




自分のグラボでAIを動かせるかVRAM容量を基準にサクッと計算できるウェブアプリ
AIモデルを実行するには十分な容量のVRAMを備えたグラフィックボードやAI処理チップなどが必要です。無料で使えるウェブアプリ「LLM Inference: VRAM & Performance Calculator」には各種デバイスのVRAM容量やAIモデルのVRAM使用量が登録されており、「自分の環境でAIを動かせるか」や「任意のAIモデルを実行するにはどんな環境を用意すればいいのか」をサクッと計算できます。
Can You Run This LLM? VRAM Calculator (Nvidia GPU and Apple Silicon)
https://apxml.com/tools/vram-calculator
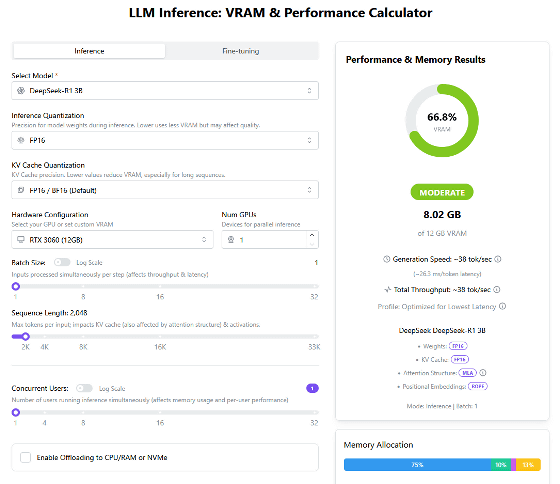
「LLM Inference: VRAM & Performance Calculator」ではAIモデルと使用デバイスを指定して、VRAM容量をもとにAIモデルを実行可能か否かを調べることができます。AIモデルは画面左上の選択欄から選び、デバイスは画面中段の選択欄から選べばOK。AIモデルとデバイスを選択すると、画面左側にAIモデルのVRAM消費量とデバイスのVRAM使用率が表示されます。初期状態だとAIモデルは「DeepSeek-R1 3B」、デバイスは「RTX 3060 (12GB)」が選択されており、VRAM使用率は66.8%で問題なく実行できることが分かります。
AIモデルを「Llama 3.1 8B」に変更。
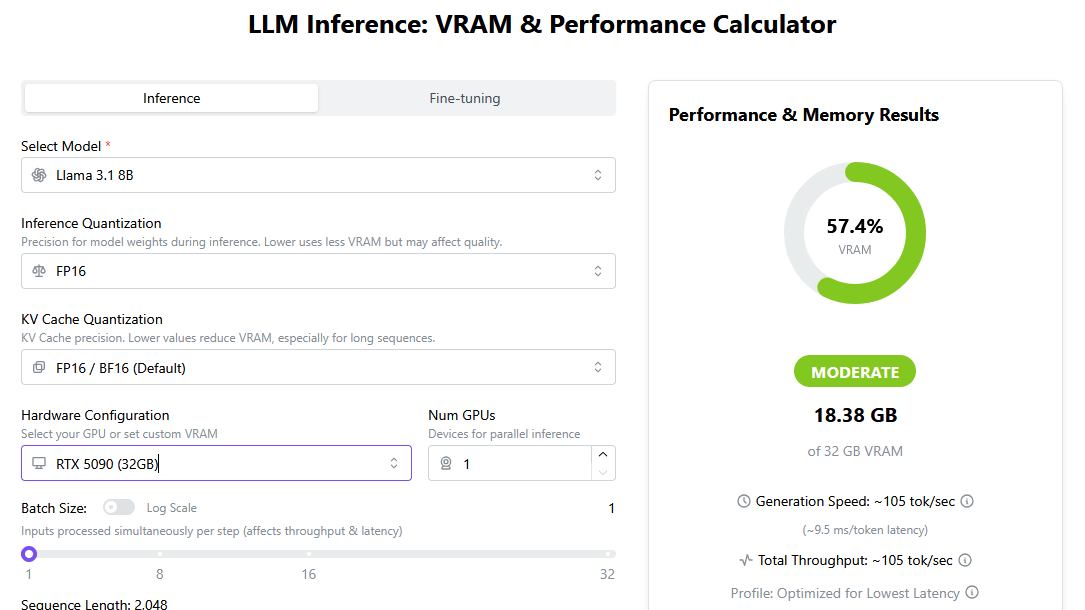
「Llama 3.1 8B」を実行するには18.38GB以上のVRAMが必要ですが、「RTX 3060 (12GB)」のVRAM容量は12GBしかないので実行できません。
デバイスを「RTX 5090 (32GB)」に変更。
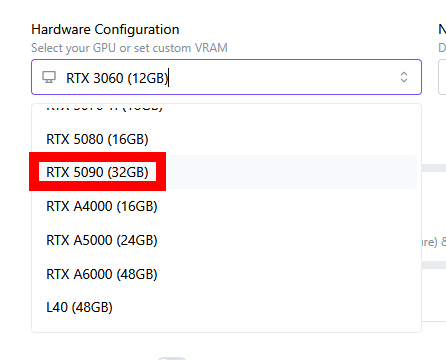
「RTX 5090 (32GB)」なら「Llama 3.1 8B」を単体で実行できます。
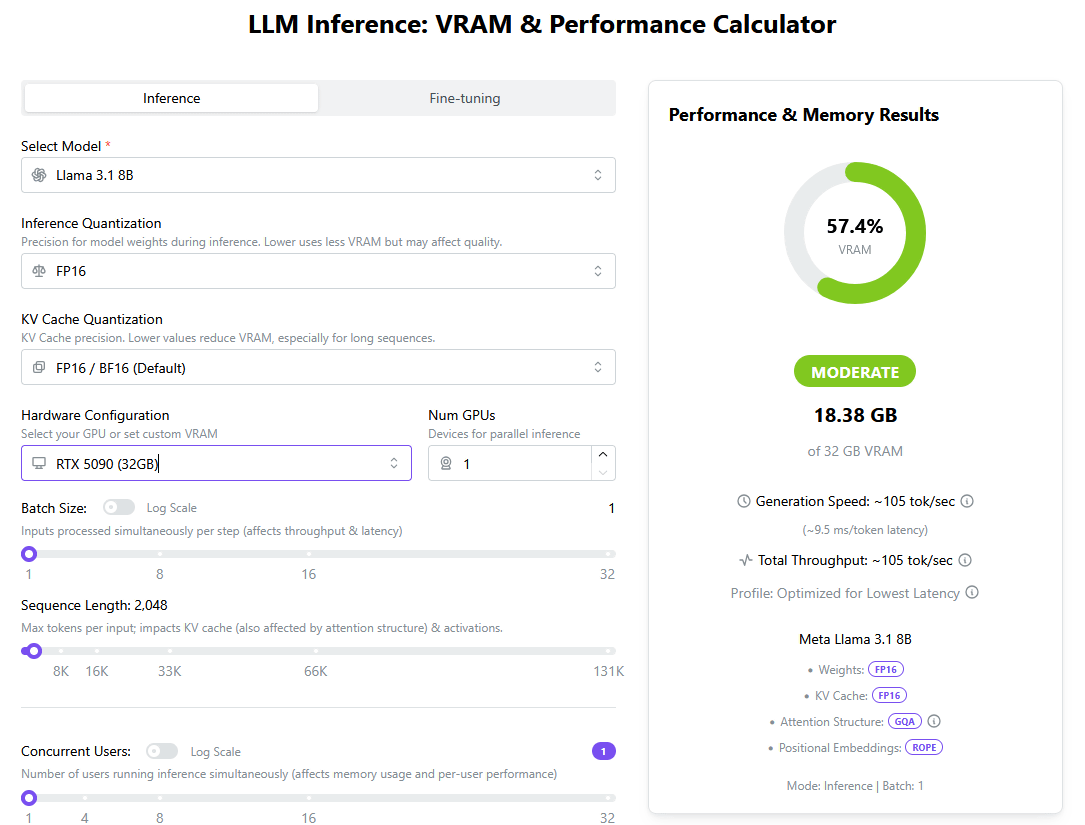
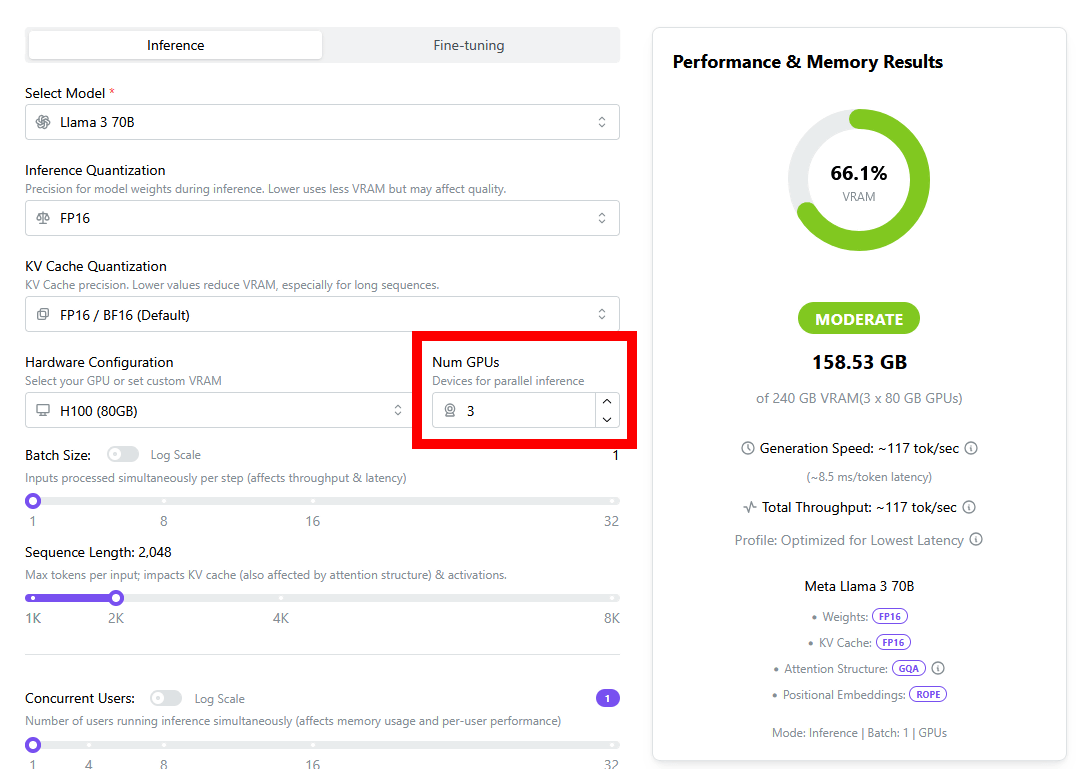
「LLM Inference: VRAM & Performance Calculator」ではH100やH200などのデータセンター向けデバイスに関するシミュレーションも可能です。AIモデルを「LLaMA 3 70B」、デバイスを「H100 (80GB)」に設定してみたところ、1台の「H100 (80GB)」では「LLaMA 3 70B」を実行できないことが分かりました。
デバイス選択欄の右隣にはデバイス台数選択欄が用意されており、デバイスを並列動作させた際の結果を算出できます。「H100 (80GB)」の台数を1台ずつ増やしたところ、3台で並列処理すれば「LLaMA 3 70B」を実行できることが分かりました。
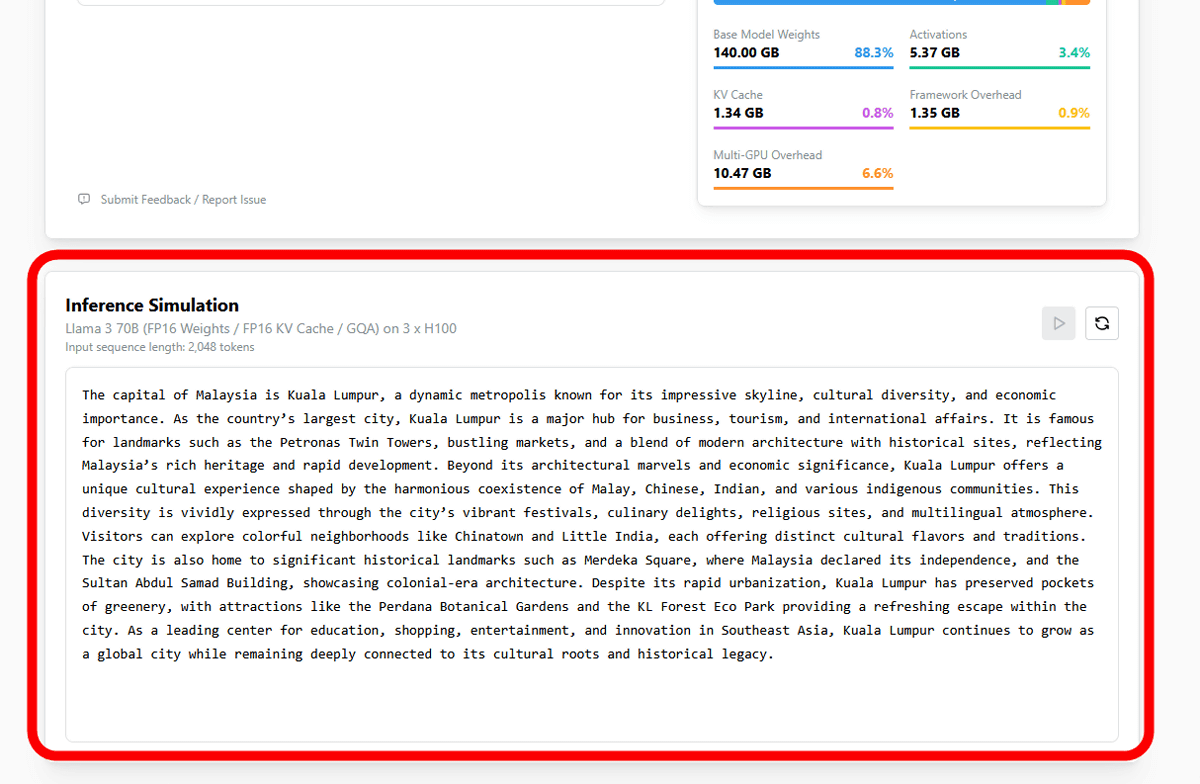
なお、「LLM Inference: VRAM & Performance Calculator」の画面下部にはAIモデルのトークン処理速度デモも用意されており、選択したAIモデルとデバイスの組み合わせでのテキスト出力速度を疑似的に体感できます。
・関連記事
AMDがVRAM容量32GBのAI処理特化グラボ「Radeon AI PRO R9700」を発売予定、GeForce RTX 5080を超えるAI処理性能 - GIGAZINE
VRAM容量の少ない安めのグラボでも画像生成AI「FLUX.1 Kontext [dev]」を動かせる省メモリ高速版をNVIDIAが開発、VRAM使用量を24GBから7GBまで削減し2.1倍高速動作 - GIGAZINE
画像生成AI「Stable Diffusion 3.5 Large」の18GBを超えるVRAM使用量を40%も削減して11GBにする新技術をNVIDIAが公開 - GIGAZINE
NVIDIAがデスクトップPCやノートPCに搭載できるAI特化GPU「RTX PRO Blackwellシリーズ」を発表、デスクトップ向け最上位は96GBのVRAMを搭載 - GIGAZINE
GeForce RTX 5090より10倍高性能なGPU「Zeus」が登場、VRAMを1カード当たり384GBまで増設可能でパストレーシングやHPCに特化 - GIGAZINE
・関連コンテンツ





in AI, ハードウェア, ソフトウェア, ウェブアプリ, Posted by log1o_hf
You can read the machine translated English article A web app that can quickly calculate whe….