




DeepSeekが視覚情報を使用してテキスト入力を圧縮するマルチモーダルAIモデル「DeepSeek-OCR」をリリース
DeepSeekが新しいマルチモーダルAIモデル「DeepSeek-OCR」をリリースしました。「OCR」は書類のスキャンなどに用いられる光学文字認識(Optical Character Recognition)のことで、トークンを大幅に削減しつつ、大規模で複雑なドキュメントを処理できるモデルだとのことです。
GitHub - deepseek-ai/DeepSeek-OCR: Contexts Optical Compression
https://github.com/deepseek-ai/DeepSeek-OCR
DeepSeek unveils multimodal AI model that uses visual perception to compress text input | South China Morning Post
https://www.scmp.com/tech/tech-trends/article/3329707/deepseek-unveils-multimodal-ai-model-uses-visual-perception-compress-text-input
Deepseek's OCR system compresses image-based text so AI can handle much longer documents
https://the-decoder.com/deepseeks-ocr-system-compresses-image-based-text-so-ai-can-handle-much-longer-documents/
「DeepSeek-OCR」は、名前の通りOCR向けに調整された6.6GBのAIモデルで、元の情報の97%を保持しつつテキスト量を10分の1にまで圧縮することができるとのこと。システム内には、画像処理を担当する3億8000万パラメータのDeepEncoderと、5億7000万のアクティブパラメータを持つDeepSeek3B-MoE上に構築されたテキストジェネレーターの2つのコアを備えています。
DeepEncoder内では認識内容のトークンを削減して画像とテキストをリンクさせるCLIPというモデルに渡す作業が行われます。1024×1024ピクセルの画像はそのままだと4096トークンですが、DeepEncoderの処理では256トークンにまで削減されます。
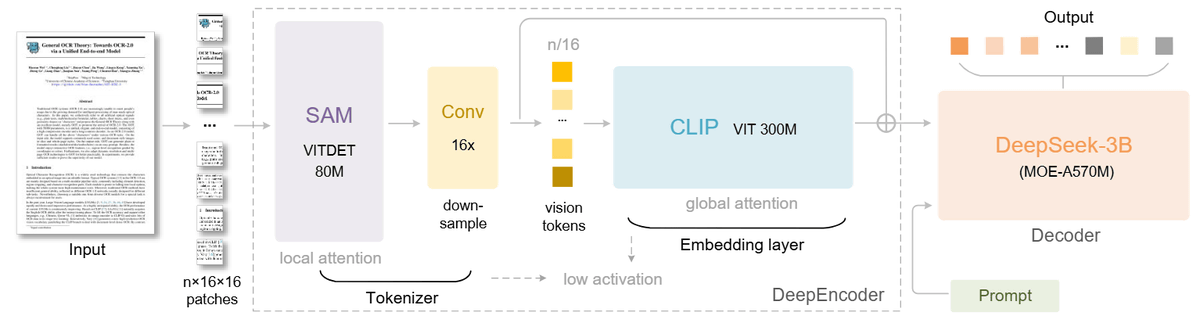
DeepSeek-OCRはさまざまな画像解像度で動作可能で、必要なビジョントークンは解像度が低い場合は64、高い場合は最大400です。同じタスクを従来のOCRシステムにやらせた場合、数千トークン必要になるとのこと。
DeepSeek-OCRは1つのNVIDIA A100 GPUの場合、1日あたり20万ページ以上の処理が可能だとのこと。1基あたり8台のA100を搭載したサーバー20基で、スループットは毎日3300万ページに上るそうです。
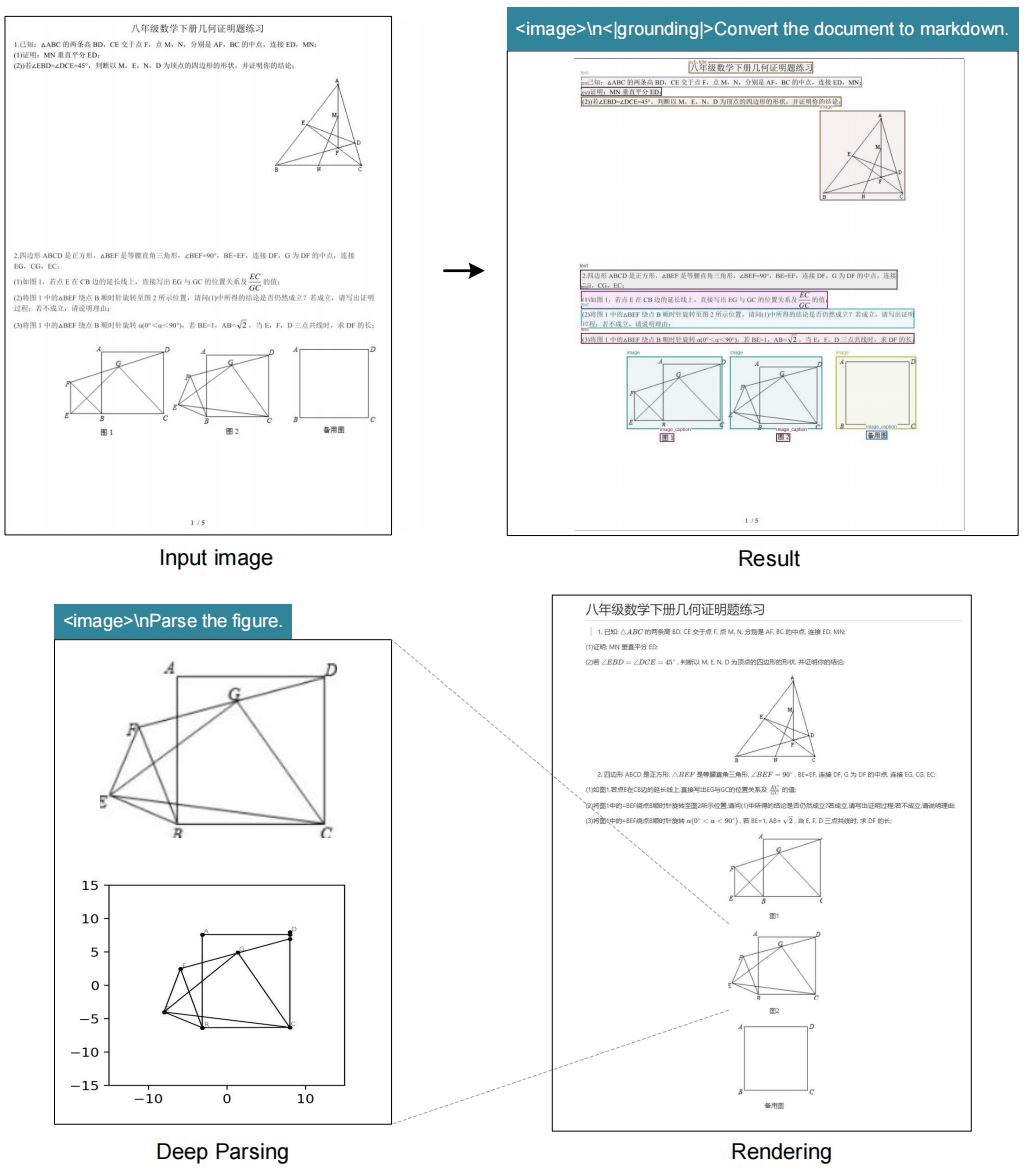
香港紙のサウスチャイナモーニングポストは、DeepSeek-OCRを使用することで、ユーザーはスケーラブルな超長文コンテキスト処理が可能になると言及。この処理では、直近のコンテキストが高解像度で保持される一方、古いコンテキストはより少ない計算リソースで処理されるので、情報保持と効率性のバランスを取った、理論上無制限のコンテキストアーキテクチャへの道を開くことを示唆するものだと述べています。
・関連記事
わずか700万パラメーターでGemini 2.5 Proを打ち負かす脅威の小型AIモデル「Tiny Recursion Model(TRM)」をSamsungの研究者が開発 - GIGAZINE
AIモデルのメモリ使用量を60~70%も削減し安価で低性能なハードウェアでも動作するようにできるオープンソースの量子化手法「SINQ」をHuaweiが発表 - GIGAZINE
中国AI企業「DeepSeek」が長大な入力でも低コストを維持できるAIモデル「DeepSeek-V3.2-Exp」を公開 - GIGAZINE
・関連コンテンツ







in AI, Posted by logc_nt
You can read the machine translated English article DeepSeek releases 'DeepSeek-OCR,' a mult….