




画像生成&編集AI「Qwen-Image-Edit-2511」登場、人物やオブジェクトの一貫性が向上&人気LoRAを内蔵してさらに高品質化

中国の大手テクノロジー企業であるAlibabaのAIモデルであるQwenシリーズから、画像編集タスクを搭載した画像生成AIのQwen-Image-Ediの強化版となる「Qwen-Image-Edit-2511」が登場しました。グループ写真や複雑なシーンでも人物一貫性を保つことができるほか、LoRAを内蔵していることで追加の調整不要で表現力を広げることができます。
Qwen-Image-Edit-2511: Improve Consistency
https://qwen.ai/blog?id=qwen-image-edit-2511

🚀 Introducing Qwen-Image-Edit-2511 — a major upgrade over 2509, delivering significantly stronger consistency and more powerful real-world image editing.
— Qwen (@Alibaba_Qwen) 2025年12月23日
✨ What’s new in 2511:
👥 Stronger multi-person consistency for group photos and complex scenes
🧩 Built-in popular community… pic.twitter.com/Fbf3bvMLbY
Qwen-Image-Edit-2511は2025年9月にリリースされたQwen-Image-Edit-2509を大幅に強化したモデルで、「言語ベースの画像編集」「高品質な整合性」といったQwen-Image-Editの基本的な特徴は引き継がれつつ、編集プロセスでの人物の顔や特徴を保持する性能が格段に向上しています。以下はAlibabaが示した編集例で、画像左の入力画像から、自然言語による編集プロンプトのみで衣装やポーズを変えた右の画像へと編集しています。この時、同じ人物を様々なポーズや背景で編集する場合でも「元の特徴が崩れない」編集が可能になっています。

また、人物をキャラクターイラストにする場合も特徴を反映しやすくなっているとのこと。

Qwen-Image-Edit-2509でも単一被写体の一貫性は高くなっていましたが、Qwen-Image-Edit-2511ではさらに、複数人物のグループ写真の一貫性が大きく向上しています。2枚の別々の人物写真や、人物とネコの写真を組み合わせるといった編集も得意としています。

Qwen-Image-Edit-2511は、前モデルから引き継いだ高精度な画像編集能力に加えて、人気のLow-Rank Adaptation(LoRA)をモデルに統合した点も大きな特徴です。LoRAは元となる大規模言語モデルを書き換えずに、「特定の画風」「表現のクセ」「被写体の描き方」などを後付けで学習・追加できる軽量な拡張技術で、インターネット上では有志が作成したQwen-Image-Edit用のLoRaが多数公開されています。Qwen-Image-Edit-2511には複数の人気LoRaが統合されているため、ユーザーは自分でLoRaを準備せずとも照明制御などのLoRa由来の機能を使うことができます。

Qwen-Image-Edit-2511はプロダクトデザインや工業用途での編集精度や構造表現に強化ポイントを置いています。1つの製品の一貫性を保ちながら複数の方向から生成するほか、複雑な製品のカラーや素材を交換するなどの工業デザイン画像の整合性が向上しています。

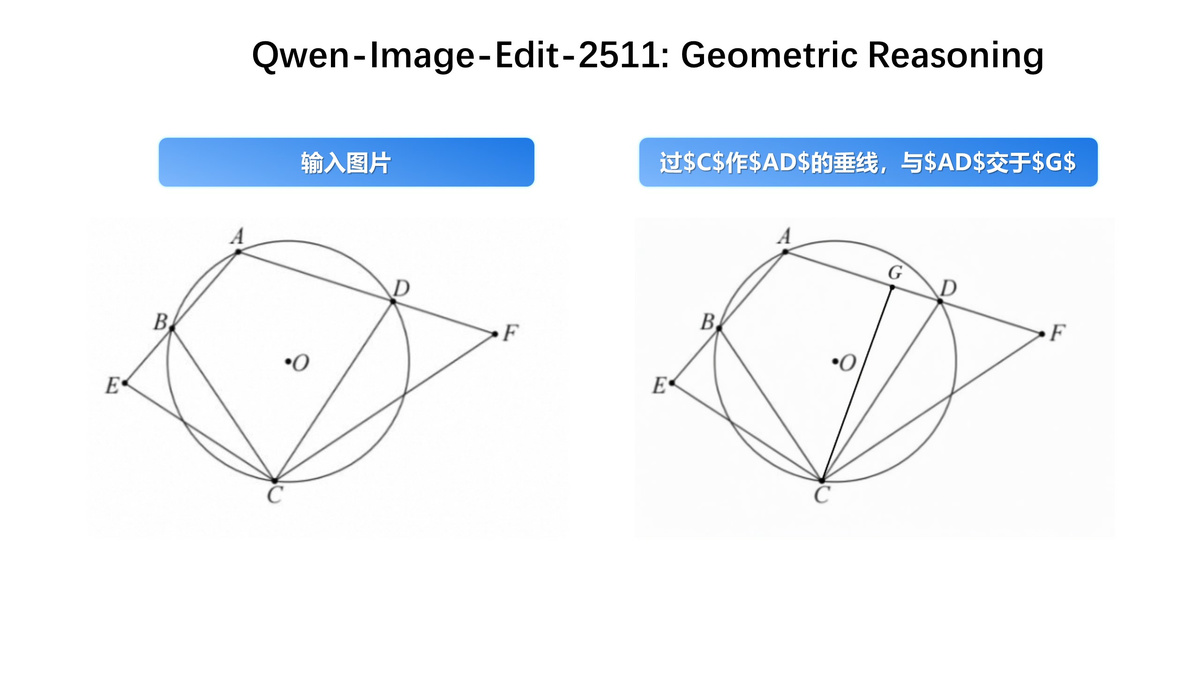
そのほか、Qwen-Image-Edit-2511ではより強力な幾何学的推論機能が導入されています。設計や注釈の目的で補助構築線を直接生成できるようになっており、建築・設計要素の編集などで活用できます。
Qwen-Image-Edit-2511のデモはHugging Faceで公開されています。
Qwen Image Edit 2511 - a Hugging Face Space by Qwen
https://huggingface.co/spaces/Qwen/Qwen-Image-Edit-2511
・関連記事
画像生成AI「Qwen-Image」登場、OpenAIやFlux超えの高品質画像を生成可能で「複数行の漢字」を自然に描写できる驚異的テキスト描画性能をアピール - GIGAZINE
キャラクターを維持したまま別のシチュエーションに描き直せる画像編集AI「Qwen-Image-Edit」が登場、文字の描き直しや「被写体の回転」も可能 - GIGAZINE
画像をレイヤー分けできるAIモデル「Qwen-Image-Layered」が登場 - GIGAZINE
Alibabaが多言語の音声を認識してリアルタイム会話が可能なAIモデル「Qwen3-Omni-Flash」のアップグレード版を発表 - GIGAZINE
Alibabaの視覚言語AIモデル「Qwen3-VL」は2時間ある映像に挿入されたフレームを99.5%の精度で特定可能 - GIGAZINE
・関連コンテンツ






in AI, Posted by log1e_dh
You can read the machine translated English article Introducing the image generation and edi….