




GoogleがAIの長期記憶を支援するアーキテクチャ「Titans」とフレームワーク「MIRAS」を開発
GoogleがAIモデルの長期記憶を支援するためのアーキテクチャである「Titans」と、フレームワークの「MIRAS」を発表しました。
Titans + MIRAS: Helping AI have long-term memory
https://research.google/blog/titans-miras-helping-ai-have-long-term-memory/
2017年6月にGoogleの研究チームが発表した深層学習モデルのTransformerは、AIモデルが過去の入力を振り返り、関連する入力データを優先するメカニズムであるAttentionを導入することで、シーケンスモデリングに革命を起こしました。しかし、シーケンスの長さに応じて計算コストが大幅に増加するため、TransformerベースのAIモデルを完全な文書理解やゲノム解析に必要なような「非常に長いコンテキスト」に拡張することは困難です。
研究コミュニティは、効率的な線形リカレントニューラルネットワーク(RNN)やMamba2のような状態空間モデルなど、さまざまなアプローチによる解決策を模索してきました。これらのAIモデルはコンテキストを固定サイズに圧縮することで、高速かつ線形なスケーリングを実現します。しかし、固定サイズの圧縮では非常に長いシーケンスに含まれる豊富な情報を適切に捉えることができません。
そこで、Googleは新しく「Titans」と「MIRAS」を発表しました。Titansは具体的なアーキテクチャで、MIRASはアプローチを一般化するための理論的枠組みです。これらを組み合わせることで、AIモデルの実行中により強力なサプライズ指標(予期しない情報)を組み込むことで、専用のオフライン再学習なしにAIモデルが長期記憶を維持できるようになります。
◆Titans
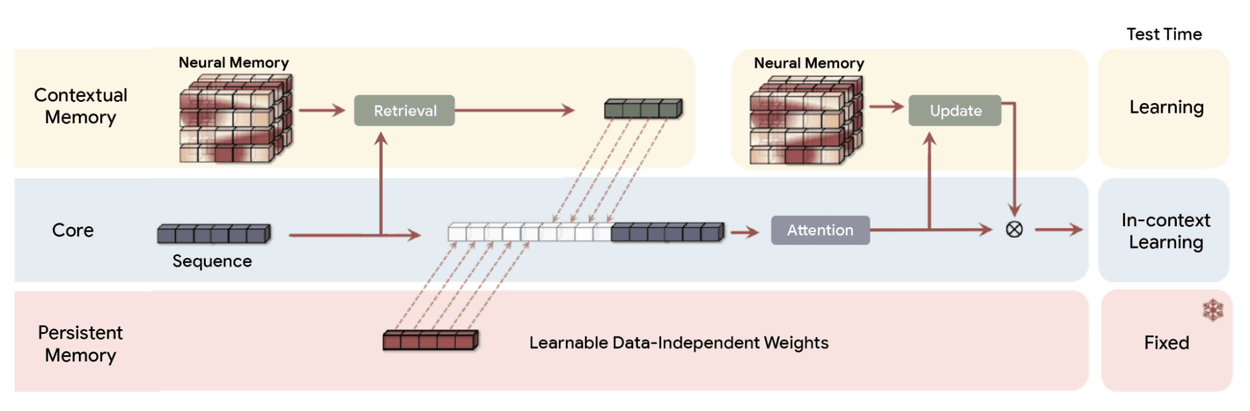
Titansは従来のRNNにおける固定サイズのベクトルまたは行列メモリとは異なり、ディープニューラルネットワーク(具体的には多層パーセプトロン)として機能する、新たなニューラル長期記憶モジュールを導入しています。この記憶モジュールは、大幅に高い表現力を提供し、AIモデルが重要な文脈を失うことなく大量の情報を要約することが可能です。これにより、AIモデルは単にメモを取るのではなく、ストーリー全体を理解し、統合することができるようになります。
重要なのは、Titansが単に受動的にデータを保存するのではないという点です。入力全体にわたってトークンを繋ぐ重要な関係性や概念的テーマを認識し、保持する方法を能動的に学習します。この能力における重要な側面は、Googleが「サプライズメトリック」と呼ぶものです。心理学では、人間は日常的で予想通りの出来事をすぐに忘れてしまうものの、パターンを破る出来事、つまり予期せぬ出来事や驚くべき出来事、あるいは非常に感情的な出来事は記憶に残りやすいということが知られています。Titansの「サプライズメトリック」はこれに習い、これまでの入力にない驚き度が高い情報を、長期記憶モジュールへ保存することを優先するというものです。
◆MIRAS
シーケンスモデリングにおける主要な進歩は、その内部では本質的に同じもの、つまり非常に複雑な連想メモリモジュールにあります。
MIRASがユニークかつ実用的なのは、AIモデリングに対するそのアプローチにあります。多様なアーキテクチャを見るのではなく、同じ問題を解決する異なる手法、つまり重要な概念を忘れることなく、新しい情報と古い記憶を効率的に組み合わせる手法を見ているわけです。
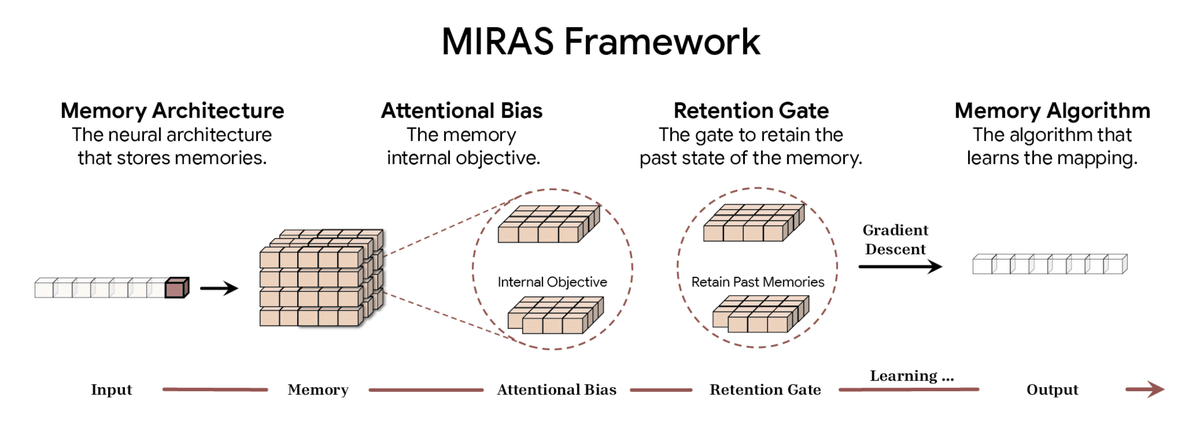
MIRASは以下の4つの主要な設計選択を通じてシーケンスモデルを定義します。
メモリアーキテクチャ:情報を格納する構造(例:ベクトル、行列、Titansのような深い多層パーセプトロン)
注意バイアス:AIモデルが最適化する内部学習目標で、優先順位を決定します。
保持ゲート:記憶の正則化装置。MIRASは「忘却メカニズム」を新しい学習と過去の知識の保持のバランスをとる特定の形式の正則化として再解釈します。
メモリアルゴリズム:メモリを更新するために使用される最適化アルゴリズムです。
成功している既存のシーケンスモデリングは、バイアスと保持率の両方において平均二乗誤差やドット積類似度に依存しています。この依存により、AIモデルは外れ値に敏感になり、表現力が制限される傾向にあるそうです。
MIRASは最適化と統計学の文献に基づいたより豊富な設計空間を探索するための生成フレームワークを提供することで、この限界を克服します。非ユークリッド目的関数と正則化を備えた新しいアーキテクチャの作成が可能になります。
GoogleはMIRASを使用することで、以下の3つの注意不要モデルを作成しました。
・YAAD
YAADはMIRASの変異モデルで、大きなエラーや「外れ値」(例:大きな文書内の単一のタイプミスなど)に対する感度が低くなるように設計されています。誤りに対してより緩やかな数学的ペナルティ(Huber損失)を適用するため、単発的な問題に過剰反応することはありません。これにより、入力データが乱雑であったり一貫性がなかったりする場合でも、モデルはより堅牢になります。
・MONETA
MONETAは、より複雑で厳格な数学的ペナルティ(一般化規範)の使用を探求するモデルです。モデルが注目するものと忘れるものの両方に、これらのより規律のある規則を適用することで、全体としてより強力で安定した長期記憶システムを構築できるようになっています。
・MEMORA
MEMORAはメモリを厳密な確率マップのように動作させることで、可能な限り最高のメモリ安定性を実現することに重点を置いたモデル。この制約を用いることで、メモリ状態が更新されるたびに、その変化が制御され、バランスが保たれます。これにより新しい情報を統合するためのクリーンで安定したプロセスが保証されます。既存の成功したシーケンスモデルのほとんどは、バイアスと保持の両方において、平均二乗誤差またはドット積類似度に依存していますが、これによりモデルは外れ値に敏感になり、表現力が制限されます。
Googleの研究チームはTitanとMIRASの派生モデルであるYAAD、MONETA、MEMORAを、Transformer++、Mamba2、Gated DeltaNetといった主要アーキテクチャと厳密に比較しました。さらに、ゲノムモデリングや時系列予測にTitansをテストすることで、各AIモデルの汎用性を検証し、このアーキテクチャがテキスト処理を超えて効果的に一般化できることを実証しています。
TitansとMIRASの導入は、シーケンスモデリングにおける大きな進歩を意味します。ディープニューラルネットワークをデータが入力されるにつれて記憶を学習するメモリモジュールとして用いることで、これらのアプローチは固定サイズの再帰状態の限界を克服します。さらに、MIRASは強力な理論的統一をもたらし、オンライン最適化、連想記憶、アーキテクチャ設計の関連性を明らかにしました。GoogleはTitansとMIRASについて、「標準的なユークリッドパラダイムを超越することで、本研究はRNNの効率性とロングコンテキストAI時代に求められる表現力を兼ね備えた、新世代のシーケンスモデルへの扉を開きます」と説明しています。
・関連記事
Googleの画像生成AI「Gemini 3 Pro Image(Nano Banana Pro)」が登場、Geminiの推論機能を応用して言語対応や情報整理能力が強化 - GIGAZINE
Googleの画像生成AI「Gemini 3 Pro Image(Nano Banana Pro)」は過去モデルや他社製モデルと比べてどれくらい優秀なのか? - GIGAZINE
GoogleのオープンソースAIモデル「Gemma」がGoogle AI Studioから削除される、議員からの要求が原因か - GIGAZINE
Googleの拡散型言語モデル「Gemini Diffusion」はどれくらい爆速なのか? - GIGAZINE
・関連コンテンツ








in AI, Posted by logu_ii
You can read the machine translated English article Google develops 'Titans' architecture an….