




AMD製AIチップで開発された拡散言語モデル「ZAYA1-8B-Diffusion-Preview」が登場、自己回帰モデルを拡散モデルに変換

AIスタートアップのZyphraがAMD製のAIチップでトレーニングされた初の拡散言語モデルである「ZAYA1-8B-Diffusion-Preview」を発表しました。
ZAYA1-8B-Diffusion-Preview: Efficient Parallel Decoding on AMD
https://www.zyphra.com/post/zaya1-8b-diffusion-preview
We present ZAYA1-8B-Diffusion-Preview, the first diffusion language model trained on @AMD.
— Zyphra (@ZyphraAI) May 14, 2026
Autoregressive LLMs generate one token at a time; diffusion generates a block in parallel, speeding up inference.
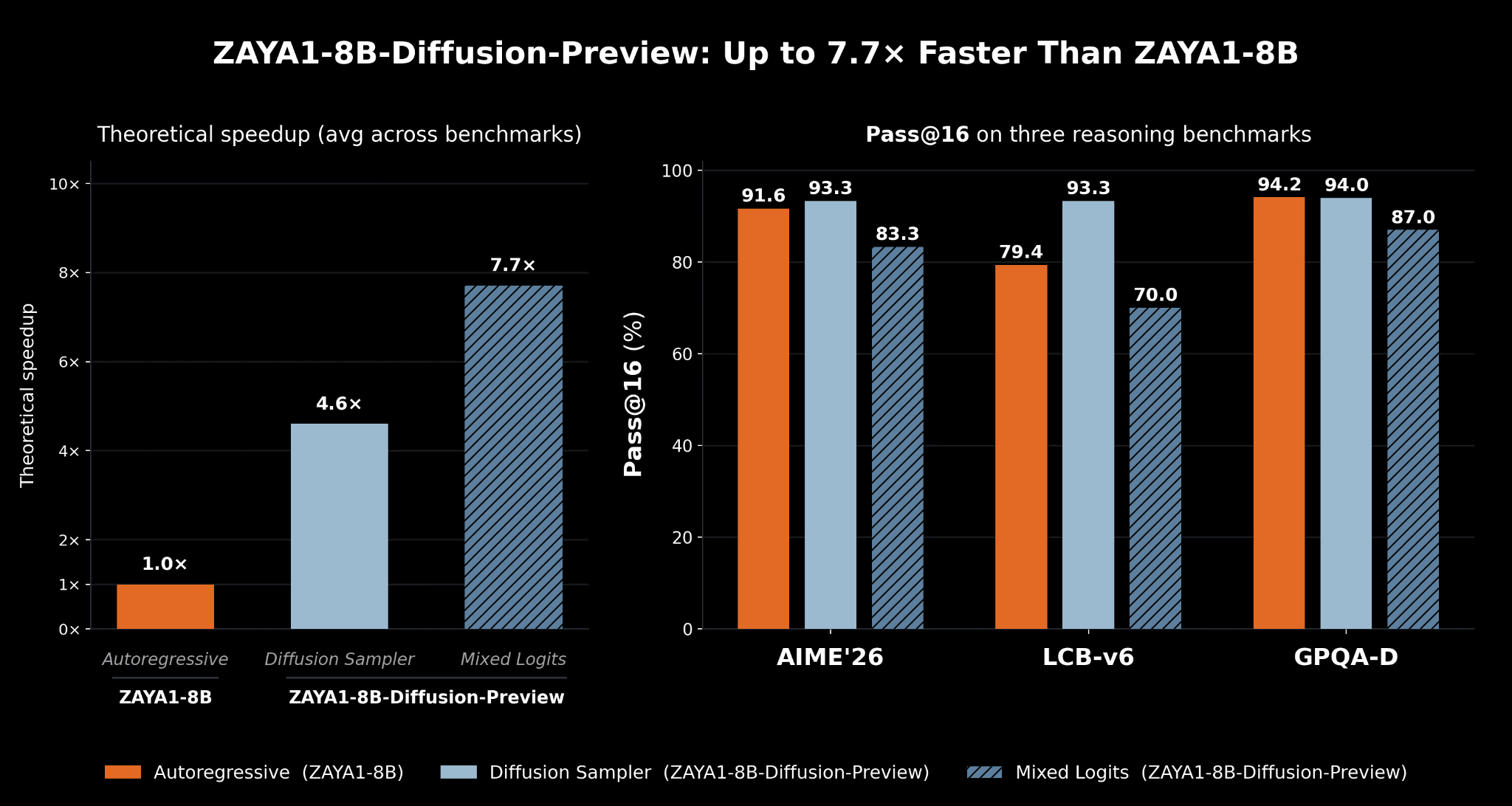
We show a 4.6-7.7x decoding speedup with minimal quality degradation 🧵 pic.twitter.com/xMXp4sFYkb
Zyphraが拡散言語モデルに関する初期の研究成果プレビューである「ZAYA1-8B-Diffusion-Preview」を発表しました。ZyphraはAMDのGPUインフラを用いたAI開発に取り組んでいる企業で、2026年5月6日には推論言語モデルの「ZAYA1-8B」を発表していました。このZAYA1-8Bは、既存の言語モデルのほとんどと同じように自己回帰モデルです。
約7億パラメータで大規模AIに迫る「ZAYA1-8B」が登場、AMD環境でトレーニングされ数学・コード推論で大規模モデル級の性能を実現 - GIGAZINE

そんな自己回帰モデルのZAYA1-8Bを、評価性能を維持しつつ離散拡散モデルに変換したのが「ZAYA1-8B-Diffusion-Preview」です。「ZAYA1.8B-Diffusion-Preview」は、自己回帰モデル型の大規模言語モデル(LLM)から変換された初のMoE拡散モデルであり、AMDのGPUでトレーニングされた初の拡散言語モデルでもあります。
自己回帰モデルはトークンを順番にひとつずつデコードします。自己回帰モデルは各トークンにおいて、「過去のすべてのトークンをさかのぼって確認し、過去の計算結果(KVキャッシュ)を使用して新しいトークンを生成する」というアテンションメカニズムを採用。これにより、自己回帰モデルのデコードでは、メモリ帯域幅の制約を受けることになるという問題があります。
これに対して、拡散モデルは「メモリ帯域幅の制約」というボトルネックを解消することが可能です。拡散モデルでは、「N個のトークンに対して複数のドラフトを同時に生成する」というプロセスを複数回繰り返します。拡散モデルは、同じKVキャッシュを使用して単一シーケンスの一部としてN個のトークンを一度に生成できるため、操作全体がメモリ帯域幅ではなく計算量に依存するようになり、GPUの利用率が最大化され、自己回帰モデルの推論に比べて劇的に高速化することが可能です。
拡散モデルをゼロからトレーニングすることは難しいため、Zyphraは「既存の学習済みの自己回帰モデルをベースに拡散モデルに変換する」という手法を提案。この手法で誕生したのが「ZAYA1.8B-Diffusion-Preview」です。
拡散モデルの「ZAYA1.8B-Diffusion-Preview」と、ベースとなった自己回帰モデルのZAYA1-8Bの、自己回帰デコーディングにおける理論的高速化を比較したのが以下の右のグラフ。「ZAYA1.8B-Diffusion-Preview」は標準拡散サンプラーでは4.6倍、混合ロジットサンプラーでは7.7倍の高速化を実現しています。左のグラフはLLMのコード生成能力や数学的推論能力を評価するPass@16を複数のベンチマークで評価した結果をまとめたもの。標準拡散サンプラーでは拡散変換による体系的な評価の劣化は見られません。混合ロジットサンプラーについては「(ZAYA1-8Bと比較すると)多少の劣化が見られるものの、大幅な速度向上が見込まれるため、実行時に選択できる品質とパフォーマンスのトレードオフが生じます」とZyphraは説明しました。
・関連記事
約7億パラメータで大規模AIに迫る「ZAYA1-8B」が登場、AMD環境でトレーニングされ数学・コード推論で大規模モデル級の性能を実現 - GIGAZINE
Inceptionが世界最速の拡散モデルベース推論LLM「Mercury 2」を発表 - GIGAZINE
日本語対応&超高速コード生成も可能な拡散大規模言語モデル(dLLM)「Mercury」が登場 - GIGAZINE
Googleの拡散型言語モデル「Gemini Diffusion」はどれくらい爆速なのか? - GIGAZINE
Stable Diffusionなどの画像生成AIに用いられる拡散モデルは「進化的アルゴリズム」だという主張 - GIGAZINE
生成AIに使われる拡散処理を超爆速わずか2ステップで完了できるアプローチ「sCM」をOpenAIが発表 - GIGAZINE
・関連コンテンツ







in AI, Posted by logu_ii
You can read the machine translated English article A new spreading language model, 'ZAYA1-8….