




無料でSEOトラッキングができる「SerpBear」、オープンソースでセルフホスト可

ウェブサイトを運営するにあたり、サイトの課題を明確にし改善を検討する上でSEOトラッキングは不可欠なプロセスと言えます。SEOトラッキングはニーズの高さから様々なサービスやツールが提供されていますが、無料で「SERP(Search Engine Result Page)」、つまり検索結果ページ対策を使用できる上にオープンソースでありセルフホストも可能なツールが「SerpBear」です。2024年2月にバージョン1.0.0が公開されて以降着実に更新を重ね、記事作成時点でちょうどバージョン3.0.0がリリースされています。
towfiqi/serpbear: Search Engine Position Rank Tracking App
https://github.com/towfiqi/serpbear
◆特徴
公式GitHubによるとSerpBearの特徴は以下のとおりです。
・無制限キーワード:無制限のドメインとキーワードを追加してSERPを追跡できる
・メール通知機能:キーワード順位変動を定期的にメールで通知する
・SERP API:マーケティングやデータレポートツールで利用可能なAPIを公開している
・キーワードリサーチ:Google Adsテストアカウントと連携して追跡対象サイトのコンテンツを調査しキーワード候補を自動生成できる
・Google Search Console連携:各キーワードの実際の訪問数・インプレッション数などを取得できる
・モバイルアプリ:PWAアプリをモバイル端末に追加し、より優れたモバイル体験を実現する
・運用コストゼロ:mogenius.comまたはFly.ioにて無料でアプリを運用できる
◆導入
セルフホストする方法としてDockerを利用する手順が提供されています。まずはGitHubからリポジトリをローカルにクローンします。
git clone https://github.com/towfiqi/serpbear.git
cd serpbear
クローンしたディレクトリの直下に「.env.example」というファイルがあるのでファイルコピーして「.env」ファイルを作成し、ファイルを開いて「USER=~」を「USER_NAME=~」に変更しておいてください。ログイン情報などを含むため外部に公開するならば内容を変更する必要がありますが、ローカルPC上で試しに起動してみる程度であれば内容はそのままでOKです。
USER_NAME=admin
PASSWORD=0123456789
SECRET=4715aed3216f7b0a38e6b534a958362654e96d10fbc04700770d572af3dce43625dd
APIKEY=5saedXklbslhnapihe2pihp3pih4fdnakhjwq5
SESSION_DURATION=24
NEXT_PUBLIC_APP_URL=http://localhost:3000
加えてdocker-compose.yamlを作成します。リポジトリには含まれていないファイルなので以下をコピーして作成してください。
services:
app:
image: towfiqi/serpbear:latest
restart: unless-stopped
ports:
- "${PORT:-3000}:3000"
environment:
- USER_NAME=${USER_NAME:-admin}
- PASSWORD=${PASSWORD}
- SECRET=${SECRET}
- APIKEY=${APIKEY}
- SESSION_DURATION=${SESSION_DURATION:-24}
- NEXT_PUBLIC_APP_URL=${NEXT_PUBLIC_APP_URL:-http://localhost:3000}
# Optional: Google Search Console integration
- SEARCH_CONSOLE_CLIENT_EMAIL=${SEARCH_CONSOLE_CLIENT_EMAIL:-}
- SEARCH_CONSOLE_PRIVATE_KEY=${SEARCH_CONSOLE_PRIVATE_KEY:-}
volumes:
- serpbear_data:/app/data
healthcheck:
test: ["CMD-SHELL", "wget -qO- http://localhost:3000 || exit 1"]
interval: 30s
timeout: 10s
retries: 3
start_period: 15s
volumes:
serpbear_data:
最後に以下のコマンドを実行するとコンテナのビルドが始まり、完了するとサービスが起動します。
docker-compose up -d
サービスの起動後にローカルPCであればブラウザにて「http://localhost:3000」にアクセスするとログイン画面が表示されるので「.env」で設定したユーザー名とパスワードでログインしてください。
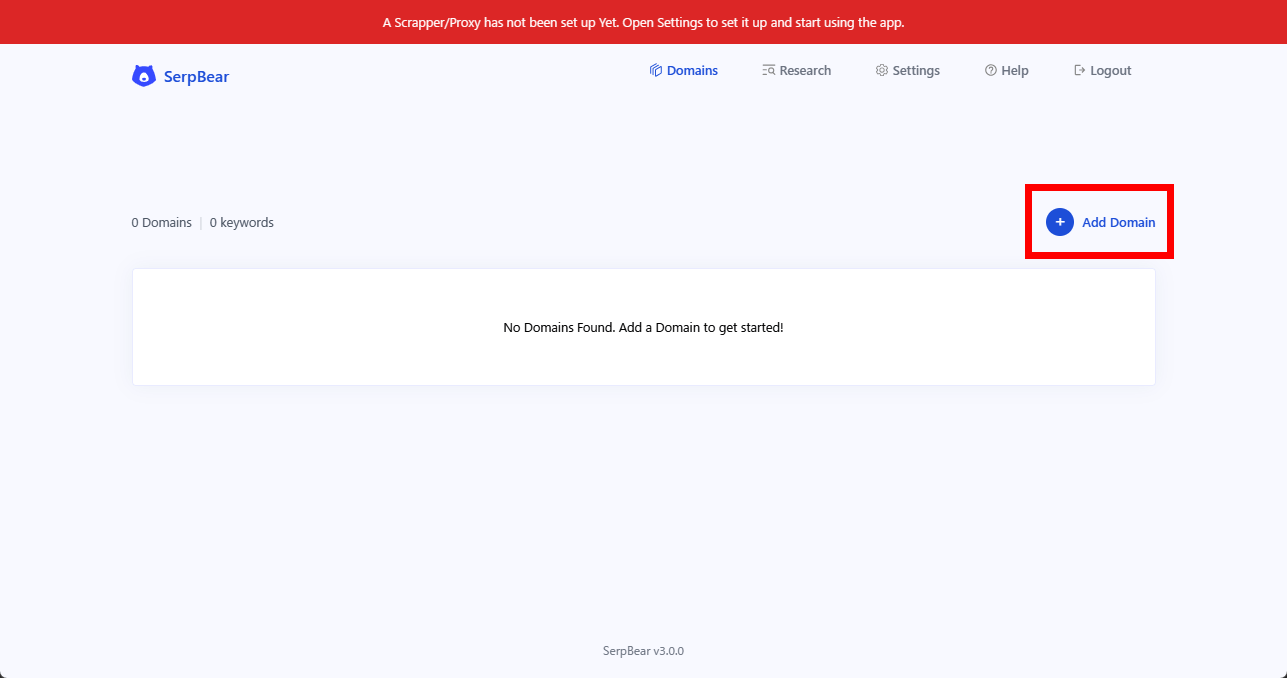
◆ドメインの登録
ログイン後、「Add Domains」のリンクをクリックし最初のドメインを登録します。
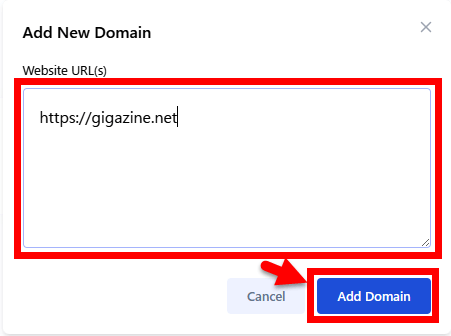
「Add New Domain」ポップアップが表示されるので「Website URL(s)」欄にドメインを入力し「Add Domain」をクリックします。
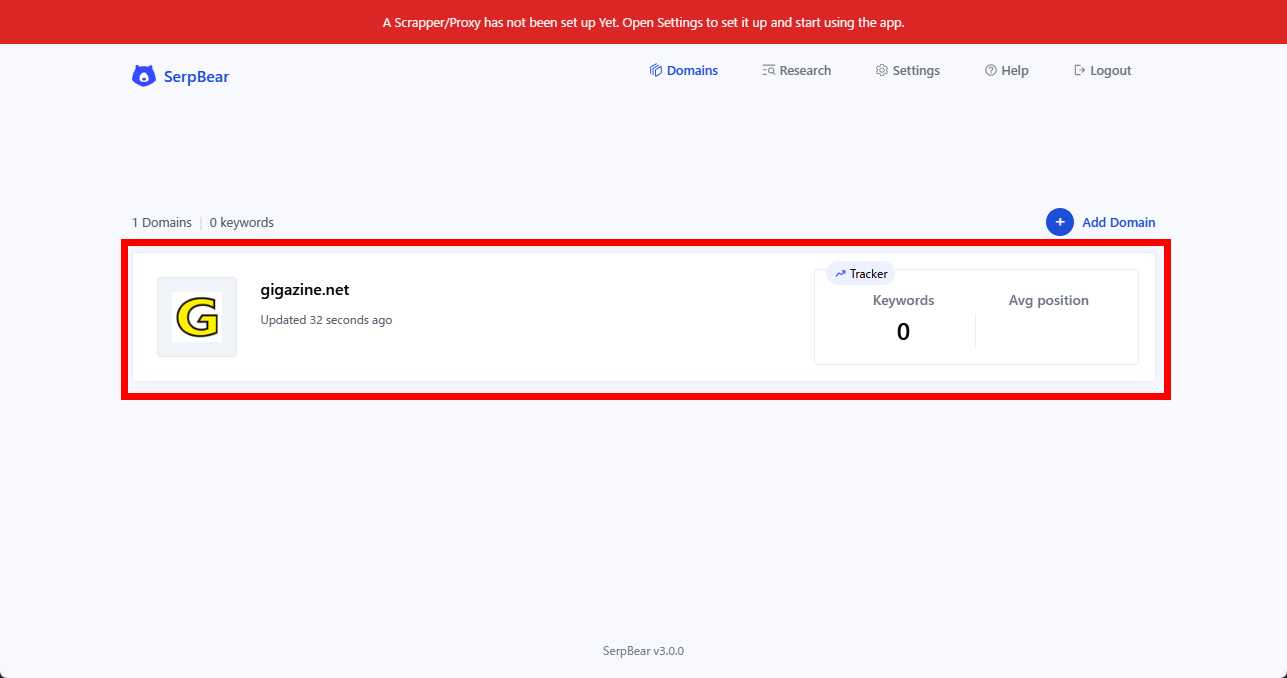
画面中央にドメインが表示されれば登録完了です。
◆スクレイパーの設定
SEOトラッキングをする上で重要なのが指定されたキーワードでGoogle検索の結果を収集する「スクレイピング」です。しかしながらGoogleを直接スクレイピングするとIPアドレスがブロックされてしまうので、サードパーティーのスクレイパーもしくはプロキシーを使用する必要があります。今回は ScrapingRobotの提供するスクレイパーを無料クレジット分から使う手順で進めます。ただしScrapingRobotに登録できるのは18歳以上からです。
Scraping Robot | Quality Web Scraping | Try Our API Today
https://scrapingrobot.com/
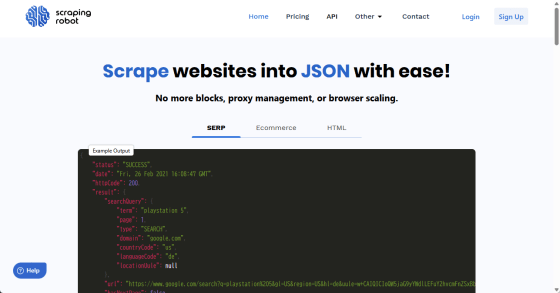
トップページを下にスクロールすると「Get 5k Free Credits」ボタンが現れるのでクリックして登録フォームに移動します。
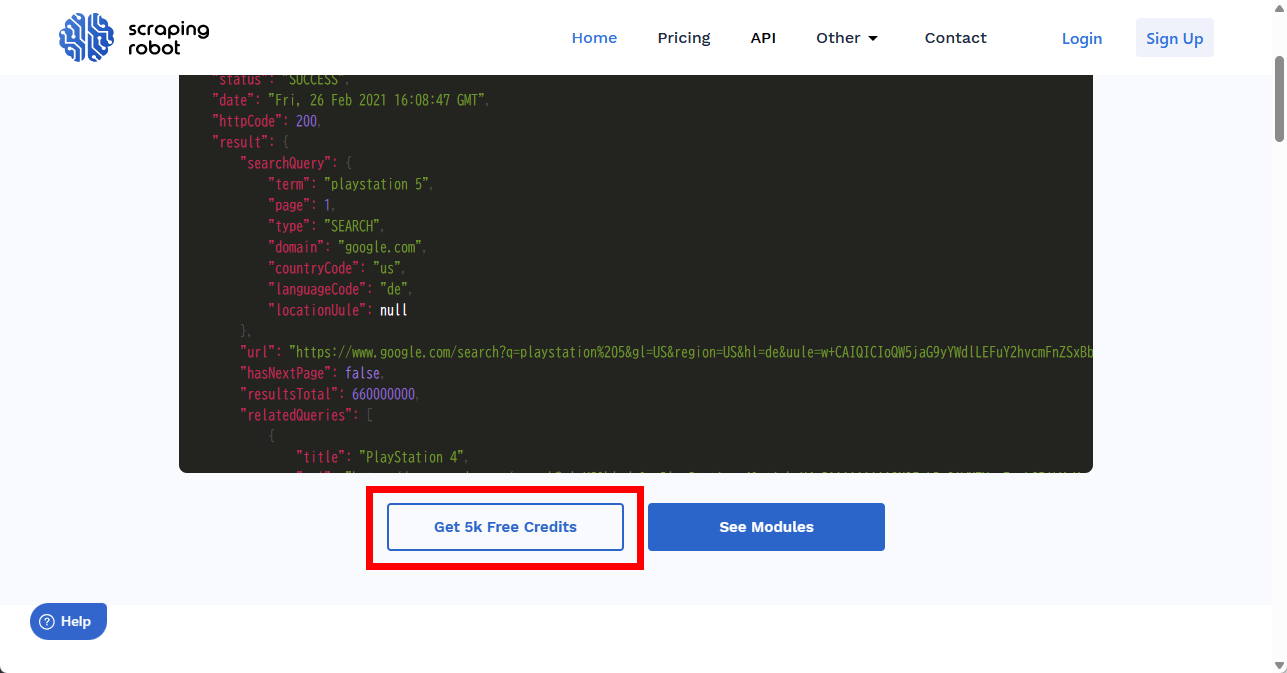
登録フォームで氏名・メールアドレス・パスワードを入力し「I am at least 18 years of age」をチェック、利用規約・利用規定・プライバシーポリシーの同意にチェックしreCAPTCHAを解決して「Get Started」ボタンをクリックすると登録できます。
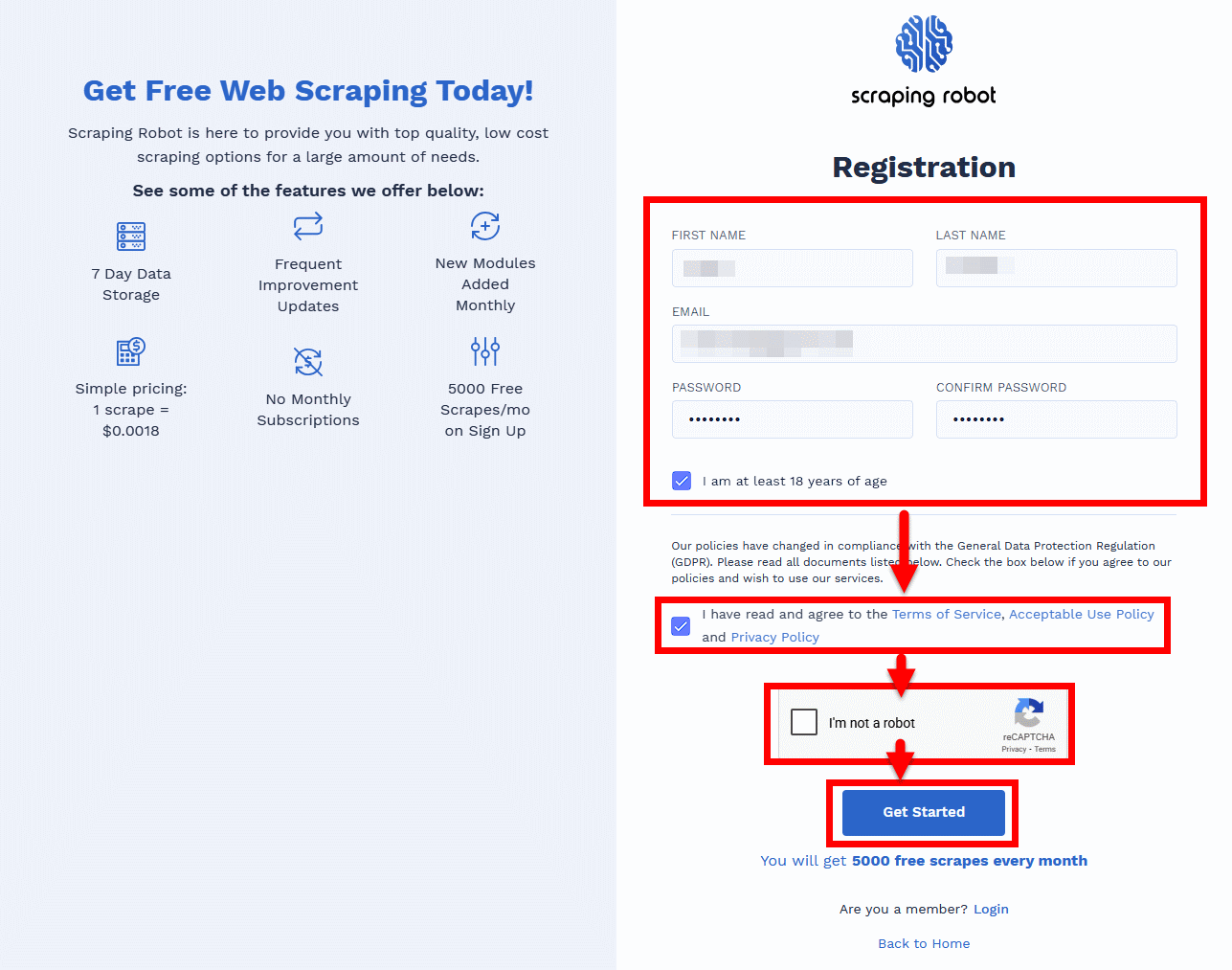
「Dashboard」画面に移動するので、「Exsample API Call」欄に表示されているURLのうち「token=」と「&url=https://www.bing.com」の間にあるUUID形式文字列をトークンとして取得します。
SerpBearの画面に戻り「Settings」をクリックします。
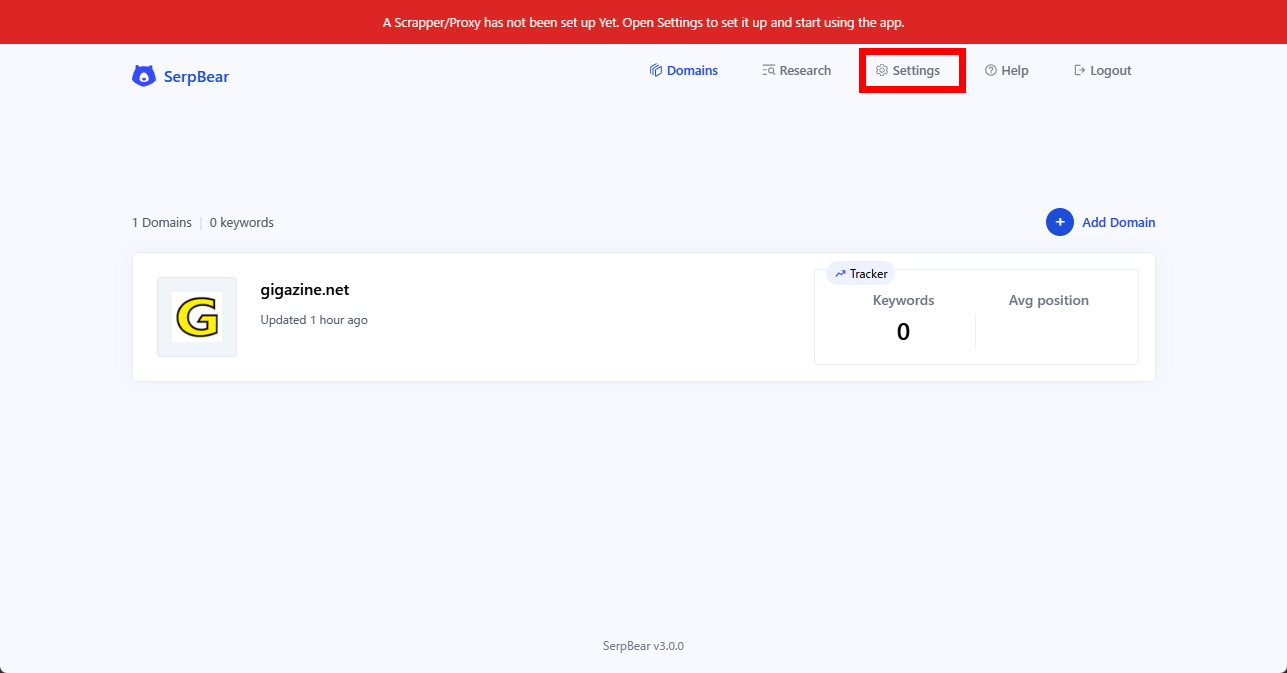
「Scraper」タブの「Scraping Method」で「Scraping Robot」を選択、「Scraper API Key Or Token」に取得したトークンを入力します。それ以外はデフォルトのまま「Update Settings」をクリックすると設定は完了です。
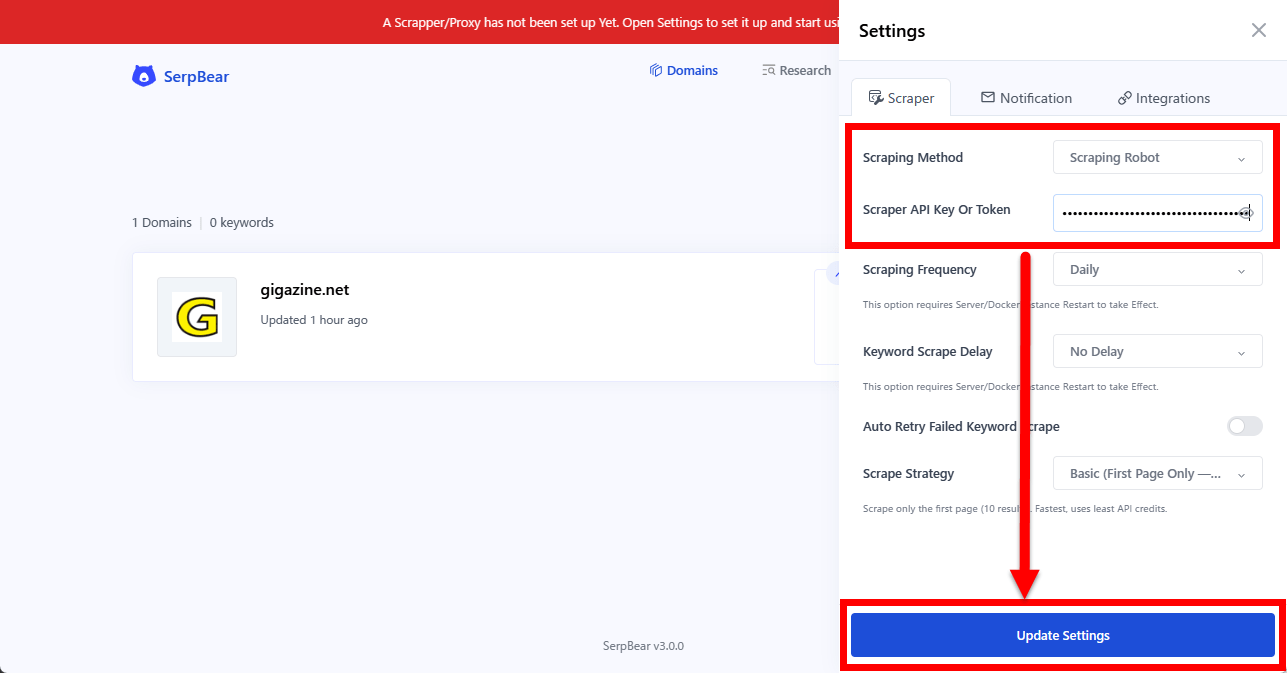
これまで画面上部に表示されていた警告が消えていればちゃんと設定されています。
◆キーワードの設定
スクレイパーの設定が完了したら登録したドメイン名をクリックします。
ドメイン画面に移動したら「Add Keyword」をクリックし、追跡したいキーワードを入力します。
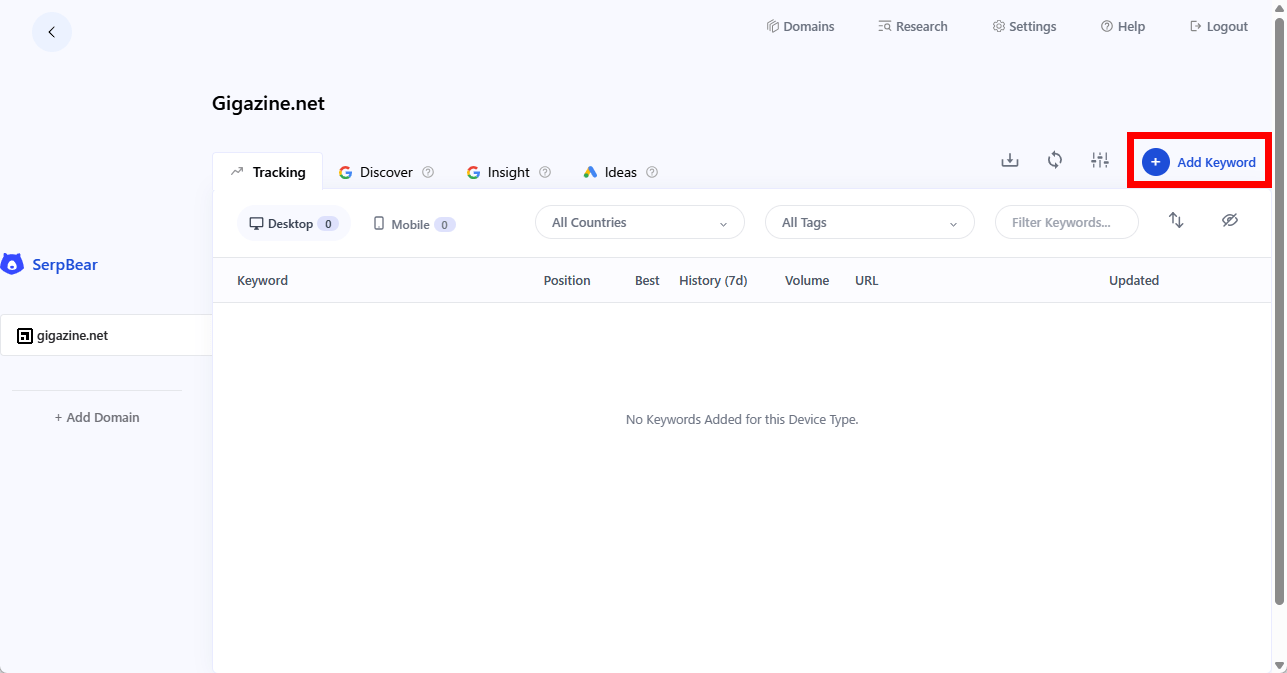
「Add New Keywords」ポップアップが表示されたらキーワードを入力し「Japan」を選択、調査対象によって「Desktop」か「Mobile」を選択して「Add Keywords」ボタンをクリックします。
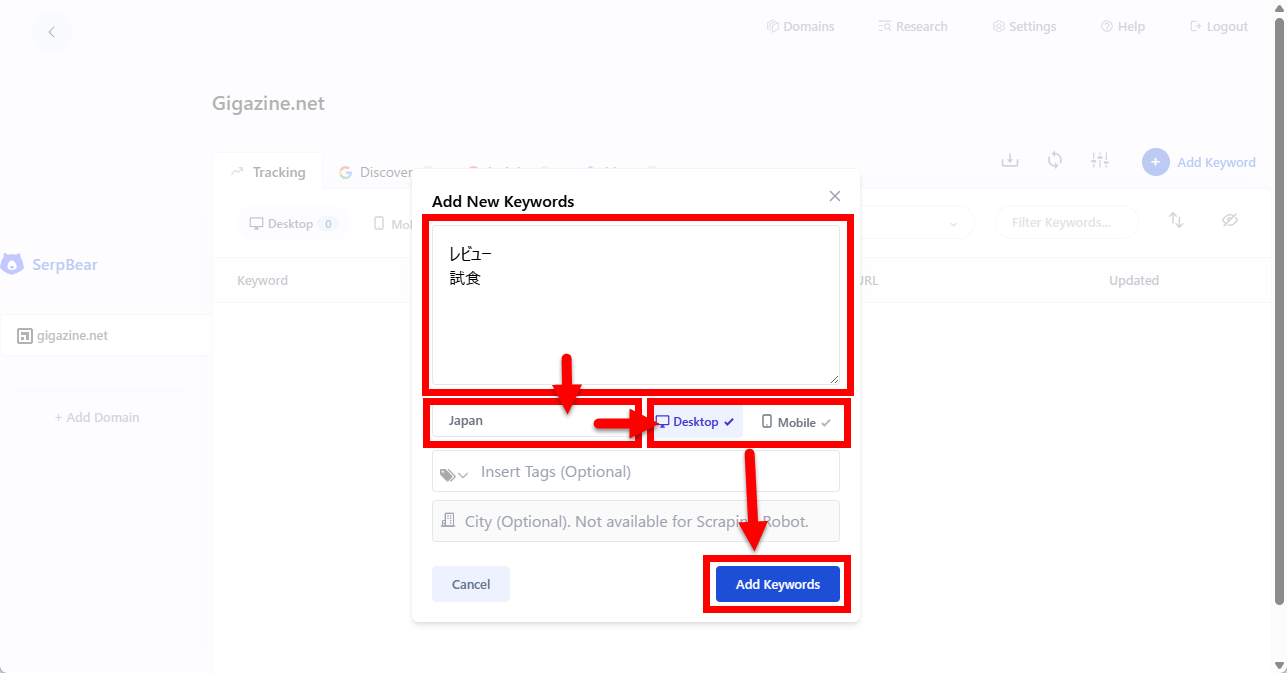
正しく設定できていればドメイン画面に反映しています。
◆メール通知の設定
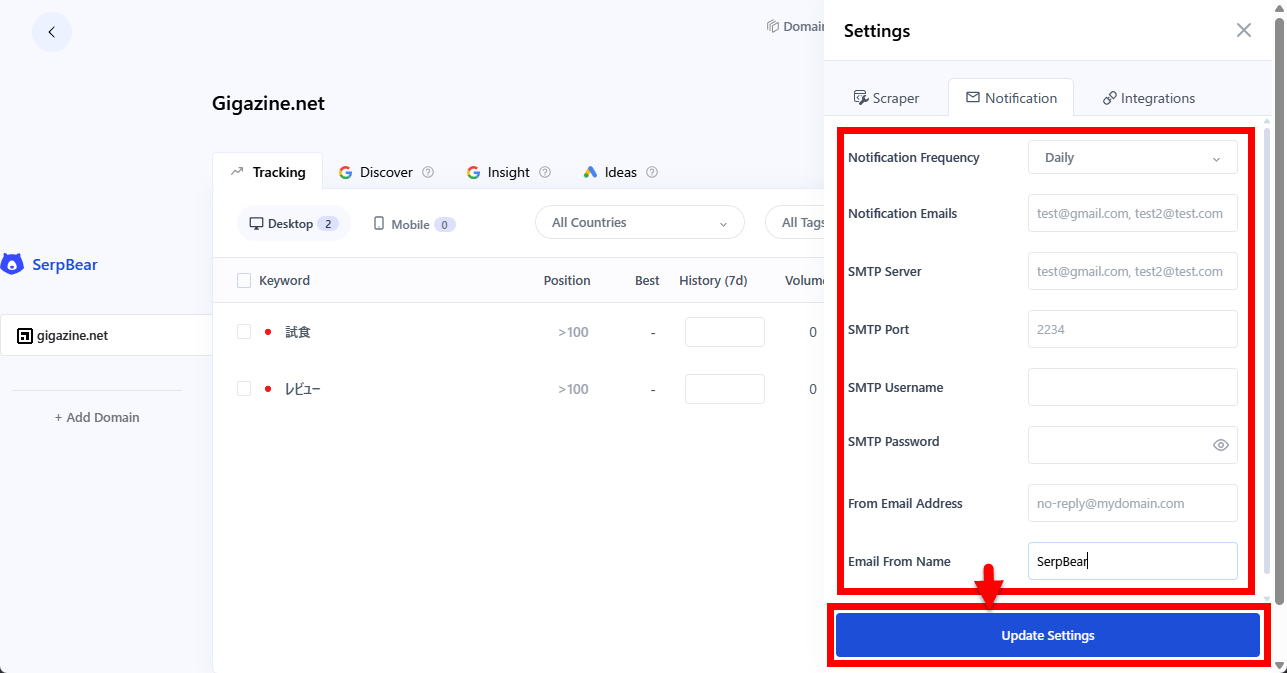
「Settings」でSMTPの設定を行うことによりキーワードの順位をメールで通知できるようになります。「Settings」をクリックし「Notification」タブで「Notification Frequency」を「Never」以外にするとSMTPの設定項目が表示されるようになります。
◆Googleとの連携
Google広告をSerpBearに統合すると以下の機能が利用可能になります。
・「検索」ページからキーワードを検索
・サイトのコンテンツ・Google Search Consoleで既にランキングされているキーワード・トラッキングされているキーワード・カスタムキーワードに基づいて、ウェブサイトのキーワードアイデアを生成
・追跡対象キーワードの月間検索ボリュームデータを表示
また、Google Search Consoleアカウントを統合することにより以下の機能が利用可能になります。
・実際の訪問数・インプレッション数・平均掲載順位を表示
・Googleで上位表示されているキーワードを探索
・過去30日間の統計情報の表示
・通知メールによる過去7日間のSearch Consoleデータ取得
◆API呼び出し
SerpBearはウェブAPIによる呼び出しも可能です。APIの認証にはBearer Tokenを使用した基本認証が使用でき、Authorizationヘッダーに「Bearer 【APIKEY】」を設定することにより認証をクリアできます。【APIKEY】の部分は導入時に作成した「.env」ファイルに記載されたAPIKEYの値を使用します。
試しにローカルで実行中のSerpBearで以下のAPIを呼び出してみました。
http://localhost:3000/api/keyword?id=1
結果として以下のJSONを取得できました。
{
"keyword": {
"ID": 1,
"keyword": "レビュー",
"device": "desktop",
"country": "JP",
"city": "",
"latlong": "",
"domain": "gigazine.net",
"lastUpdated": "2026-03-13T12:43:20.882Z",
"added": "2026-03-13T12:39:53.122Z",
"position": 0,
"history": {
"2026-3-13": 0
},
"volume": 0,
"url": "",
"tags": [],
"lastResult": [
【中略】
],
"sticky": false,
"updating": false,
"lastUpdateError": false,
"settings": null
}
}
なお、用意されているAPIは以下の通りです。
| メソッド | API | 概要 |
|---|---|---|
| GET | /api/keyword | キーワードのデータを取得 |
| GET | /api/keywords | ドメインに登録したすべてのキーワードを取得 |
| GET | /api/domains | すべてのドメインを取得 |
| POST | /api/refresh | 指定されたキーワードのSERP順位を更新 |
| POST | /api/cron | すべてのキーワードのSERP順位を更新 |
| POST | /api/notify | すべてのキーワードのSERP順位を即座にメール通知 |
◆まとめ
SerpBearは使いやすく機能も充実したSEOトラッキングツールであることが確認できました。セルフホスト可能で軽快に動作する上に無料で利用できるので、SEOを効率よくシステム的に運用していきたい人に最適です。
・関連記事
無料でページにコメント機能を追加するオープンソースWebコメントエンジン「Comentario」、Dockerでセルフホスト可能 - GIGAZINE
個人利用なら完全無料かつセルフホストも可能なDockerコンテナ管理ツール「Dockhand」 - GIGAZINE
伝統的なSEO対策はすでに死滅しており「AIの要約対策」が急務だとの指摘、一体どのようにすれば良いのか? - GIGAZINE
Googleが規制を強化した「パラサイトSEO」とは何か? - GIGAZINE
無料でセルフホストも可能なオープンソースの地図「OpenFreeMap」 - GIGAZINE
SEOのようにAIの出力を改変する「AI最適化(AIO)」のアドバイスを実践してみた結果とは? - GIGAZINE
パスワード共有用URLをサクッと発行して安全に共有できるウェブアプリ「Password Pusher」レビュー、無料で使えてセルフホストも可能 - GIGAZINE
・関連コンテンツ

in ソフトウェア, レビュー, ウェブアプリ, Posted by log1c_sh
You can read the machine translated English article SerpBear is a free SEO tracking tool tha….