




画像生成AIの潜在表現を高解像度画像へ直接変換する新技術「PiD」をNVIDIAが開発

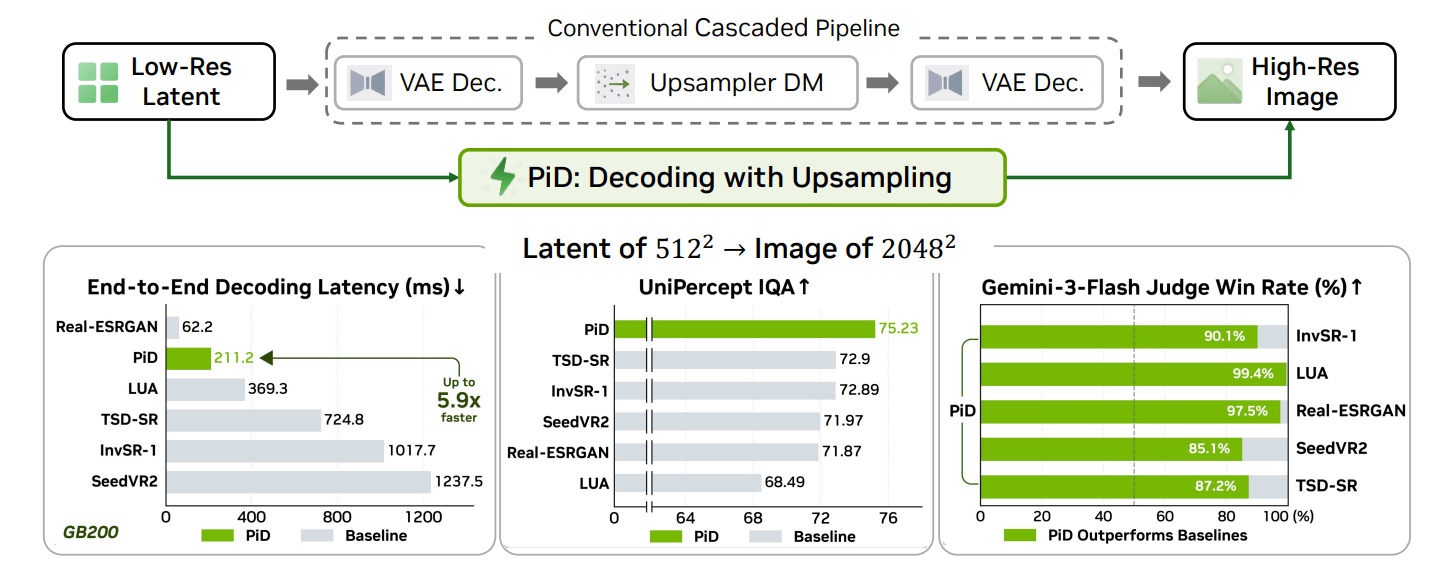
NVIDIAの研究チームが、ベクトル的な潜在表現を高解像度画像へ直接変換する「PiD(Pixel diffusion Decoder)」を発表しました。PiDは、低解像度でデコードしてから超解像する従来のカスケード処理を置き換え、低遅延と高い視覚品質の両立を目指す技術です。
PiD: Fast and High-Resolution Latent Decoding with Pixel Diffusion
https://research.nvidia.com/labs/sil/projects/pid/
[2605.23902] PiD: Fast and High-Resolution Latent Decoding with Pixel Diffusion
https://arxiv.org/abs/2605.23902
現行の画像生成AIは「拡散モデル」というアルゴリズムが主流です。拡散モデルで画像を生成する基本的な仕組みについては、以下の記事を読むとよくわかります。
画像生成AI「Stable Diffusion」がどのような仕組みでテキストから画像を生成するのかを詳しく図解 - GIGAZINE

高解像度のテキスト画像生成はコンパクトな「潜在空間」、すなわちデータの特徴を数学的にぎゅっと圧縮した数値空間で生成を行い、その後にデコーダーで高解像度な画像へ変換する方式が広く使われています。一方で従来のデコーダーはエンコーダーの出力を復元することに最適化されており、細部を新たに合成する能力やメガピクセル級での効率に課題がありました。
PiDは潜在デコードを条件付きピクセル拡散として再定義し、デコードとアップサンプリングを1つの生成モジュールに統合します。
潜在表現が全体の構造や意味を与え、ピクセル拡散モデルが高解像度の細部を直接合成する仕組みで、PiDはPixelDiTを基盤とするピクセル空間の拡散モデルに軽量なControlNet風アダプターを追加します。
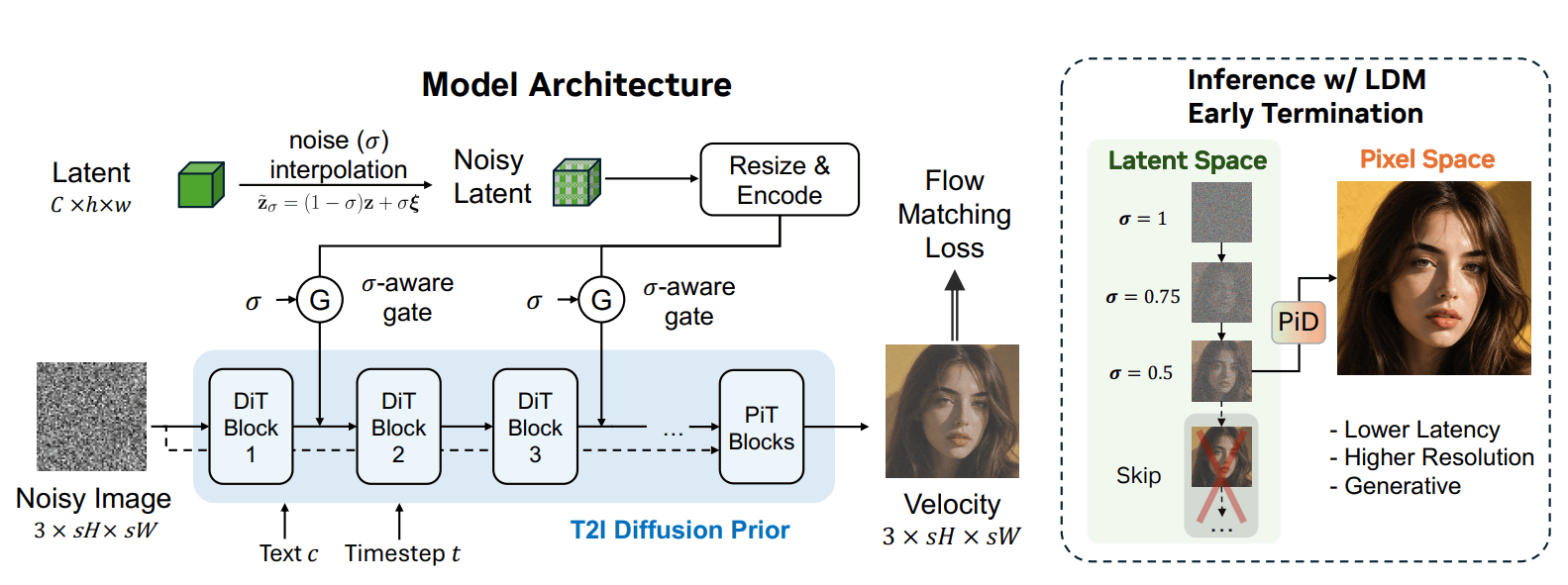
このControlNet風アダプターはノイズを含む潜在表現をモデルに注入し、シグマ対応ゲートによって、潜在表現をどの程度信頼するかをノイズ量に応じて調整します。この方式により、PiDは4倍または8倍にアップスケールした画像を低遅延で生成できるとのこと。

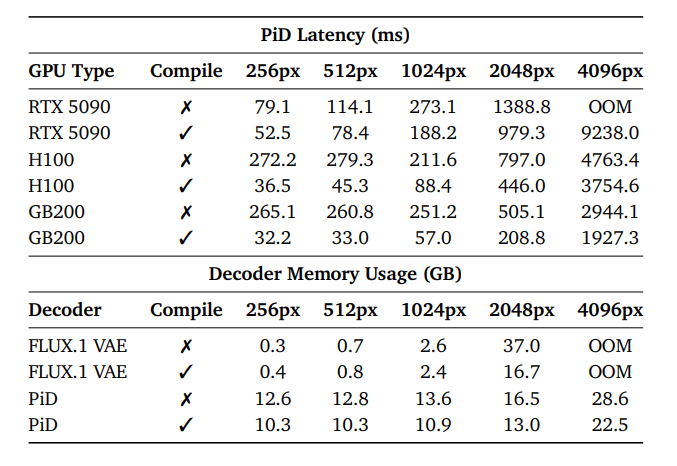
NVIDIAの研究チームは512x512画像に対応する潜在表現を2048x2048ピクセルへ変換する処理を、コンシューマー向けRTX 5090で1秒未満、ピークメモリ13GBで実行できたと報告しています。また、GB200 GPUでは、同じ処理を最短210msで実行できたそうで、拡散ベースの超解像カスケードパイプラインと比べて約6倍高速で、視覚的な忠実度も高いとNVIDIAの研究チームは評価しています。
さらにPiDは完全にノイズ除去された潜在表現だけでなく、途中段階の潜在表現も扱えるとのこと。そのため、ベースとなる潜在拡散モデルの推論を途中で打ち切り、残りをPiD側で高解像度画像へ変換することが可能になります。

加えて、DMD2による蒸留で推論を4ステップまで短縮しています。条件なし推論を別途走らせる必要も抑えられており、高解像度化の工程全体を簡素化する狙いがあります。
対応する潜在表現は従来のVAEに限られず、SigLIPやDINOv2のような意味表現を使うRAE系モデルにも適用でき、意味構造は保つ一方で低レベルの見た目が不足しやすい潜在表現に対して、生成的な細部補完を行います。
学習データにはMultiAspect-4K-1M、レンダリングされたPDFデータ、内部調達された高解像度画像が使われています。低品質なサンプルをQ-Alignで除外した結果、260万枚の高品質画像を用いたとされています。
PiDの意義は画像生成の最後段にあるデコーダーを単なる復元器ではなく、生成能力を持つ高解像度化モジュールとして位置付け直した点にあります。潜在空間で効率よく全体構造を作り、ピクセル空間で細部を合成する設計は、高解像度画像生成の処理時間と品質の両面を改善するアプローチとして注目されています。
・関連記事
VAE不要で画像生成できるオープンモデル「SenseNova U1」が登場、Z-Imageより圧倒的に高速で品質も上々 - GIGAZIaNE
画像生成AIをPCで簡単に実行できる「ComfyUI」のインストール手順&最初の画像を生成するまでの手順まとめ - GIGAZINE
アニメ・イラストに強い画像生成AI「Anima」の正式版がついに登場、タグ・自然言語両対応でSDXLやIllustrious系モデルが動作するPCなら余裕でローカル実行可能 - GIGAZINE
画像生成AI「Stable Diffusion」が実はかなり優秀な画像圧縮を実現できることが判明 - GIGAZINE
FLUXのBlack Forest Labsが高効率&高精度で画像・動画・音声を生成するマルチモーダルAIの学習手法「Self-Flow」を発表 - GIGAZINE
画像生成AI「Stable Diffusion」を使いこなすために知っておくと理解が進む「どうやって絵を描いているのか」をわかりやすく図解 - GIGAZINE
Appleが1枚の画像からリアルな照明効果を持つ3Dオブジェクトを再現できるAIモデルを発表 - GIGAZINE
シンプルな原理とユニークな特性を持つ新しい生成AIモデル「DDN(Discrete Distribution Networks)」 - GIGAZINE
最大4096×4096の解像度の画像を数秒以内に自動生成できるAIモデル「Sana」をNVIDIAなどの研究チームがリリース - GIGAZINE
・関連コンテンツ




in AI, ソフトウェア, Posted by log1i_yk
You can read the machine translated English article NVIDIA has developed a new technology ca….