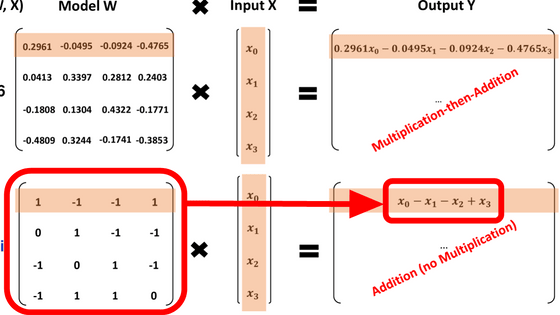
Introducing 'Punica,' a low-cost and efficient way to fine-tune large language models using LoRA.

Low Rank Adapation (LoRA) is a model for performing additional learning on AI with minimal computational effort. A research team from the University of Washington and Duke University has released ' Punica ,' a system that uses LoRA to perform fine-tuning on large-scale pre-trained language models at low cost and efficiently.
GitHub - punica-ai/punica: Serving multiple LoRA finetuned LLM as one
[2310.18547] Punica: Multi-Tenant LoRA Serving
https://arxiv.org/abs/2310.18547
When companies or developers want to prepare large-scale language models suitable for specific tasks, they need to fine-tune pre-trained large-scale language models. However, large-scale language models have billions of parameters, and directly fine-tuning all of the parameters requires enormous computational costs.
Punica includes a CUDA kernel design that enables batch processing of various LoRA models, allowing the company to maintain only one copy of a large, pre-trained base language model when processing multiple different LoRA models, significantly improving GPU cost-performance in both memory and compute.
While large pre-trained language models consume hundreds of gigabytes of storage, LoRA fine-tuned models only add a few gigabytes of storage and memory overhead. Punica allows you to run multiple LoRA fine-tuned models for the cost of running one.
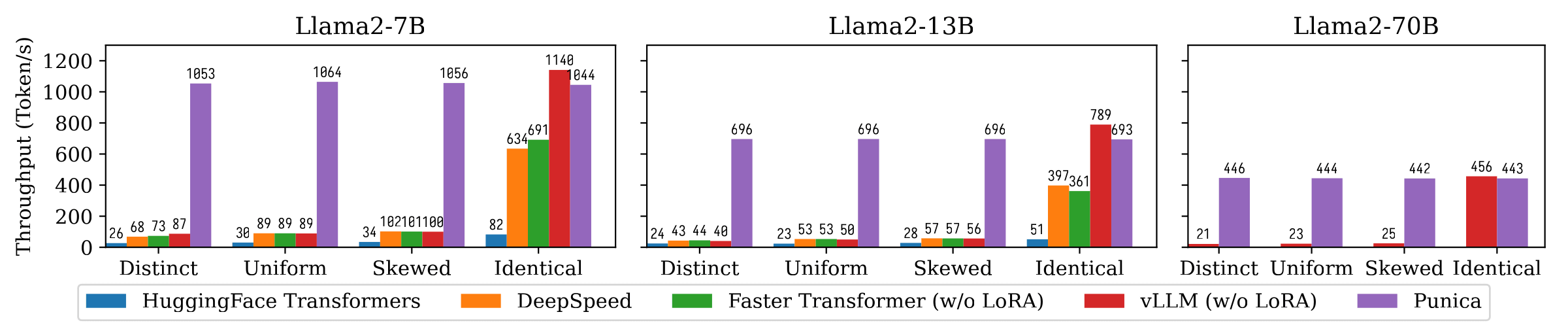
Below is a bar graph comparing the text generation throughput of Meta's large-scale language model, Llama2, with the 7B, 13B, and 70B models, using HuggingFace Transformers (blue), Microsoft DeepSpeed ( orange), NVIDIA Faster Transformer (green), vLLM (red), and Punica (purple). The research team states that Punica achieves 12 times the throughput of the other systems.
Punica is not the only research team that is applying LoRA to large-scale language models. On November 6, 2023, a paper on 'S-LoRA,' which uses LoRA to fine-tune large-scale language models on GPUs at low cost and efficiently, similar to Punica, was published on arXiv, a repository of unpeer-reviewed papers.
[2311.03285] S-LoRA: Serving Thousands of Concurrent LoRA Adapters
https://arxiv.org/abs/2311.03285
It has been reported that Google has already predicted the arrival of LoRA, a technology that will enable the efficient and low-cost handling of large-scale language models. In an internal document, Google pointed out that the arrival of LoRA would improve the performance of large-scale open-source language models, and that it might even be possible for its own AI models to be defeated by open-source models.
Leaked internal Google AI documents state that 'open source is a threat,' 'Meta is the winner,' and 'OpenAI is not important' - GIGAZINE

Related Posts: