




Cohereがエージェントタスク向けに構築されたMoEマルチモーダルAI「Command A+」をリリース、自社環境に展開できる企業向けの高性能オープンソースモデル

Cohereが同社の言語モデル「Command」シリーズで最速かつ最も強力とうたう「Command A+」をオープンソースで公開しました。Command A+は、複雑な推論、マルチモーダル処理、多言語対応、AIエージェント的な業務に対応する企業向けモデルで、最小構成ではNVIDIA H100を2基、またはBlackwell世代のB200を1基使って動作します。
Introducing Command A+ | Cohere
https://cohere.com/blog/command-a-plus
CohereLabs/command-a-plus-05-2026-w4a4 · Hugging Face
https://huggingface.co/CohereLabs/command-a-plus-05-2026-w4a4
Command A+は、Cohereが企業向けAIワークスペース「North」を顧客に展開してきた1年間の経験を基に開発されたモデルです。Cohereはこのモデルについて、企業が自社環境内で実行、管理、適応できる「ソブリンAI」を実現するための基盤と位置付けています。
Command A+は、従来の「Command A」シリーズの機能を1つに統合したモデルでもあります。Command A Reasoningが推論に、Command A Visionがマルチモーダル処理に、Command A Translateが多言語処理に重点を置いていたのに対し、Command A+は推論、マルチモーダル、ツール使用、48言語対応を1モデルでまとめて扱います。

モデル名は「command-a-plus-05-2026」で、Apache 2.0ライセンスの下で開発されています。アーキテクチャは巨大なAIモデルの計算コストを抑えつつ、性能を飛躍的に高めるニューラルネットワーク「Sparse MoE」で、総パラメーター数は2180億。実際に各トークンで有効化されるアクティブパラメーターは250億となっています。入力コンテキスト長は128K、最大生成長は64Kで、入力はテキスト、画像、ツール使用に対応します。
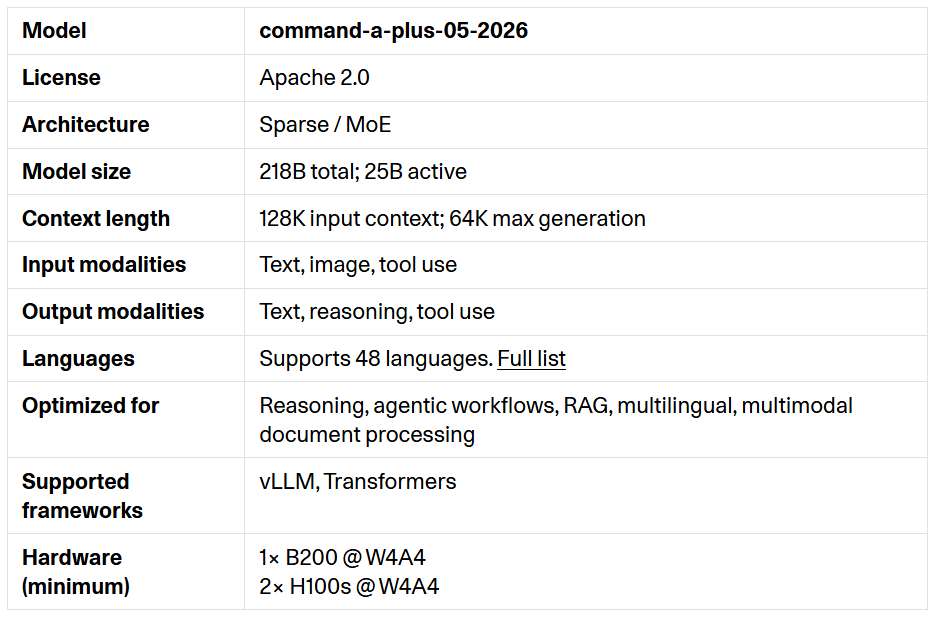
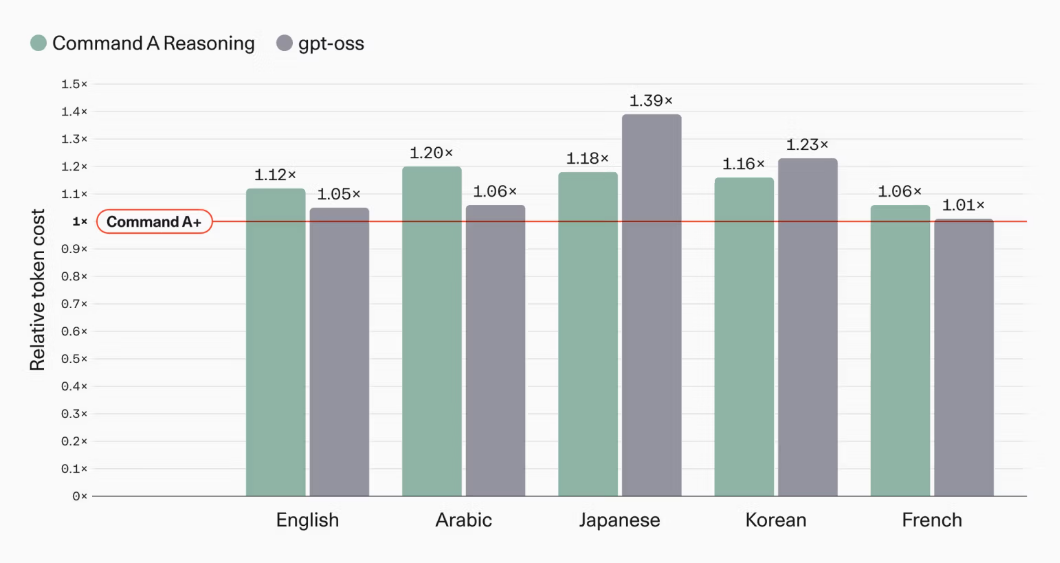
出力はテキスト、推論、ツール使用に対応し、多言語対応は、従来の23言語から48言語へ拡大。Command A+は新しいトークナイザーが採用されたことで同じ応答を生成するために必要なトークン数が減り、特にアラビア語で20%、韓国語で16%、日本語で18%のトークン効率改善が確認されています。
Command A+はCohereとCohere Labsが開発したモデルで、エージェント処理、多言語処理、重い推論タスク、画像入力を含む視覚情報処理に最適化されているとのこと。公開されているモデルはBF16、FP8、W4A4の各量子化版を含み、Hugging Face Spaceで試用することも可能です。
量子化ごとの最小GPU要件はBF16がB200×4基またはH100×8基、FP8がB200×2基またはH100×4基、W4A4がB200×1基またはH100×2基です。Cohereは3種類の量子化のベンチマーク品質差はごく小さいとし、速度、レイテンシ、必要ハードウェアの小ささから、多くの用途ではW4A4を推奨しています。
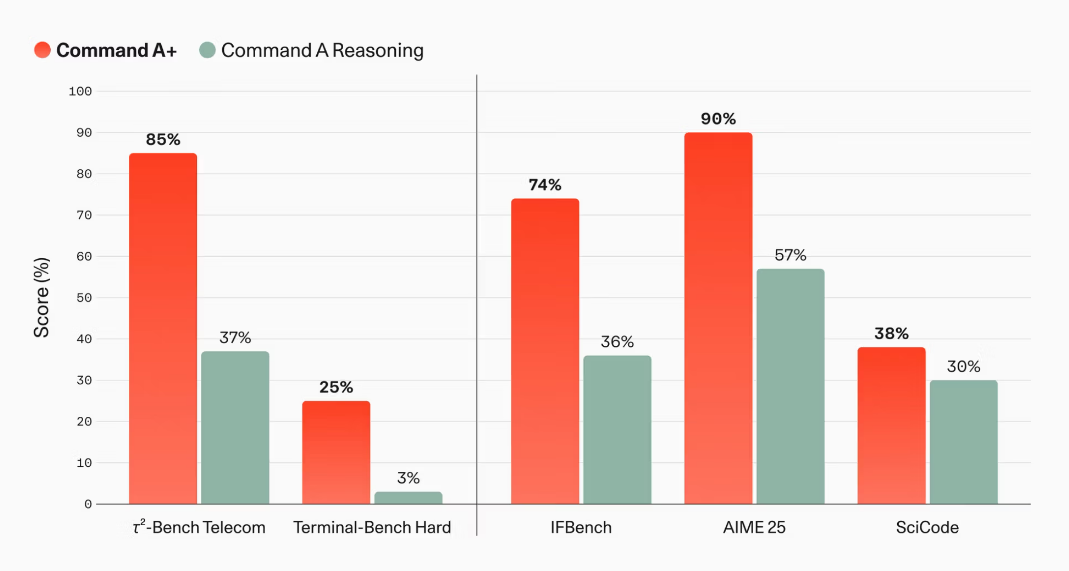
性能面では、Command A Reasoningと比べて大きな伸びが示されています。τ2-Bench Telecomは37%から85%、Terminal-Bench Hardは3%から25%に向上し、IFBenchは36%から74%、AIME 25は57%から90%、SciCodeは30%から38%となっています。
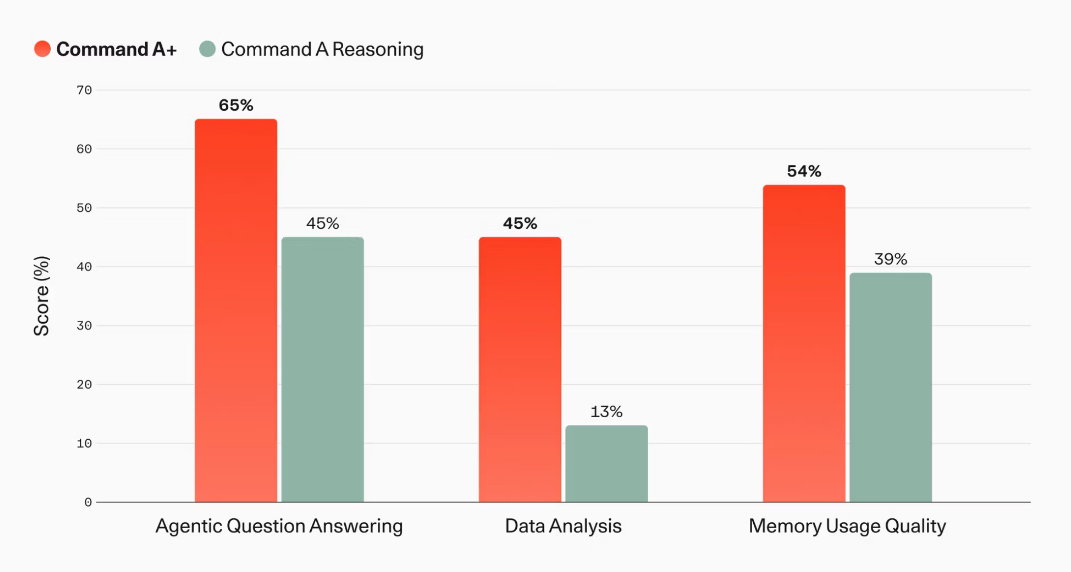
North向けの内部評価でも、Command A+は企業利用を想定した処理で改善を示しています。エージェント質疑応答(Agentic Question Answering)は45%から65%、データ解析(Data Analysis)は13%から45%、メモリを使ったエージェント処理性能(Memory Usage Quality)は39%から54%となり、クラウドファイルシステムやスプレッドシート、過去セッションのメモリを使うエージェント処理で性能が向上しています。
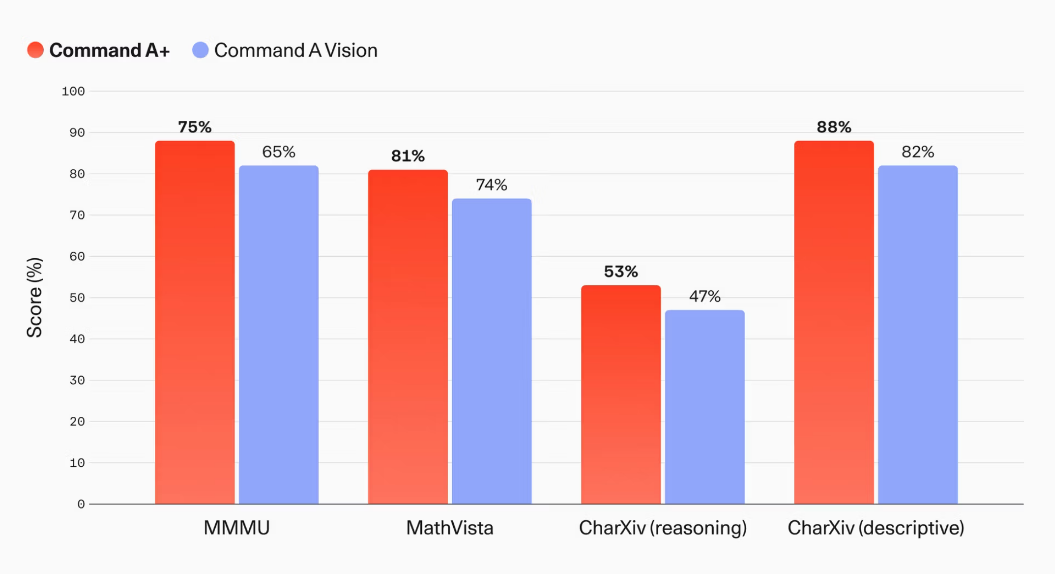
Command A+とCommand A Visionでマルチモーダル性能を比較した結果が以下。Command A+はMMMU Proで63%、MMMUで75.1%を記録しました。MathVistaは73.5%から80.6%、CharXiv reasoningは46.9%から52.7%に向上しており、CohereはCommand A+の文書理解タスクが全般的に改善したことを強調しています。
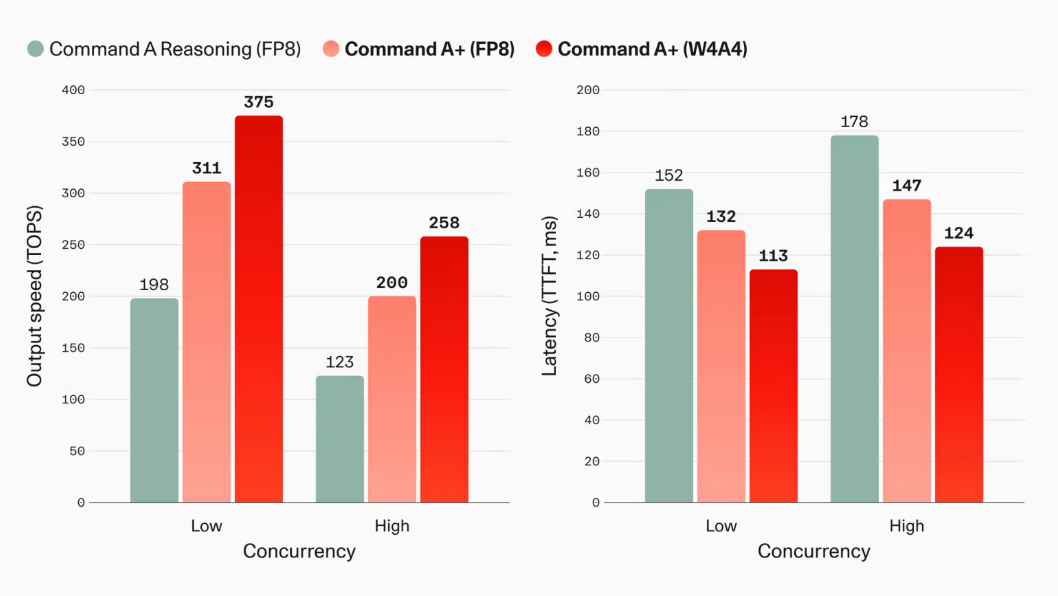
効率性もCommand A+の大きな特徴です。Cohereは、同じ量子化と同じ並列実行条件でCommand A Reasoningと比較した場合、出力トークン毎秒が最大63%向上し、最初のトークンが返るまでの時間であるTTFTが最大17%短縮されたとしています。
W4A4量子化では、さらに47%の速度向上と13%のレイテンシ低減が得られるとされています。加えて、MoEアーキテクチャに合わせて最適化した投機的デコーディングにより、テキスト入力とマルチモーダル入力の両方で1.5倍から1.6倍の推論高速化を実現しています。
Cohereによれば、W4A4量子化版はMoEの専門家部分だけに4ビットの重みと活性化を使うNVFP4 W4A4量子化を適用し、QKVや出力射影、KVキャッシュ、アテンション計算はフル精度のまま維持しているとのこと。さらに、量子化後の品質低下を抑えるため、フル精度モデルの出力分布に量子化モデルを近づけるQuantization Aware Distillationを使っているそうです。
CohereはAI事業で提携している富士通のシステムプラットフォーム担当CTOであるVivek Mahajan氏のコメントも紹介。Mahajan氏は「Command A+のMoEアーキテクチャとエージェント性能が、富士通とCohereが共同開発した企業向けLLM『Takane』や、富士通のAIプラットフォーム『Fujitsu Kozuchi Enterprise AI Factory』を通じたソブリンAIソリューションの提供方針に合致している」と述べています。
Command A+はHugging Faceでモデルパラメーターを入手できるほか、Model Vaultで管理された推論環境にデプロイすることもできます。無料で試す場合はHugging Face SpaceやCohere APIキーを使う方法も用意されており、vLLMとTransformersがサポートされています。ただし、W4A4版をvLLMで動かす場合はvLLM 0.21.0以上が必要で、正確な応答パースにはCohereのmelodyライブラリも必要です。
・関連記事
GPT-4oやDeepSeek-V3超えの性能をGPU2個で実現する生成AIモデル「Command A」が登場、Transformerの発明者が設立したAI企業「Cohere」が開発 - GIGAZINE
日本語にも対応したオープンソースの文字起こし専用音声認識モデル「Transcribe」をCohereが発表 - GIGAZINE
エンタープライズAI開発企業のCohereが多言語AI「Tiny Aya」を発表 - GIGAZINE
AlibabaがAIエージェント向け新モデル「Qwen3.7-Max」を発表、35時間の自律作業と1000回超のツール呼び出しに対応 - GIGAZINE
Gemini 3.5 Flashの総パラメータ数は2500億~3000億か、Hacker NewsユーザーがTPU性能から逆算 - GIGAZINE
GoogleがAIエージェント「Gemini Spark」発表、Google Cloud上の仮想マシンを使用して24時間365日バックグラウンドで動作 - GIGAZINE
Googleが処理しているトークン量は月間3200兆、1年間で7倍に増大 - GIGAZINE
・関連コンテンツ








in AI, Posted by log1i_yk
You can read the machine translated English article Cohere releases 'Command A+', a multimod….