




「Zen 6世代のDNAを秘めている」と評価されるモバイル向け高性能APU「AMD Ryzen AI MAX」シリーズは何がそれほど特別なのか?

半導体メーカーのAMDは、2025年1月に開催された世界最大級の技術見本市「CES 2025」で、「Strix Halo」のコードネームで開発されていたモバイル向けAPU「Ryzen AI MAX」シリーズを発表しました。このRyzen AI MAXについて、半導体関連の情報を扱うYouTubeチャンネル「High Yield」が以下のムービーで解説しています。
How AMD is re-thinking Chiplet Design - YouTube

High Yieldは、AMDが新しいレイアウト、シリコン、パッケージングによってチップレットアーキテクチャを再構築しており、Ryzen AI MAXシリーズは「ZEN 6のDNA」を垣間見せていると主張しています。

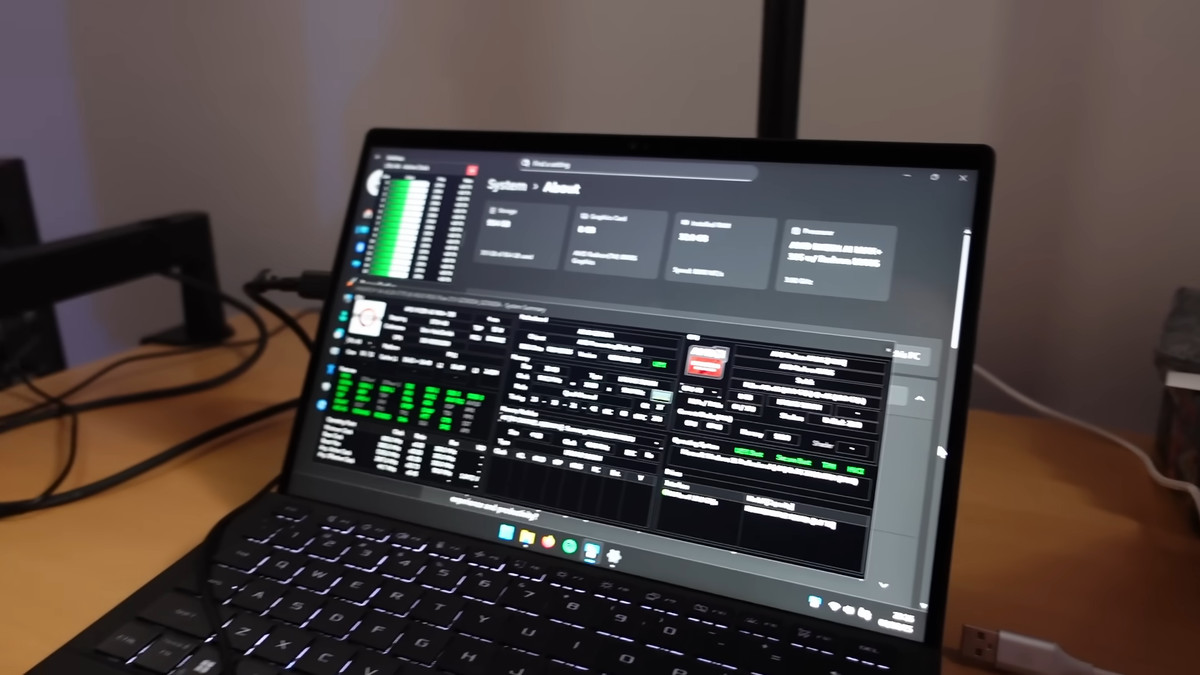
Ryzen AI MAXシリーズはすでに市場に出荷されており、High Yieldで録画や編集に使っているASUSのノートPC「ROG Flow Z13」にも搭載されています。Ryzen AI MAXシリーズのダイ写真がX(旧Twitter)に公開されていたので今回はその画像を使っているそうですが、High Yieldは「最終的にはこのROG Flow Z13を分解してダイの写真を撮影するつもりだった」と語ります。
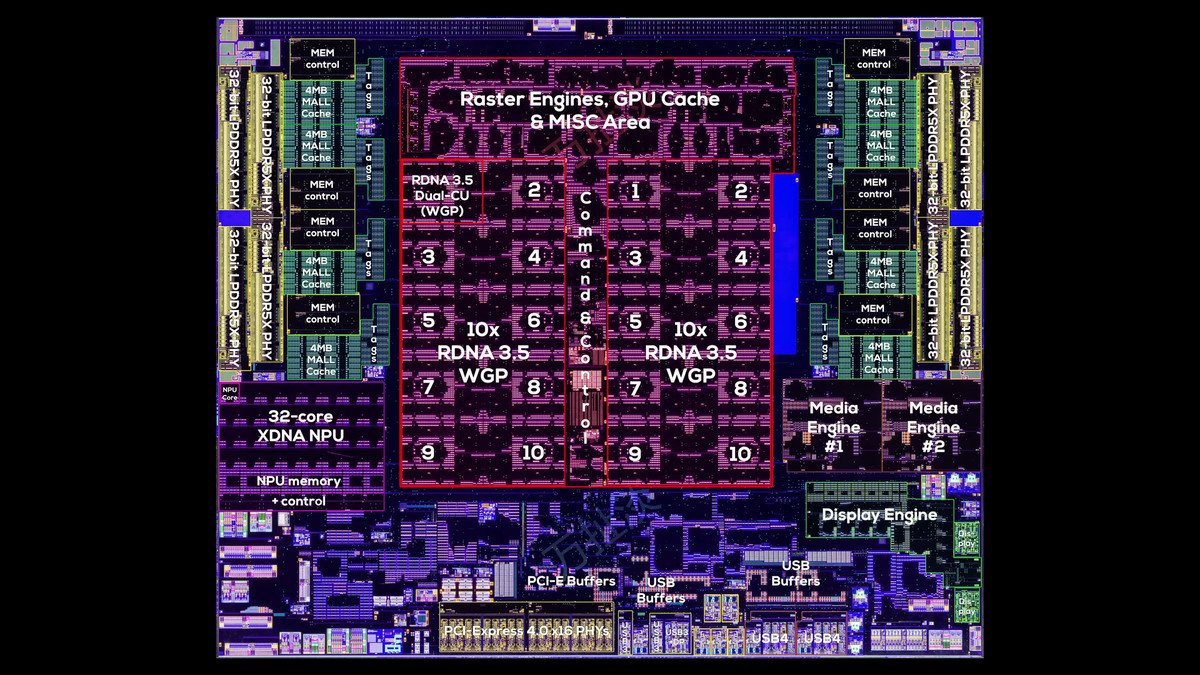
AMDは、Zen 2以来のチップレット設計を一新し、新しいシリコン、パッケージング、レイアウトを採用しています。この次世代設計を初めて採用したのがモバイル向けAPUのRyzen AI MAXシリーズ(Strix Halo)です

2019年に発表されたAMDのZen 2アーキテクチャは非常に優れていたため、Zen 5アーキテクチャまではZen 2の設計がベースになっていたとのこと。

Strix Haloは、Zen 2以来の従来のAMDチップレット設計とは異なり、見た目はIntelのタイルベース設計に近いものになっています。TSMCのN4Pプロセスで製造された2つのCPUチップレット(CCD)と約307mm2の巨大なSoCダイで構成されています。

SoCダイは、チップの端に4つずつ配置された合計8つの32ビットLPDDR5Xメモリにより、256ビットの広帯域インターフェースと、32MBのL3キャッシュを備えています。これは、競合APUの約2倍のメモリ帯域幅を提供するとのこと。チップの中央には、40基のRDNA 3.5演算ユニット(CU)を持つ大規模な統合GPUが搭載されており、これはGeForce RTX 4060や4070モバイル版に匹敵する性能です。また、SoCダイの左側には、Xilinx技術に基づく32コアXDNA NPUも配置されています。右側にはメディアエンジンとディスプレエンジン、下部にはPCI-Express 4.0が16レーン、USB 2.0、USB 3.0、USB4があります。
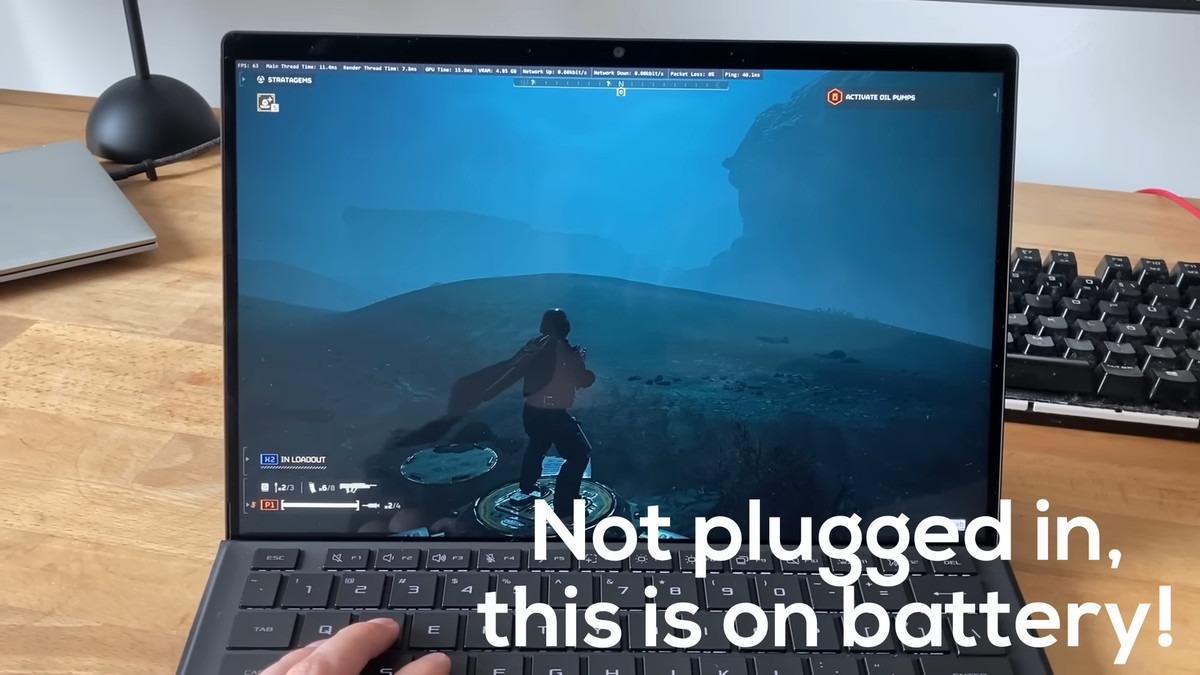
High Yieldが実際にRyzen AI Max+ 395を搭載するROG Flow Z13で、ゲーム「ヘルダイバー2」をプレイしたところ、電源ケーブルをつながずバッテリー駆動の状態で、中~高の画質設定で60FPS以上で快適にプレイできたとのこと。High Yieldは、「このパフォーマンスは、モバイル版のGeForce RTX 4060、あるいは4070で達成できる性能に匹敵する」と評価し、「これは、40基のRDNA 3.5CUと広帯域なメモリインターフェースにより、従来のモバイルAPUでは不可能だった、ディスクリートGPUクラスのゲーミング性能を小型のタブレット型PCで実現していることを示している」とコメントしました。
SoCダイ上部に見える長方形の領域は、AMDの次世代ダイ間相互接続部。High Yieldは「この部分こそ『ZEN 6のDNA』といえる」と述べています。
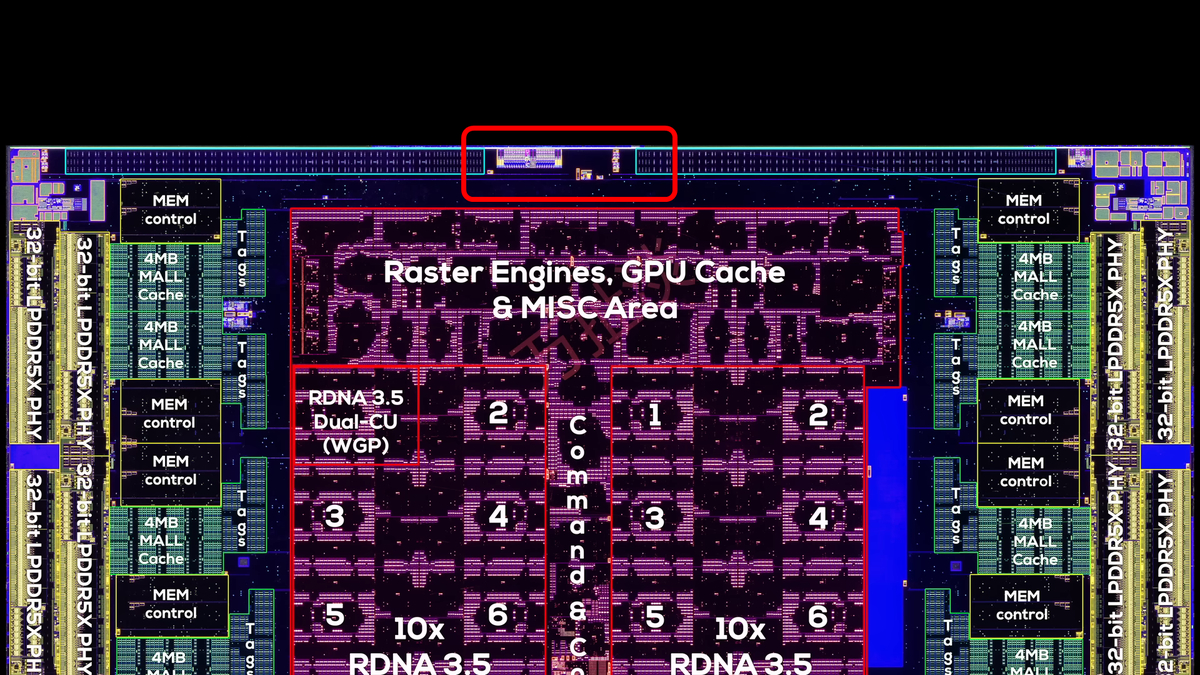
ダイ写真を見ると、SoCダイの上部にあるこの長方形の領域が、2つのCCDに対応していることがわかります。

この次世代ダイ間相互接続部をみると、Zen 5のSerDesとは異なり、多数の小さな相互接続の列で構成されています。

Zen 2からZen 5で使用されているAMDの「Infinity Fabric on Package」は、このSerDesを使用したシリアル相互接続です。SerDesはPCI Expressの設計に基づいており、チップレット間の通信を可能にしています。

たとえるなら、SerDesと配線は「ハイウェイ」のような物理層であり、その上をデータの転送方法を定めるInfinity Fabricプロトコルが「車」として動いています。

Ryzen CPUのInfinity Fabricは、Global Memory Interconnect(GMI)と呼ばれる2つの独立したリンクで構成されています。1つのリンクは、8ビット幅のシリアル相互接続と1ビットのパリティビットで構成され、合計9つのロジックブロックに対応します。

コンシューマ向けRyzen CPUは、1つのリンクのみを使用するGMI-narrow実装を採用しているため、CCD上の2つのリンクのうち1つは常に未使用です。サーバー向けEPYC CPUは両方のリンクを使用するGMI-wideを採用しています。

Ryzen CPUはGMI-narrowを使用するため、1つのCCDはメモリ帯域幅をフルに活用できません。シングルCCD構成の場合、デュアルCCD構成よりもメモリ帯域幅が悪化します

8ビット幅のGMI-narrowを使用し、Infinity Fabricのクロック速度がDDR4-3600相当の1800MHzだった場合、理論上の最大帯域幅は読み出しで57.6GB/s、書き込みで28.8GB/sとなります。

これは実測値でも裏付けされています。
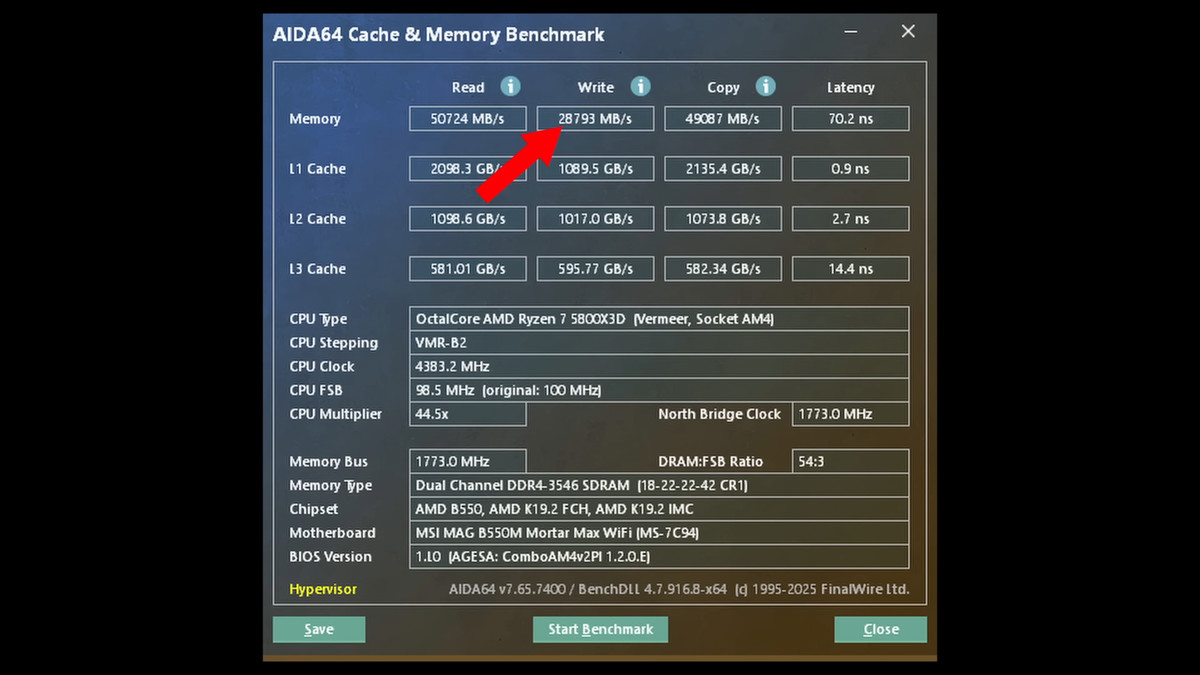
SerDesはデジタルシステムとアナログシステムの組み合わせであるため、プロセスノードが微細化してもサイズの縮小が非常に困難です。一方、Strix HaloのCCDに見られる、多数の非常に小さな相互接続の列は、そのサイズと数からSerDesではあり得ません。
High Yieldによれば、AMDは、「ファンアウト相互接続」と呼ばれる新しい接続方式に切り替えているとのこと。

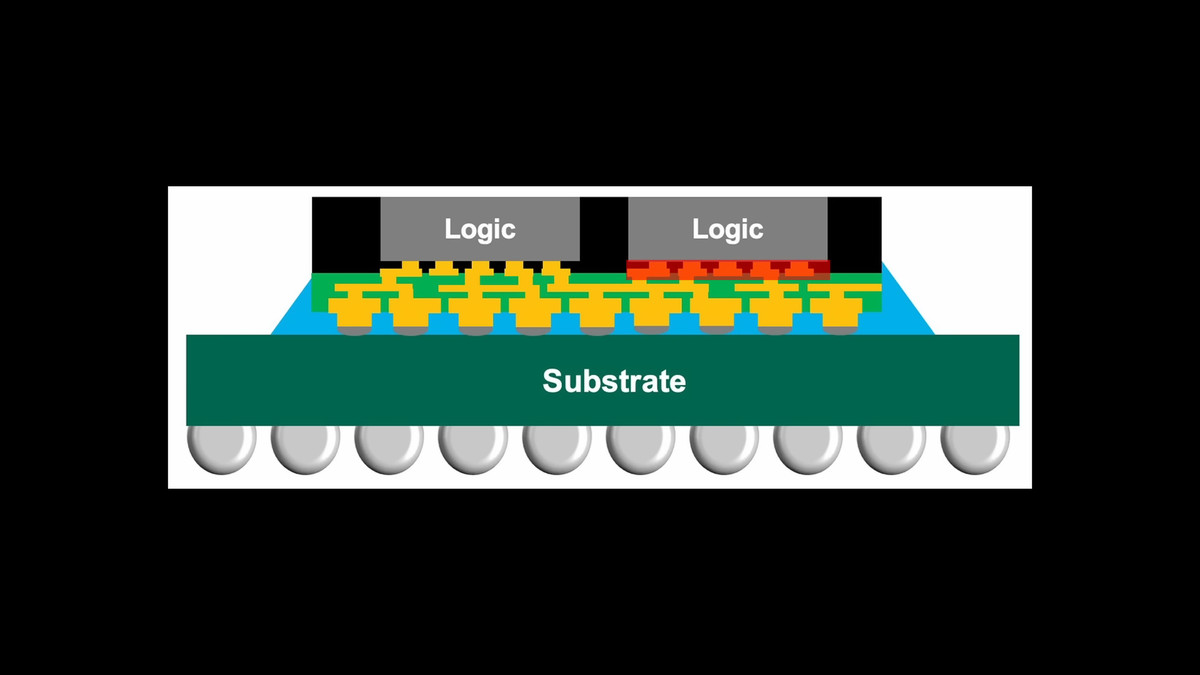
ファンアウト相互接続は、チップ間を接続するために、SerDesを通さず、単にワイヤーを一本のチップからもう一本のチップへと直接使用するという単純な概念に基づいています。シリアル接続ではなくパラレル接続を最大化するため、可能な限り多くのワイヤーを使用し、ワイヤーがダイの境界を超えて扇状、つまりファンアウトに広がる構造を採用しています。

しかし、現代のファンアウト相互接続では、単純に平面の広がりだけではワイヤー数が不足するため、配線は複数の層にわたって展開されます。この複雑な多層配線システムをサポートするための構造が必要となります。

High Yieldは、AMDが使用しているパッケージング技術はほぼ確実にTSMCの「InFO_oS(Integrated Fan-out on Substrate)」技術だと指摘しました。「on Substrate」とは、基板上に統合されたファンアウト技術を意味します。

InFO_oSは、TSMCのCoWoSやIntelのFoverosとは異なり、基板にシリコンインターポーザーを使わず、RDLインターポーザー」を使います。
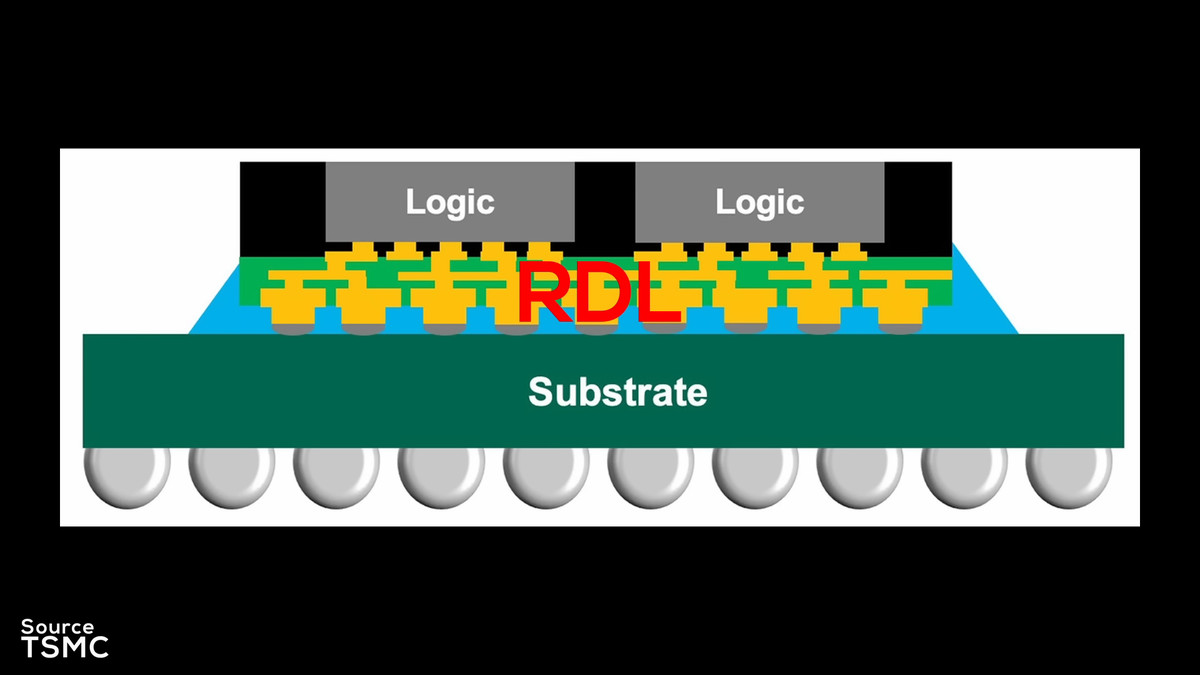
RDLインターポーザーは、電気信号を伝送する銅の層と、信号を互いに絶縁するための高分子誘電体材料の層で構成されています。
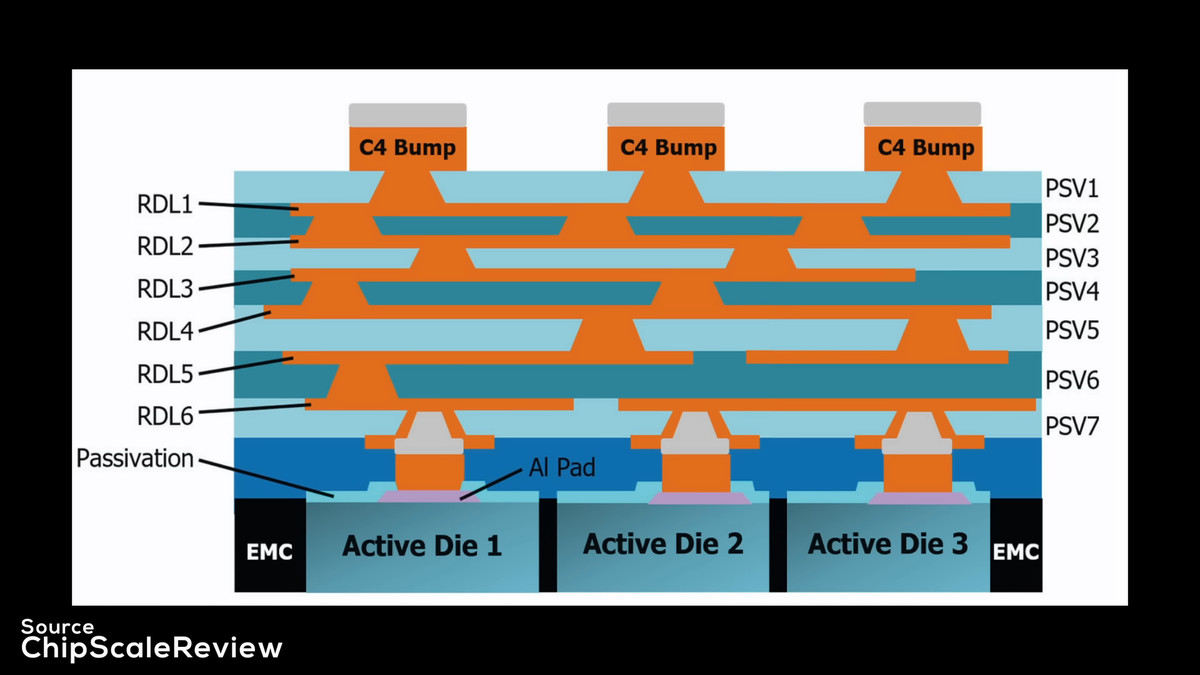
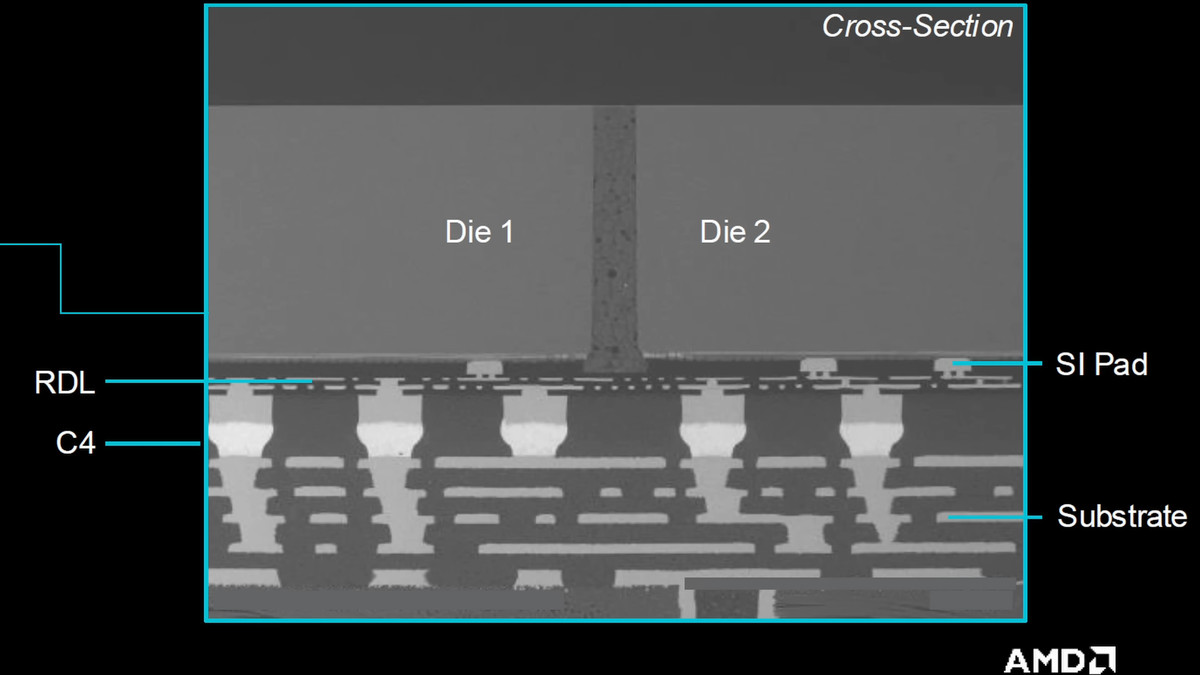
Strix Haloでは、SoCダイと2つのCCDがこのRDLインターポーザーの上に配置されます。RDLインターポーザーには、CCDとSoCダイ間の数百本の微細な相互接続がルーティングされています。

パッケージの断面図を見ると、最下部の基板と接続端子(C4)の間に、RDLインターポーザーが挟まれていることがわかります。チップレットはRDLインターポーザーに接続されています。ファンアウト相互接続の配線は、基板内のものよりもはるかに小さく、この微細化が高密度な相互接続を可能にしています。これにより、AMDは信号を変換することなく、CCDの内部データファブリックをSoCダイへとそのまま継続させることができ、SerDesが不要となっています。
ファンアウト相互接続の最大のメリットは、データ転送のエネルギー効率の劇的な向上と、SerDesの処理時間がないことによるレイテンシの解消です。Zen 2世代のInfinity Fabric on Packageは1ビットあたり約2ピコジュールを消費していましたが、ファンアウト相互接続は0.2ピコジュールと消費エネルギーが圧倒的に少なく、データ転送に必要なエネルギーが大幅に削減されます。

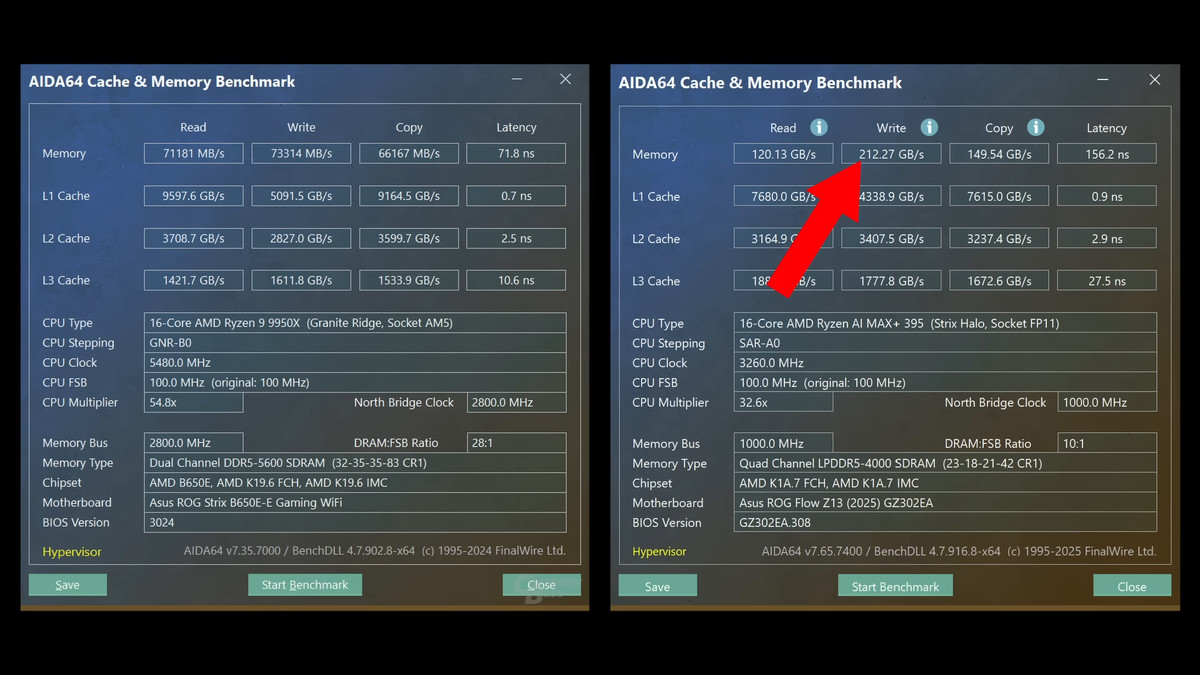
また、ファンアウト相互接続は、SerDesベースの設計が高周波数で動作する場合と同様に高い帯域幅を提供可能。Ryzen AI Maxシリーズは、Zen 5アーキテクチャのRyzen 9 9950Xと比較しても高いリード、コピー、ライトの帯域幅を示しており、相互接続の帯域幅が向上していることが確認されています。
ただし、ファンアウト相互接続は、RDLインターポーザーと微細な相互接続を構築するための高度なパッケージング技術を必要とするため、従来のInfinity Fabric on Packageソリューションよりも実装が複雑で高価になります。

また、従来のSerDesベースのInfinity Fabricは、チップレット間の距離が長くても接続が可能でしたが、新しいファンアウトでは、チップレットを互いに密接に配置する必要があります。これにより、チップの端が限定的なリソースとなります。

また、新しいRDLインターポーザー技術は、AMDの3D V-Cacheの配置に大きな影響を与える可能性があります。Zen 5世代のRyzen 7 9800X3Dのように、3D V-CacheチップレットをCCDの下に配置するソリューションは、数百本の微細なファンアウト相互接続をRDLインターポーザーを経由してルーティングする複雑さに、シリコンベースのV-Cacheチップレットの回路設計が加わることになり、非常に困難です。この複雑さを考慮すると、Zen 6では、3D V-Cacheを熱処理の課題はありながらも、再びCCDの上に配置する方式に戻る可能性が高い、とHigh Yieldは推測しています。
SerDesベースの相互接続は、遅かれ早かれ廃止される運命にあり、ファンアウト技術がその完璧な代替となります。パッケージングの複雑さとコスト増を上回るメリット、特にノートPCやサーバーでのエネルギー効率とレイテンシの削減を実現するため、ファンアウト技術の移行は必然であるとHigh Yieldは論じました。

・関連記事
IntelがAMDのCPU製造を担うべく交渉中との報道 - GIGAZINE
「Athlon 64」はなぜAMDがIntelに逆転勝利を収めるきっかけとなれたのか? - GIGAZINE
AMDがVRAM容量32GBのAI処理特化グラボ「Radeon AI PRO R9700」を発売予定、GeForce RTX 5080を超えるAI処理性能 - GIGAZINE
AMDがモンスター級CPU「Ryzen Threadripper PRO 9000 WX」シリーズの詳細を発表、Zen 5採用&最大96コア・192スレッドでIntel Xeonを打ち負かしAI性能の高さをアピール - GIGAZINE
AMDがAI向けGPU「Instinct MI350シリーズ」を発表、メモリ容量は288GBでNVIDIAのB200より高性能とアピール - GIGAZINE
AMDがRDNA 4採用グラボ「Radeon RX 9070 XT」と「Radeon RX 9070」を発表、RX 9070 XTはNVIDIAのRTX 5070 Tiより2万円安くて同等性能でレイトレ性能は前世代の2倍 - GIGAZINE
・関連コンテンツ








in 動画, ハードウェア, Posted by log1i_yk
You can read the machine translated English article What is so special about the AMD Ryzen A….