




日本語にも対応したオープンソースの文字起こし専用音声認識モデル「Transcribe」をCohereが発表

AI企業のCohereがオープンソースの音声認識(ASR)モデル「Transcribe」を2026年3月26日に発表しました。このモデルは英語、日本語、中国語、韓国語、ベトナム語、フランス語、ドイツ語、イタリア語、スペイン語、ポルトガル語、ギリシャ語、オランダ語、ポーランド語、アラビア語に対応しており、Hugging Faceからダウンロードできるほか、CohereのAPI経由でも試用できるようになっています。
Cohere Transcribe: state-of-the-art speech recognition
https://cohere.com/blog/transcribe
Transcribe | Cohere
https://cohere.com/transcribe
CohereLabs/cohere-transcribe-03-2026 · Hugging Face
https://huggingface.co/CohereLabs/cohere-transcribe-03-2026
Transcribeは音声をテキストに変換することに特化したオープンソースのASRモデルで、会議の文字起こし、音声分析、リアルタイムのカスタマーサポートといった企業向け用途を想定しています。Cohereはこれを企業向け音声インテリジェンスの基盤として位置付けています。
Transcribeの大きな特徴は、研究用の実験モデルではなく、実運用を前提にしながら高い文字起こし精度を目指している点です。Cohereによると、Hugging FaceのOpen ASR Leaderboardでは平均単語誤り率(WER)5.42%を記録して首位に立っており、OpenAIのWhisper Large v3の7.44%、ElevenLabs Scribe v2の5.83%、Qwen3-ASR-1.7Bの5.76%を下回ったとのこと。こうした結果は、複数話者が登場する会話や会議室のような音響環境、多様なアクセントを含む実環境寄りの条件でも高い性能を示したものだと説明されています。
Open ASR Leaderboard - a Hugging Face Space by hf-audio
https://huggingface.co/spaces/hf-audio/open_asr_leaderboard
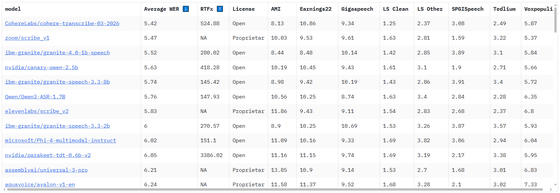
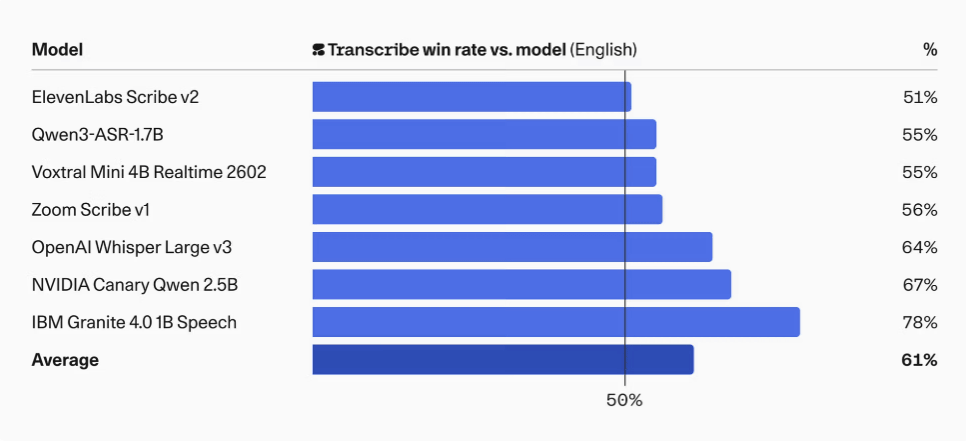
さらにCohereは、人による比較評価でもTranscribeが高く評価されたと説明しており、評価者は文字起こし結果について、意味をきちんと保っているか、ハルシネーションがないか、固有名詞を正しく書き取れているか、逐語的で適切な整形になっているかといった観点から比較しています。その結果、英語では平均61%、Whisper Large v3に対しては64%の勝率を示しました。
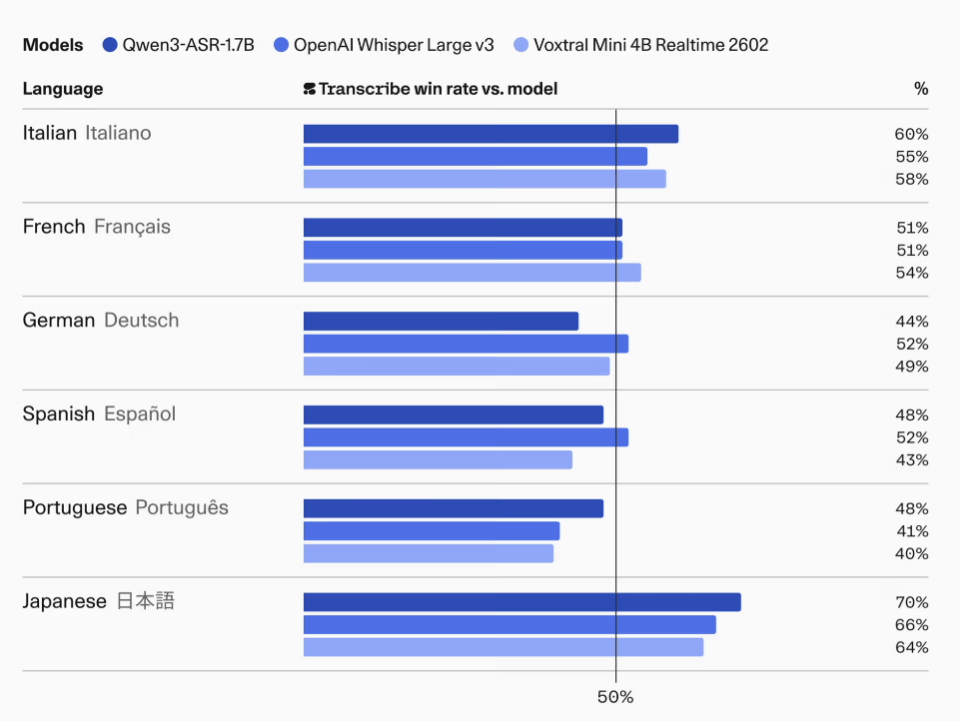
また、日本語ではQwen3-ASR-1.7Bに対して70%、Whisper Large v3に対して66%の勝率だったとされています。
モデルの規模は20億パラメーターで、構造にはConformerベースのエンコーダー・デコーダー方式を採用しています。入力された音声波形はまずメルスペクトログラムに変換され、その後、大部分のパラメーターを担うConformerエンコーダーが音響表現を抽出し、軽量なTransformerデコーダーがテキストトークンを生成します。学習はスクラッチから行われており、英語、日本語、中国語、韓国語、ベトナム語、ドイツ語、フランス語、イタリア語、スペイン語、ポルトガル語、ギリシャ語、オランダ語、ポーランド語、アラビア語の14言語に対応しています。
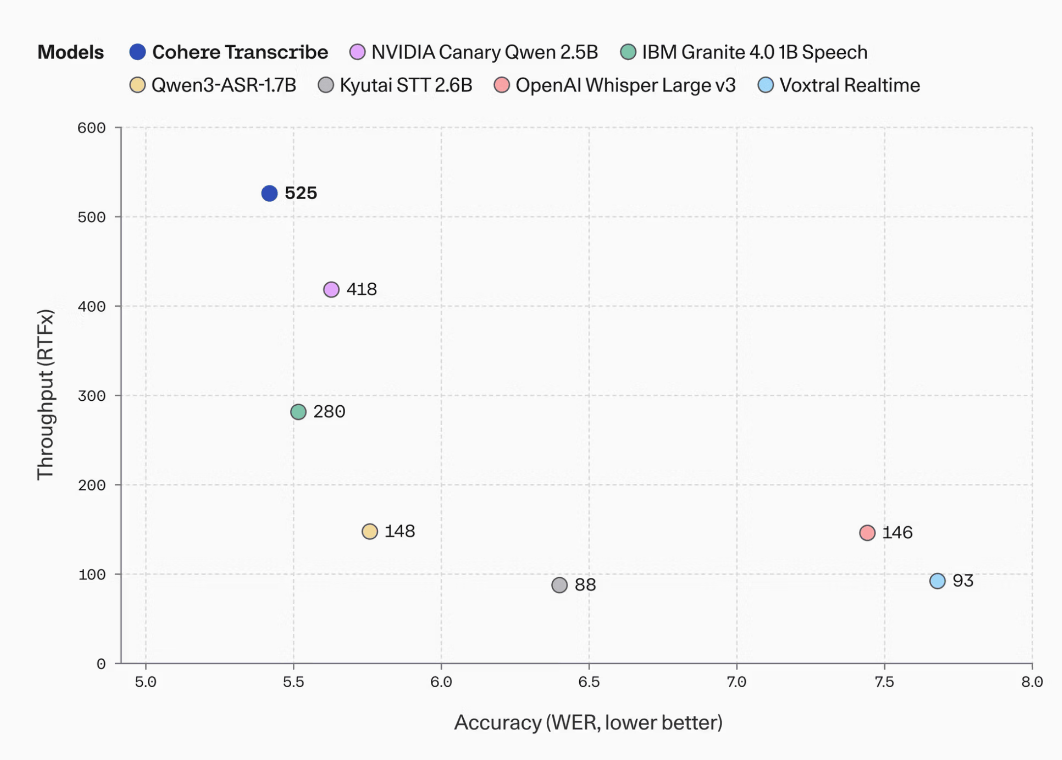
処理速度も重視されており、Cohereは、パラメーターサイズが1B(10億)超のASRモデル群の中で、精度とスループットの両立という点で優れた位置にあると説明しています。以下はパラメータサイズ1Bを超える主要なASRモデルにおけるスループット(RTFx)と誤答率(WER)を示したもの。CohereのTranscribe(青色)は525となっており、これは入力音声を実時間の525倍の速度で処理できることを意味します。同時に、TranscribeはWERが他モデルの中で最も低いことから、文字起こしの精度が高いことがわかります。
Transcribeはオープンウェイトで提供されるため、自前の環境でインフラを制御しながら運用しやすいことも強みです。Cohereは、実用的なGPUやローカル環境、エッジ環境でも扱いやすい推論負荷だと説明しており、機密性の高い音声データを外部に出さずに処理したいケースにも向いています。
また、インフラ管理なしに低遅延な推論環境を使いたい場合に向けては、同社のマネージド推論基盤であるModel Vaultでも提供するとしています。
一方で、Transcribeは自動言語検出には対応しておらず、14言語のうち1つをあらかじめ指定して使う前提。コードスイッチされた音声では性能が安定しないことがあるほか、タイムスタンプ付与や話者分離(ダイアライゼーション)の機能も備えていません。また、無音や非音声にも反応して文字起こししようとする傾向があるため、実運用ではVAD(音声区間検出)やノイズゲートを前段に入れることが推奨されています。
Cohereは今後、Transcribeを同社のAIエージェントオーケストレーション基盤「North」とより深く統合していく方針も示しています。記事作成時点では高精度な文字起こしモデルとして公開されていますが、将来的には企業が音声データを検索・分析・自動化に活用するためのより広いプラットフォームに発展させていく構想を描いています。
・関連記事
無料&広告なしで音声をテキストに変換できるアプリ「Notely Voice」レビュー、ネット接続不要でスマホのみでWhisperを実行して長文メモを簡単に作れる - GIGAZINE
無料で日本語もサポートしリアルタイム音声アプリをWhisperより高精度で開発できるオープンソースAIツールキット「Moonshine Voice」 - GIGAZINE
無料で日本語・手書き・縦書きもテキスト化できる国立国会図書館のWindows・Mac・Linux向けOCRアプリ「NDLOCR-Lite」 - GIGAZINE
Mistral AIが文字起こしAI「Voxtral Mini Transcribe V2」と「Voxtral Realtime」を発表 - GIGAZINE
AirPodsのライブ翻訳は2025年末に日本語に対応予定、しかしEUでは使えない - GIGAZINE
・関連コンテンツ






in AI, Posted by log1i_yk
You can read the machine translated English article Cohere has announced 'Transcribe,' an op….