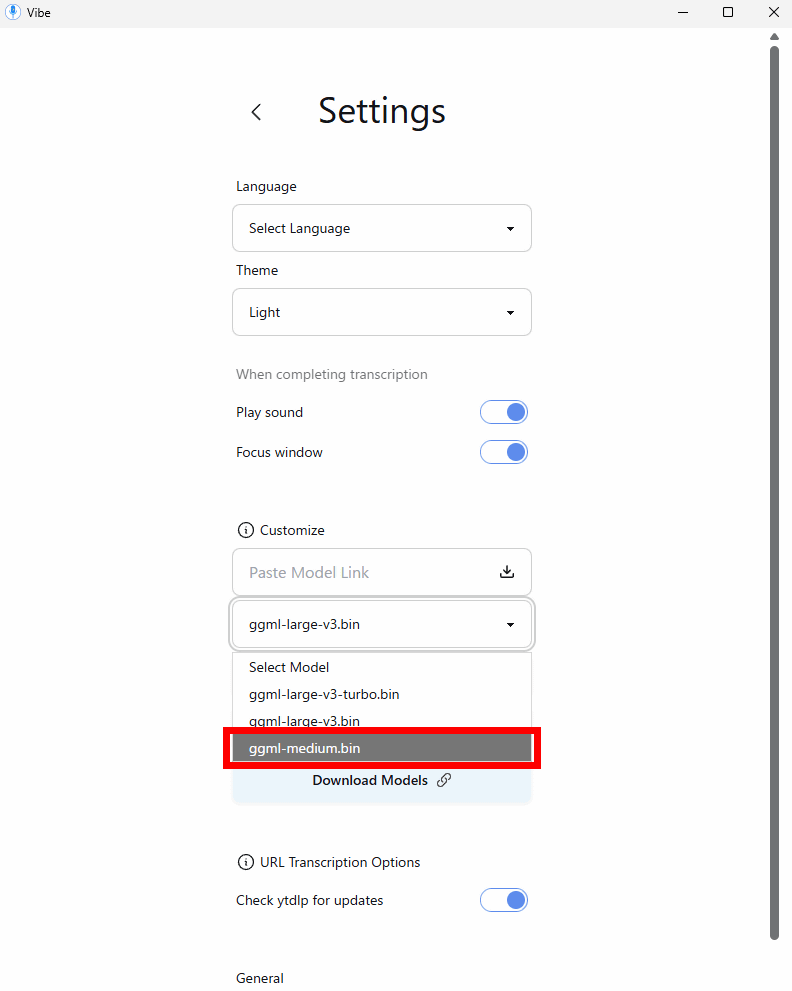
In the settings screen, you can select the AI model to use for transcription. By default, only Whisper's Large model (V3) is installed, but you can download other models. In the 'Customize' section, click 'Download Models.'
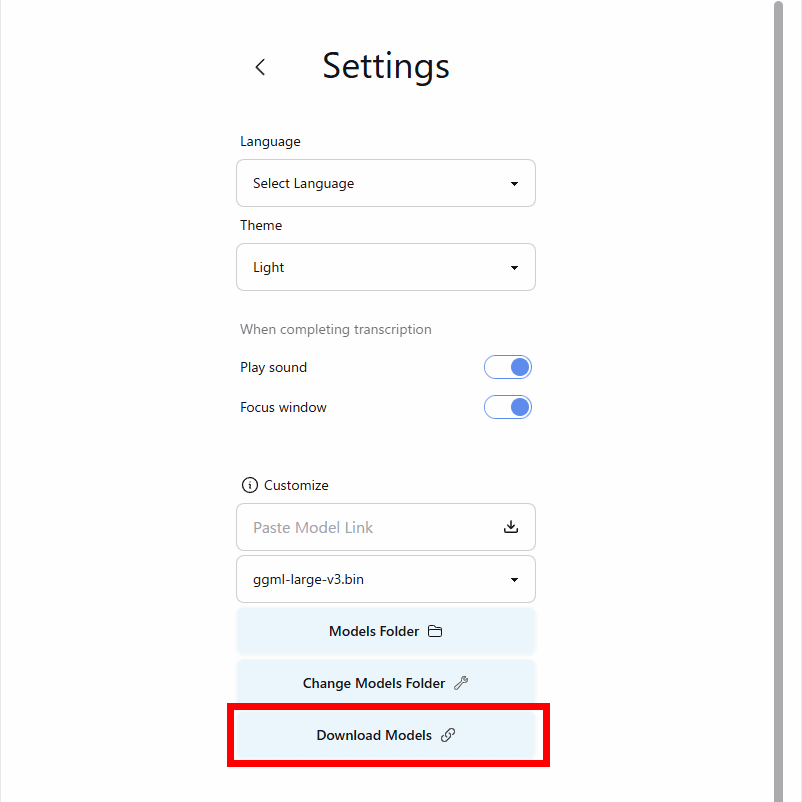
This will launch a web browser and take you to the model download page. Since we are going to download the Medium model, click on 'Magic Setup' for the Medium model.
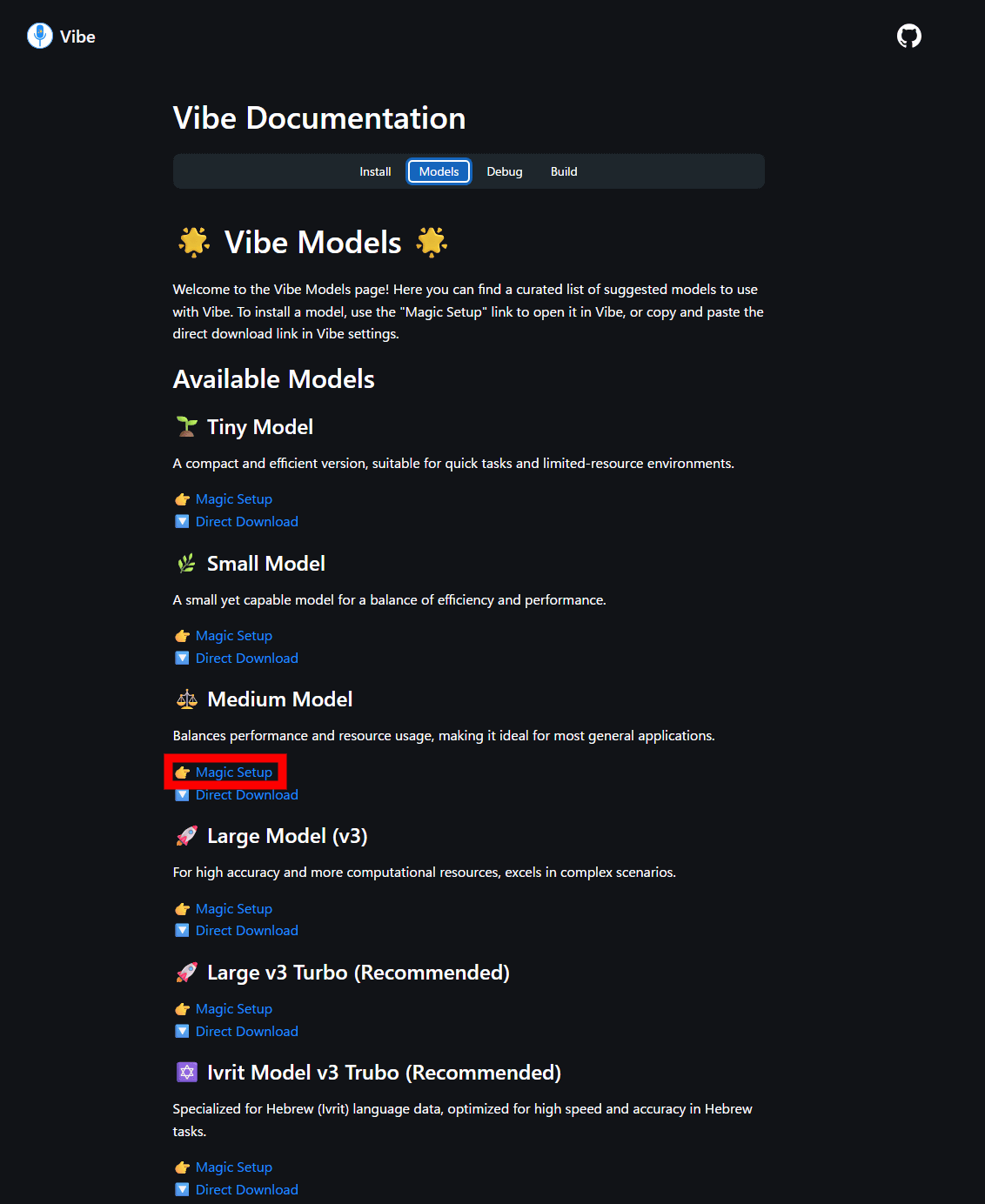
Then, the browser will ask 'Do you want to open vibe?' Click 'Open vibe'.
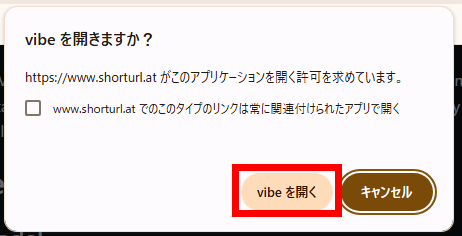
You will be asked, 'Do you want to download the model from Hugging Face?' Click 'Yes' and the model will start downloading automatically.
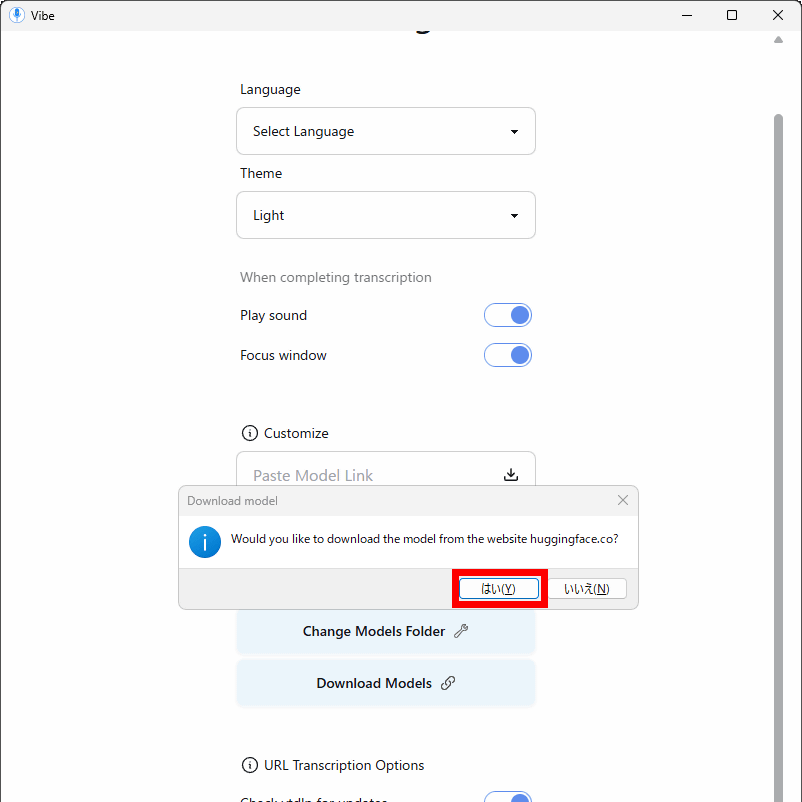
After the download was complete, I looked at the drop-down menu and saw that the model had been added.
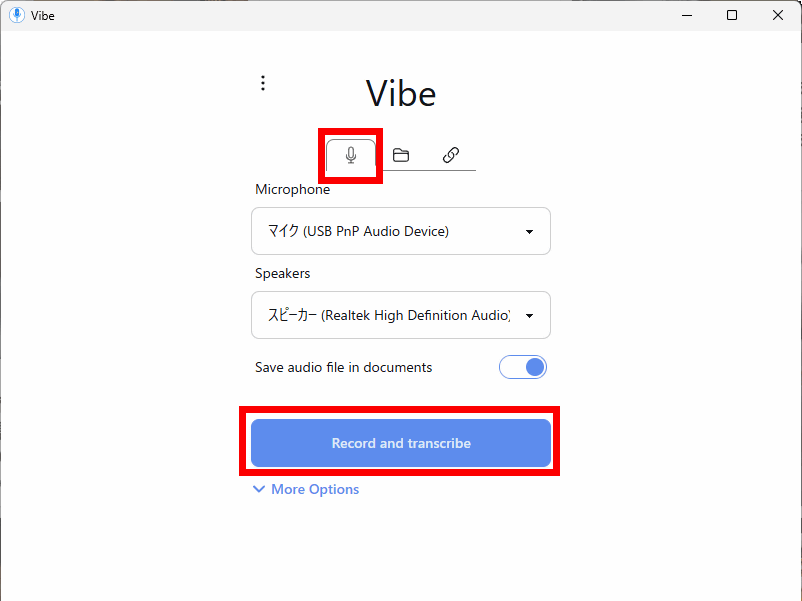
You can also record and transcribe in real time by clicking the microphone icon tab at the top of the screen. After setting up your microphone and speaker, click 'Record and transcribe.'
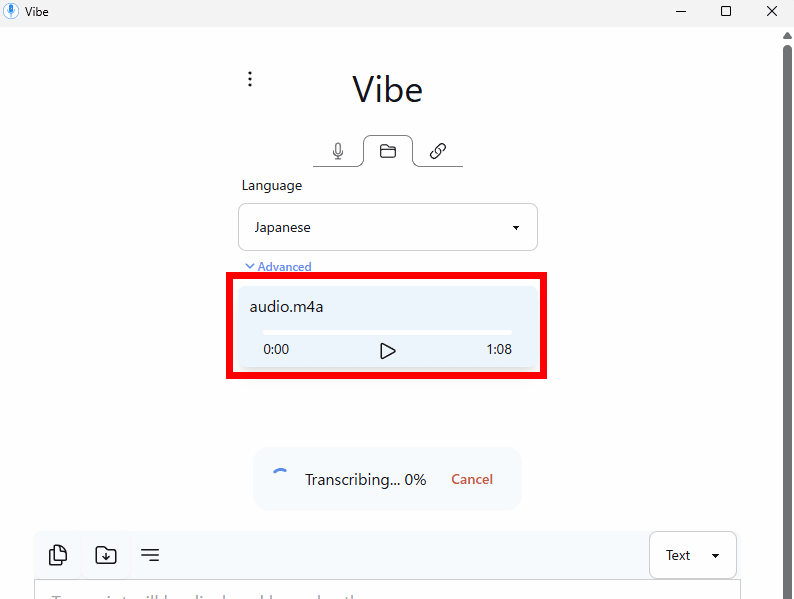
The audio recorded by the microphone will be imported directly into transcription mode.
Here's what the Medium model looks like when I read the opening of Akutagawa Ryunosuke's '
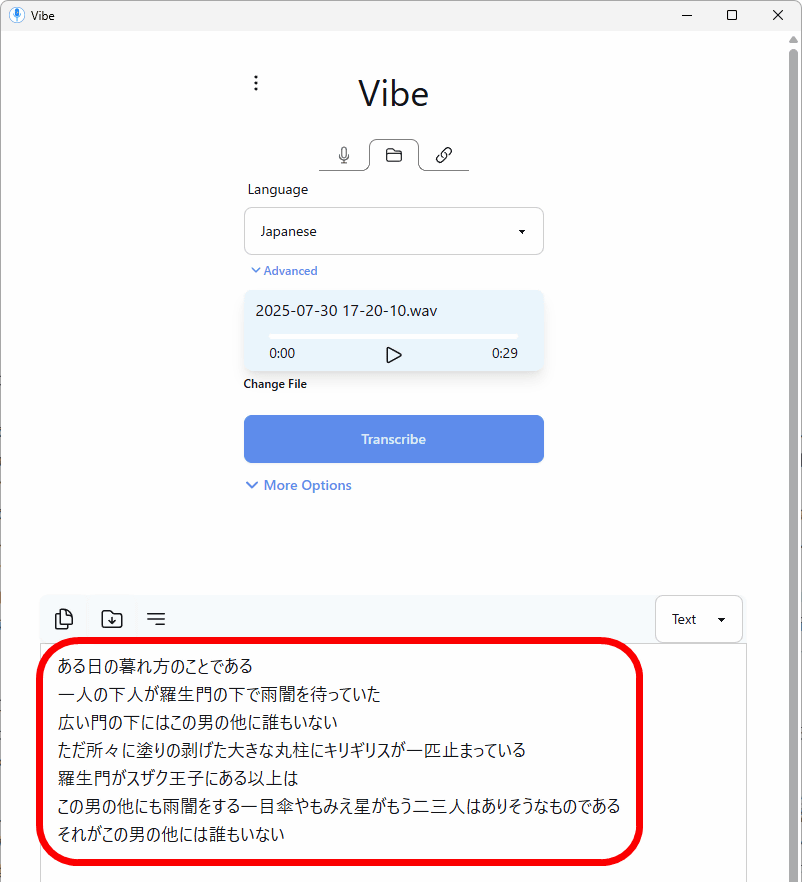
However, when I recorded and transcribed a reading of Ryunosuke Akutagawa's '
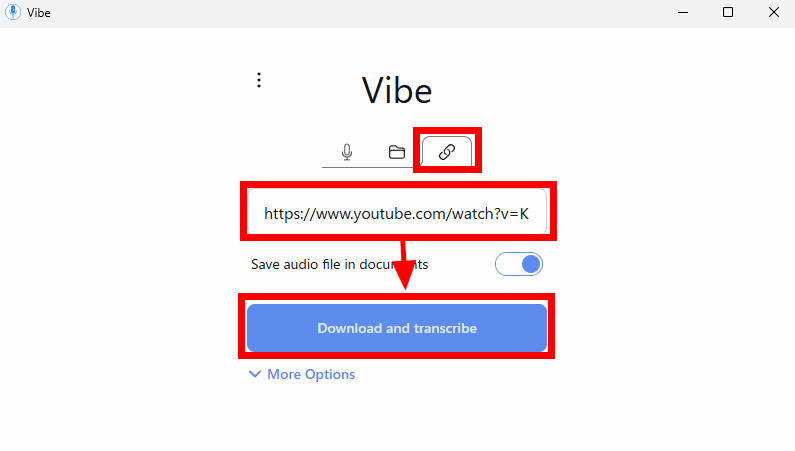
The clip icon tab at the top right of the screen allows you to transcribe YouTube videos and other online audio files. While
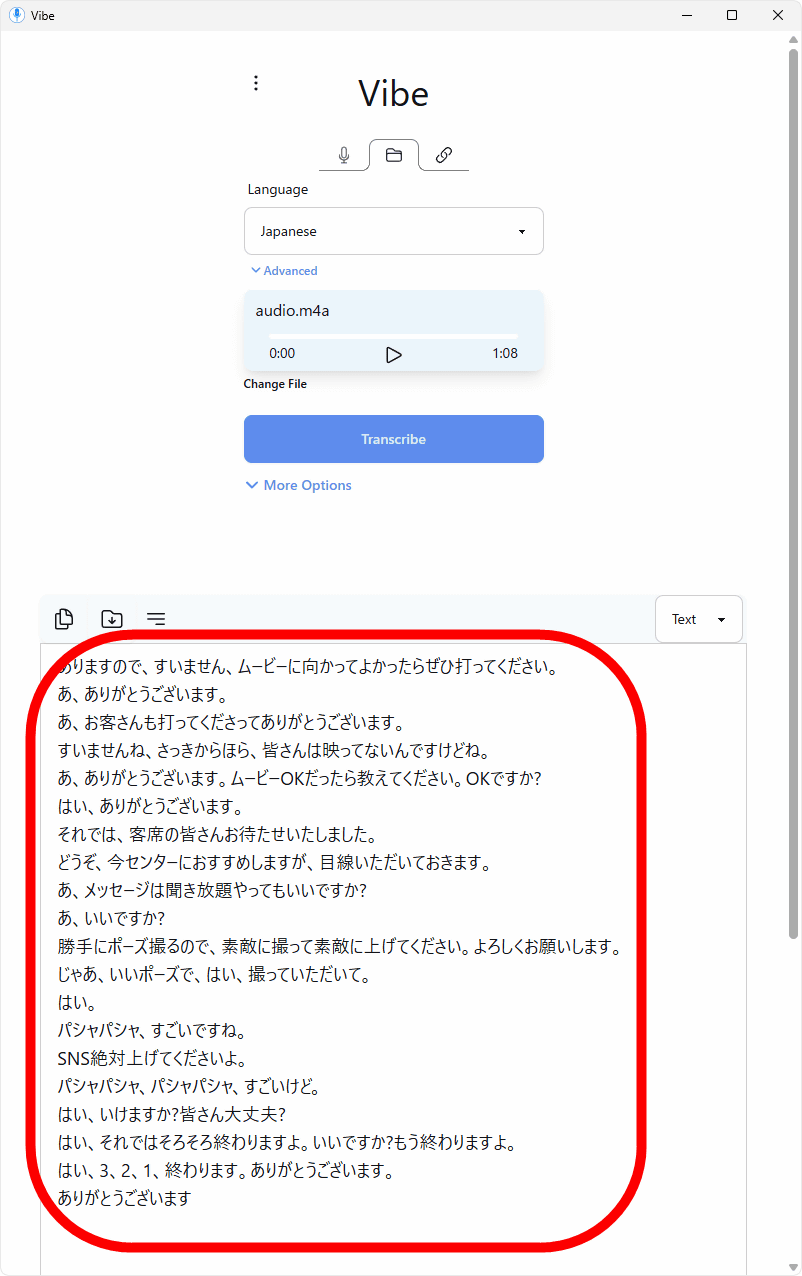
The audio files were automatically downloaded and transcribed by yt-dlp.
Related Posts: