




RedditがInternet Archiveをブロック、AI企業によるWayback Machineのアーカイブ不正利用を阻止するため

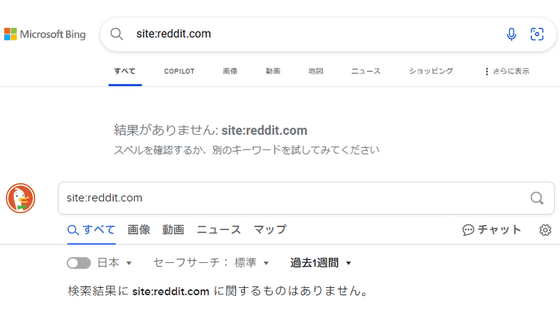
Internet Archiveはインターネット上のあらゆるコンテンツをアーカイブするWayback Machineを運営しており、ソーシャル掲示板・Reddit上のコンテンツもアーカイブ対象となっています。しかし、スクレイピングを禁止しているRedditのコンテンツを、Wayback Machineのアーカイブ経由でAIのトレーニングに利用する企業が存在することがわかり、RedditがWayback Machineによるコンテンツのアーカイブをブロックし始めたことが明らかになりました。
Reddit blocks Internet Archive to end sneaky AI scraping - Ars Technica
https://arstechnica.com/tech-policy/2025/08/reddit-blocks-internet-archive-to-end-sneaky-ai-scraping/

Reddit will block the Internet Archive | The Verge
https://www.theverge.com/news/757538/reddit-internet-archive-wayback-machine-block-limit
Wayback Machineはインターネット上のあらゆるコンテンツをアーカイブするという使命の一環として、Reddit上のページやプロフィール、コメントをアーカイブしてきました。しかし、今後はRedditのスクリーンショットのみがアーカイブされるようになるとArs Technicaは報じています。
RedditはWayback MachineからデータをスクレイピングしていたAI企業の名前を明らかにしていませんが、同社の広報担当であるティム・ラスシュミット氏は「Redditは、AI企業がプラットフォームのポリシー(Redditのポリシーを含む)に違反し、Wayback Machineからデータをスクレイピングしている事例を認識しています」とArs Technicaにコメントしています。
ラスシュミット氏はAIスクレイピングに対する防御を強化するため、Internet Archive側が講じるべき対策があると示唆し、「Internet Archiveがサイトを守り、プラットフォームのポリシー(ユーザーのプライバシーの尊重、削除されたコンテンツの削除など)を遵守できるようになるまで、私たちはRedditユーザーを守るためにInternet ArchiveによるRedditデータへのアクセスを一部制限します」と言及しています。
なお、Redditユーザーの中には既に削除されている投稿やコメントを調べるために、Wayback Machineを利用している人もいるとArs Technicaは指摘。こういったユーザーは、削除済みの投稿やコメントを閲覧するためのツールは他にも無数に存在しており、Wayback Machineはそのような目的で利用するのに適したプラットフォームではないとも言及しているそうです。

Internet ArchiveはRedditからのブロックを解除するため修正を検討しているかどうかについて、言及していません。Ars TechnicaはRedditに対して「この変更が実現すればオープンウェブリソースとしてのアーカイブの有用性にどのような影響を与えるか」と質問していますが、記事作成時点では返答は得られていないそうです。
一方、Wayback Machineのディレクターを務めるマーク・グラハム氏は、Ars Technicaに対して「Internet ArchiveはRedditと長年にわたる関係を築いており、この件について継続的な議論を続けている」と語りました。
なお、Ars Technicaは「RedditがAI企業によるWayback Machineアーカイブの活用を制限しようとしている理由は、おそらく金銭的な理由からでしょう。RedditがOpenAIやGoogleと締結したような、より有利なライセンス契約の締結を促したいと考えているのだと思います。OpenAIとの契約条件は公表されていませんが、Googleとの契約は6000万ドル(約89億円)と報じられています。今後3年間で、Redditはこうしたライセンス契約で2億ドル(約300億円)以上の利益を上げると見込まれています」と報じています。
実際、RedditはAnthropicがライセンス契約なしでReddit上のデータをAIのトレーニングに利用したとして、同社を訴えました。
RedditがAnthropicを提訴、ライセンス契約なしにサイトのデータをAIモデルの学習に使用したと主張 - GIGAZINE

by Alpha Photo
・関連記事
RedditがGoogle以外のAIがコンテンツをトレーニングに利用することを防ぐための施策を強いられているとしてMicrosoft・Anthropic・Perplexityを名指しで批判、「面倒なので本当はやりたくない」と発言 - GIGAZINE
RedditがAIモデルのトレーニングに自社コンテンツの利用を許可するライセンス契約を締結か - GIGAZINE
Redditが掲示板上の話題を検索したり要約したりできるチャットAI「Reddit Answers」を発表 - GIGAZINE
GoogleがRedditの投稿内容をAPIでリアルタイム取得してAIのトレーニングに活用へ、Redditは新規株式公開目前 - GIGAZINE
・関連コンテンツ






in AI, ネットサービス, Posted by logu_ii
You can read the machine translated English article Reddit blocks Internet Archive to stop A….