AMD releases image generation AI 'Nitro-T,' which can be trained from scratch in less than a day using 32 Instinct MI300X processors

Semiconductor giant
Nitro-T: Training a Text-to-Image Diffusion Model from Scratch in 1 Day — ROCm Blogs
https://rocm.blogs.amd.com/artificial-intelligence/nitro-t-diffusion/README.html
AMD released Nitro-1 , a diffusion model focused on fast inference, in November 2024. Since Nitro-1, AMD has continued to research 'how to train image generation AI that generates images from text from scratch in a resource-efficient manner.'
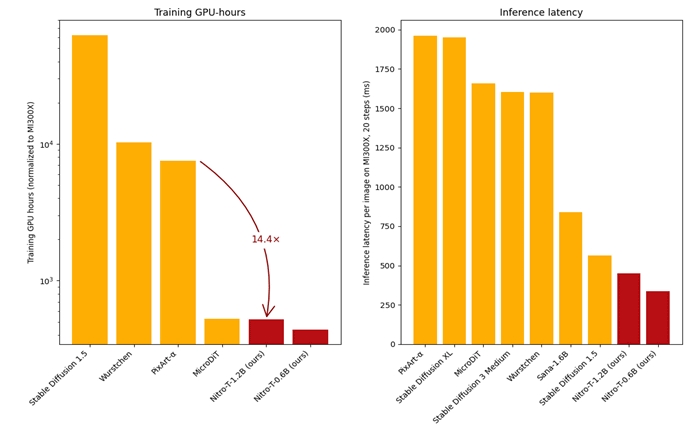
By promoting this 'improvement of training efficiency,' AMD finally succeeded in shortening training time to less than one day with 32 Instinct MI300X on Nitro-T. This makes it possible to reduce training costs to about one-fourteenth compared to the open source DiT model PixArt-α . AMD explains that Nitro-T's high training efficiency was achieved by 'combining multiple cutting-edge techniques, including smart architectural selection and system optimization.'
Nitro-T comes in two variants: a 600 million parameter DiT model optimized for 512-pixel image generation, and a 1.2 billion parameter Multimodal Diffusion Transformer (MMDiT) model optimized for 1024-pixel image generation. These models utilize Llama 3.2 1B to provide text conditioning, and training incorporates strategies and design choices that enable shorter patch sequence lengths, faster convergence, and optimized training throughput.
Below is a graph comparing the 'time it takes to train an image generation AI' (vertical axis) on the left and the 'inference latency (the delay time it takes to generate output)' (vertical axis) on the right. Compared to competing image generation AIs, Nitro-T (red) has very high training efficiency and overwhelmingly short inference latency.
One of the main computational bottlenecks in Transformer-based architectures is the self-
The Diffusion Transformer operates on tokens generated from image patches. Due to the inherent spatial redundancy present in images, we can reduce the length of token sequences by randomly dropping or masking tokens. However, simple token dropping can significantly degrade model performance by discarding important information needed to train higher-level structures. To solve this problem, we adopt the lazy masking strategy introduced in MicroDiT .
Instead of applying a token mask up front, our technique introduces a lightweight intermediate module called patch-mixer, which consists of several Transformer blocks. The key idea is that by delaying the masking operation until after the patch-mixer stage, we allow the model to first aggregate and mix information from the whole image, so that even if a subset of tokens are dropped, the remaining tokens still encode a global view of the input, preserving important context and structural signals.
Below is a sample of the image actually output by Nitro-T.
Image output by Nitro-T-1.2B

Image output with Nitro-T-0.6B

AMD shared its experience in training Nitro-T, a set of diffusion models that output images from trained text using a resource-efficient approach, and successfully achieved competitive performance while significantly reducing training time. By leveraging innovative techniques such as delayed patch masking, deep compression autoencoder, and expression alignment, as well as the latest ROCm software stack on the Instinct MI300X, we demonstrated that these models can be trained from scratch in less than a day. Ultimately, these advances enable researchers to iterate on ideas faster, lowering the barrier for independent developers and small teams to train or fine-tune models that exactly fit their needs and constraints. By publishing the full training code and model weights, we hope that our research will encourage experimentation, democratize access to generative AI tools, and help advance further research in this field. '
The model data for Nitro-T-1.2B and Nitro-T-0.6B are distributed by Hugging Face.
amd/Nitro-T-1.2B · Hugging Face
https://huggingface.co/amd/Nitro-T-1.2B
amd/Nitro-T-0.6B · Hugging Face
https://huggingface.co/amd/Nitro-T-0.6B
Related Posts:








in Software, Posted by logu_ii